论文Express | 自然语言十项全能:转化为问答的多任务学习
大数据文摘出品
编译:halcyon
NLP领域的十项全能算法来了。
Salesforce最新论文提出了一个可处理多项自然语言处理的通用模型:decaNLP,处理机器翻译、文本分类等NLP任务统统不在话下!

在大数据文摘后台回复“问答”可下载本论文~
以下是论文精华内容:
深度学习提升了许多单个自然语言处理任务的性能。但是,一般的NLP模型集中于单个度量、数据集和任务,因此不能形成典范。我们引进了自然语言十项全能(decaNLP)的概念,一个跨越10个任务的挑战:问答,机器翻译,总结,自然语言推理,情感分析,语义角色标注,关系抽取,目标驱动对话,语义解析,常识性代词消解。
我们将所有的问题转化为一段文本的问答。进一步的,我们提出了一个新的多任务问答网络(MQAN),它可以在没有任何特定任务的模块或参数的情况下,共同学习decaNLP中的所有任务。MQAN显示了机器翻译和命名实体识别(NER)的迁移学习的改进,情感分析和自然语言推理的领域适应,以及文本分类的零样本能力。
我们证明了MQAN的多指针编解码器是这个成功的关键,并且通过相反训练策略(anti-curriculum training strategy)进一步提高了性能。尽管MQAN是为decaNLP设计的,但它也实现了在单任务设置中的WikiSQL语义解析任务的最新结果。我们还发布了获取和处理数据,训练和评估模型的代码,以及重现了decaNLP的所有实验。
代码链接:
https://github.com/salesforce/decaNLP
介绍
我们介绍了decaNLP,以探索推广到许多不同类型的NLP任务的模型。decaNLP鼓励用单一模型同时优化十项任务:问答、机器翻译、文档总结、语义解析、情感分析、自然语言推理、语义角色标注、关系抽取、目标驱动对话、代词消解。
MQAN是针对decaNLP设计的,它利用了一种新的双关联注意力和多指针发生器解码器在decaNLP中对所有任务进行多任务处理。我们的研究结果表明,用正确的相反训练策略对所有任务的MQAN进行联合训练,可以达到与10个独立的MQANs单独训练相同的性能。
在decaNLP上接受过训练的MQAN在机器翻译和命名实体识别的迁移学习、情感分析和自然语言推理的领域适应以及文本分类的零样本能力方面都有改进。虽然没有为任何一个任务明确地设计,但事实证明,MQAN在单任务设置中也是一个强大的模型,在decaNLP的语义解析上实现了最先进的结果。
我们发布了代码,用于获取和预处理数据集、训练和评估模型,以及通过基于decaScore的十项全能分数(decaScore)的排行榜跟踪进度。我们希望这些资源的结合能够促进多任务学习、迁移学习、通用嵌入和编码器、架构搜索、零样本学习、通用问答、元学习等NLP相关领域的研究。
任务和指标
decaNLP包含了10个公开的可获得的数据集,示例被转换为(问题、上下文、回答)三元组,如图1所示。

图1. decaNLP数据集的概览:其中包含了每一个decaNLP任务的例子。它们展示了如何预先处理数据集,使其成为问答问题。红色的回答词是通过指向上下文生成的,绿色的是从问题中生成的,蓝色的是输出词汇表上的分类器生成的。
问答(QA)。QA模型接收一个问题和一个上下文,其中包含输出所需答案所需的信息。在这个任务中我们使用斯坦福问答数据集(SQuAD)。
