
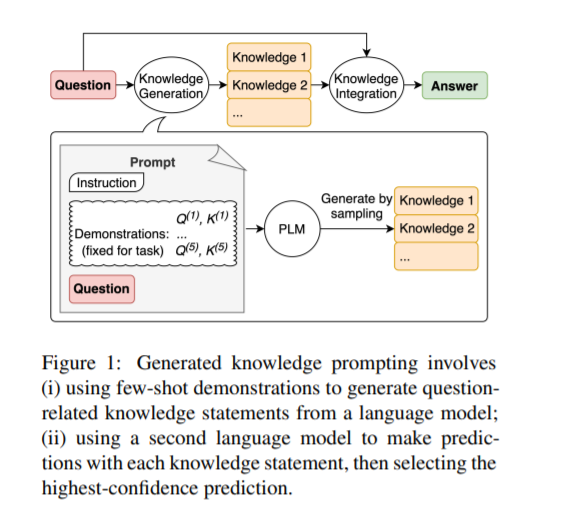
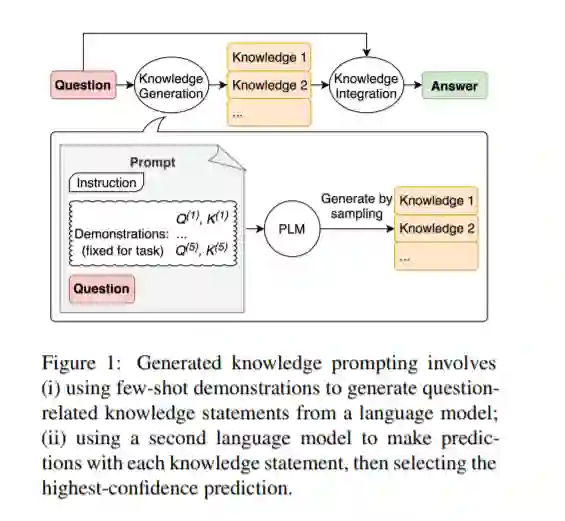
在保持训练前序列模型的灵活性的同时,整合外部知识是否有利于常识推理仍然是一个开放的问题。为了研究这个问题,我们开发了生成的知识提示,它包括从语言模型中生成知识,然后在回答问题时提供知识作为额外的输入。我们的方法不需要任务特定的监督来进行知识整合,也不需要访问结构化知识库,但它提高了大规模、最先进的模型在四个常识推理任务上的性能,在数值常识(NumerSense)、一般常识(CommonsenseQA 2.0)、以及科学常识(QASC)基准。生成的知识提示突出了大规模语言模型作为外部知识的灵活来源,以提高常识推理。我们的代码可以在github.com/anonymous_repo上找到。
成为VIP会员查看完整内容
相关内容
专知会员服务
54+阅读 · 2019年12月27日
Arxiv
20+阅读 · 2021年5月27日
Arxiv
27+阅读 · 2021年1月21日


相关VIP内容
专知会员服务
54+阅读 · 2019年12月27日
相关资讯
相关论文
Arxiv
20+阅读 · 2021年5月27日
Arxiv
27+阅读 · 2021年1月21日