上下文是从英语维基百科中摘取的段落,回答是从上下文中复制的单词序列。SQuAD使用一种标准化的F1指标,剔除冠词和标点符号。
机器翻译。机器翻译模型以源语言作为输入文档,输出为翻译好的目标语言。我们使用2016年为国际口语翻译研讨会(IWSLT)准备的英语到德语训练数据。例子来自转录的TED演讲,以对话的形式涵盖了各种各样的话题。我们在2013年和2014年的测试集上分别以语料级别的BLEU评分作为验证集和测试集进行评估。
摘要。摘要模型接收一个文档并输出该文档的摘要。关于摘要,最近最重要的进展是CNN/DailyMail(CNN/DM)语料库转化为一个摘要数据集。我们在decaNLP中包含这个数据集的非匿名版本。平均而言,这些示例包含了decaNLP中最长的文档,并强迫模型通过生成新的抽象的单词序列来平衡从上下文提取的内容。CNN/DM使用ROUGE-1、ROUGE-2和ROUGE-L分数。我们把这三个分数取平均,计算出一个整体的ROUGE分数。
自然语言推理。自然语言推理(NLI)模型接受两个输入句子:一个前提和一个假设。模型必须将两者之间的推理关系归类为包含关系、中立关系或矛盾关系。我们使用多流派的自然语言推理语料库(MNLI),提供来自多个领域的训练示例(转录语音、通俗小说、政府报告),以及来自可见和不可见领域的测试对。MNLI使用精确匹配(EM)得分。
情感分析。训练情感分析模型的目的是,根据输入的文本对文本表达的情感进行分类。斯坦福情感树库(SST),由一些带有相应情绪(积极的,中性的,消极)的电影评论组成。我们使用未解析的二进制版本。SST也使用EM分数。
语义角色标注(SRL)。SRL模型被给定一个句子和谓词(通常是一个动词),然后必须确定“谁对谁做了什么”、“什么时候”、“在哪里”。我们使用一个SRL数据集,将任务视为一种问答,也叫QA-SRL。这个数据集涵盖了新闻和维基百科领域,但我们只使用后者,以确保decaNLP的所有数据都可以免费下载。我们用SQuAD使用的nF1指标来评估QA-SRL。
关系抽取。关系抽取系统接收到一段非结构化的文本以及要从该文本中提取的关系。在这种情况下,模型需要先识别实体间的语义关系,再判断是不是属于目标种类。与SRL一样,我们使用一个数据集QA-ZRE,将关系映射到一组问题,这样就可以将关系抽取处理为问答形式。
对数据集的评估是为了对新的关系进行零样本性能的测量——数据集是被分割的,这样在测试时看到的关系在训练时是看不到的。这种零样本关系的提取,把它转化成问答,使它有可能推广到新的关系。QA-ZRE使用一个预料级别的F1指标(cF1)来准确地解释无法回答的问题。这个F1指标定义精度为真正的正计数除以系统返回非空答案的次数,召回率为真正的正计数除以有答案的实例数。
目标驱动对话。对话状态跟踪是目标驱动对话系统的重要组成部分。基于用户的说话、已经采取的行动和会话历史,对话状态跟踪器会跟踪用户对对话系统有哪些预定义目标,以及用户在系统和用户交互时发出哪些请求。
我们使用了WOZ餐厅预订任务的数据集,它提供了一个预定义的食物、日期、时间、地址和其他信息,可以帮助代理商为客户预订。WOZ基于回合的对话状态(dsEM)对客户的目标进行评估。
语义解析。SQL查询生成与语义解析相关。基于WikiSQL数据集的模型将自然语言问题转化成结构化的SQL查询,以便用户可以使用自然语言与数据库进行交互。WikiSQL通过逻辑形式精确匹配(lfEM)进行评估,以确保模型不会从错误生成的查询中获得正确的答案。
指代消解。我们的最后一个任务是基于Winograd模式,它要求代词消解:“Joan made sure to thank Susan for the help she had [given/received]. Who had [given/received] help? Susan or Joan?"。我们从Winograd模式挑战中的例子开始,并对它们进行了修改,以确保答案是来自上下文的单个单词。这个修改后的Winograd模式挑战(MWSC)确保了分数不会因上下文、问题和答案之间的措辞或不一致而被夸大或缩小。我们用EM值来评估。
十项全能分数(decaScore)。在decaNLP上竞争的模型将使用每个特定于任务的指标的相加组合进行评估。所有指标都在0到100之间,因此十项任务的decaScore自然会在0到1000之间。使用一个相加组合可以避免因衡量不同的指标而产生的问题。所有指标都不区分大小写。

表1 decaNLP中公开可用的基准数据集以及用于decoSocre的评估指标。
多任务问答网络
因为每一项任务都被定义为问答并且共同训练,所以我们称我们的模型为多任务问答网络(MQAN)。每个示例由上下文、问题和回答组成,如图1所示。
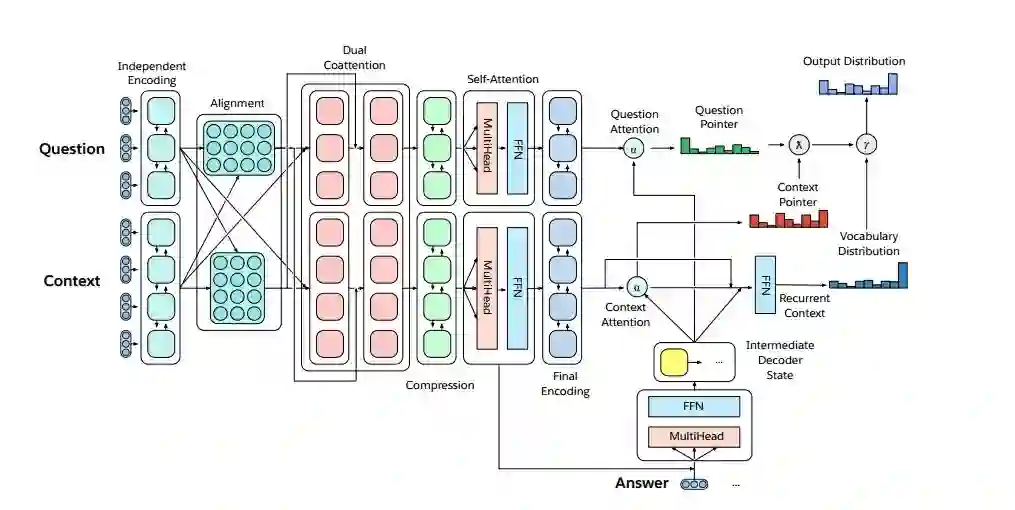
图2. MQAN模型概览:它输入一个问题和上下文文档,然后将它们用BiLSTM进行编码,使用dual coattention对两个序列的条件进行表示,用另两个BiLSTMs压缩所有的这些信息,用self-attention来收集这种长距离依赖,然后使用两个BiLSTMs的问题和上下文环境进行最终的表示。多指针生成器解码器使用对问题、上下文和先前输出的词次的关注来决定是从问题中复制、从上下文中复制还是从有限的词汇表中生成。
在训练过程中,MQAN将三个序列作为输入:具有l个词次的文本c,具有m个词次的问题q,具有n个词次的回答a。它们都用矩阵表示,矩阵的第i列与d_emb维的嵌入向量一致,作为序列中的第i个词次:
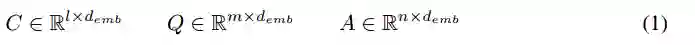
编码器将这些矩阵作为输入,使用重复的、coattentive的和self-attentive层的深层堆栈来产生最终的表示。设计作为上下文和问题的C_fin和Q_fin,来捕捉局部和全局的相互依赖。
回答表示
在训练过程中,解码器开始把回答潜入向量投影到d维的空间中:

接下来是一个self-attentive层,它在编码器中有一个相应的self-attentive层。因为它既没有递归,又没有卷积,我们给A_poj添加位置编码PE,其中PE为:
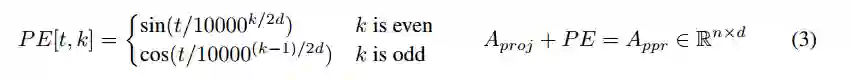
多头解码机制
我们使用self-attentive,这样解码器就可以知道以前的输出(或者在没有先前输出的情况下,可以使用一个特殊的初始化词次),并且可以关注上下文来准备下一个输出。
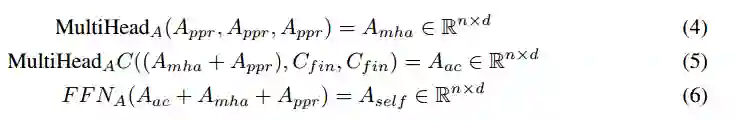
中间解码器状态
接下来,我们将使用标准的LSTM来获取时间步t时的循环上下文状态c_t。首先,让LSTM通过使用先前的回答词A_self和循环上下文状态产生一个中间状态h_t:
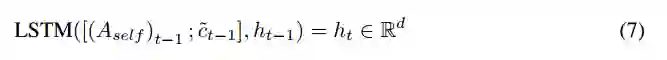
上下文和问题机制
这个中间状态被用于获得注意力权重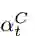
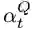
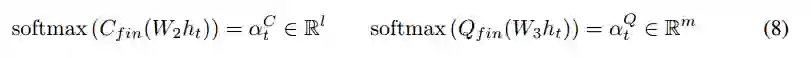
循环上下文状态
上下文表示与这些权重相结合,通过tanh激活的前馈网络输入,形成重复的上下文状态和问题状态:
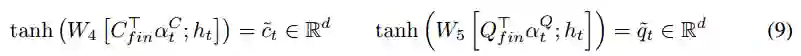
多指针生成器
我们的模型必须能够生成不在上下文或问题中的词次。我们让它访问v个额外的词汇词次。分别得到在上下文中、问题和这个外部词汇表中词次的分布:
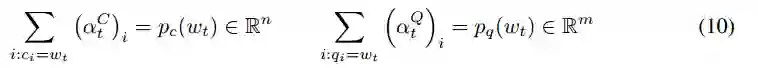
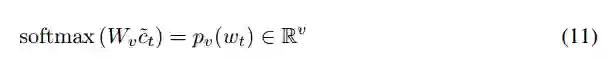
这些分布通过将缺失的条目设置为0以使每个分布都在R_l+m+v中来扩展,以覆盖上下文、问题和外部词汇表中的词次的联合。两个标量开关调节每个分布在决定最终输出分布的重要性。
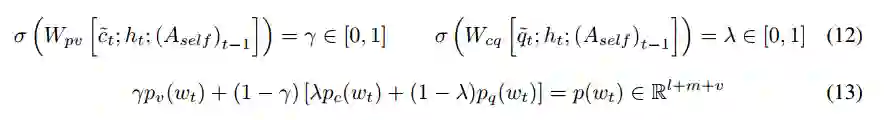
我们在整个时间步中使用一个词次级别的负对数似然损失:
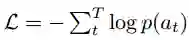
实验和分析
基线和MQAN
表2 decaNLP基线的验证指标:单任务和多任务实验对不同模型和训练策略的验证结果。
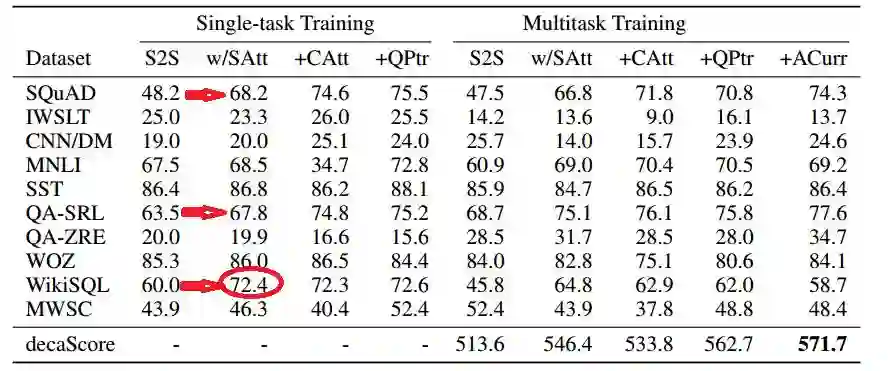
在我们的框架中,训练示例是(问题,上下文,回答)三元素。我们第一个基线是指针生成器S2S模型,S2S模型只接受一个输入序列,因此我们将该模型的上下文和问题连接起来。
在表格2中,验证指标显示在SQuAD上表现得并不是很好,在WikiSQL上,它相比于之前的S2S基线包含了更高的分数,但是相比于MQAN(+Qptr)和其他基线则更低。
使用self-attentive编码器和解码器层扩展S2S模型(w/SAtt),增加了模型集成来自上下文和问题的信息的能力。这让SQuAD上的表现性能提高了20个nF1,QA-SRL上的表现性能提高4个nF1,WikiSQL上的表现性能提高了12个LFEM。对于WikiSQL,这个模型在没有使用结构化方法的情况下,几乎达到了先前的最先进的验证结果72.4%。(见表格中红色箭头标注)
接下来,我们将研究如何将上下文和问题分割为两个输入序列,并使用coattentive扩展S2S模型(+CAtt)。SQuAD和QA-SRL上的表现增加了5个nF1。不幸的是,这不能改进其他任务,并且会严重影响MNLI和MWSC上的性能。
对于这两个任务,可以直接从问题中复制答案。由于两个S2S基线都将问题连接到上下文,所以指针生成器机制能够直接从问题中复制。当上下文和问题被分成两个不同的输入时,模型就失去了这种能力。
为了解决这个问题,我们在前面的基线上添加了一个问题指针(+QPtr),这提高了MNLI和MWSC在先前基线之上的性能。它还将阵容性能提高到75.5 nF1,这使它成为了在SQuAD数据集上训练的最高效的问答模型。
最后一个模型在WikiSQL上达到了一个新的最先进的测试结果,达到了72.4%的lfEM和80.4%的数据库执行精度,超过了之前最先进的71.7%和78%的水平。
在多任务设置中,我们看到了类似的结果,但我们也注意到一些额外的显著特性。QA-ZRE的性能比最高的单任务模型提高了11个F1点,这支持了多任务学习可以更好地推广零样本学习的假设。
需要大量使用外部词汇表的任务的性能从S2S基线下降了50%以上,直到问题指针添加到模型中。除了参与的上下文之外,这个问题指针还使用参与的问题,它允许来自问题的信息直接流到解码器中。我们假设更直接地访问这个问题使模型更容易决定何时生成输出词次比复制更合适。

图3 对MQAN如何选择输出回答词的分析。当p(generation)最高时,MQAN对外部词汇的权重最大。当p(context)最高时,MQAN将最大的权重放在上下文上的指针分布上。当p(question)最高时,MQAN将最大的权重放在问题的指针分布上
分析
多指针生成器和和任务识别。在每个步骤中,MQAN在三个选项中进行选择:从词汇表生成、指向问题和指向上下文。虽然模型没有接受过对这些决策进行明确监督的培训,但它学会了在这三个选项之间进行切换。图3显示了最终模型选择每个选项的频率。
对于SQuAD、QA-SRL和WikiSQL,模型大部分是从上下文复制的。这很直观,因为正确回答来自这些数据集的问题所需的所有词次都包含在上下文中。这个模型通常也会复制CNN/DM的上下文,因为答案摘要主要是由上下文中的词汇组成的,而很少有词汇是在上下文之外产生的。
对于SST、MNLI和MWSC,模型更喜欢问题指针,因为问题包含可接受类的词次。因为模型学习用这种方法来使用问题指针,所以它可以做零样本分类。对于IWSLT和WOZ,该模型更喜欢从词汇表中生成,因为德语词汇和对话状态字段很少出现在上下文中。该模型还避免了对QA-ZRE的复制。
对新任务的适应性。在decaNLP上训练的MQAN学会了泛化,而不是局限于特定领域,同时也学习表示,使学习完全新的任务更容易。对于两项新任务(英语对捷克语翻译和命名实体识别),在decaNLP上完成的一个MQAN训练需要更少的迭代,并且比从随机初始化(图4)获得更好的最终性能(图4)。
对文本分类的零样本域适应性。因为MNLI包含在decaNLP中,所以它是能够适应相关的SNLI。在decaNLP上对MQAN进行微调,达到了87%的精确匹配分数,这比目前最好的随机初始化的训练增加了2个点。更值得注意的是,在没有对SNLI进行任何微调的情况下,在decaNLP上接受过训练的MQAN仍然能够获得62%的精确匹配分数。
这些结果表明,在decaNLP上训练的模型有潜力同时对多个任务的域外上下文和问题进行模拟推广,甚至可以适应文本分类的不可见类。这种输入和输出空间中的零样本域适应表明,decaNLP中的任务宽度鼓励了泛化,超出了对单个任务的训练所能达到的范围。
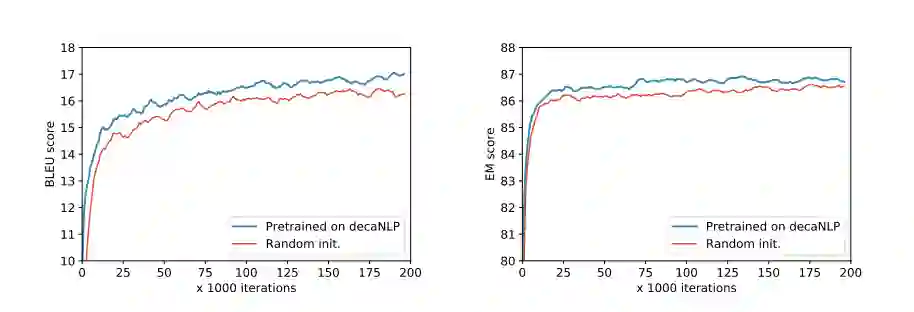
图4. 在decaNLP上预先训练的MQAN在适应新环境时和学习新任务时优于随机初始化。左:在一个新的语言对上训练,英语-捷克语,右:在一个新任务-命名实体识别(NER)上训练。
在大数据文摘后台回复“问答”可下载本论文~
【今日机器学习概念】
Have a Great Definition







