![]()
©作者 | 张义策
单位 | 哈尔滨工业大学(深圳)
研究方向 | 自然语言处理
![]()
论文标题:
Relational World Knowledge Representation in Contextual Language Models: A Review
EMNLP 2021
https://arxiv.org/pdf/2104.05837.pdf
这是 EMNLP 2021 上的一篇综述,作者来自美国密西根大学。
以关系三元组为核心的知识库是目前关系性知识的典型表达方法,其中关系三元组由 头实体、关系和尾实体构成,如 (
玛丽居里
,
出生于,华沙)。
-
以
知识库
的
方式保存关系性知识的优点是精确、可解释性强;
-
但其缺点也是明显的,需要定义复杂的实体和关系类型,灵活性不够,不够全面。
而很多工作也表明,语言模型携带了一些关系性的知识。
Language Models as Knowledge Bases?
[1]
![]()
回答以上两方面问题便是这篇文章的主要内容了,其中问题 2 中注入关系性知识又分为 实体级别的知识 和 关系级别的知识。下面本文依次对这三部分内容进行简要叙述。
读者不禁会思考:为什么通过 language modeling 训练的语言模型中会存在关系性的知识呢?文章给出了答案:这是因为维基百科中的很多文本都是关系性知识的陈述,而维基百科又是典型的预训练语料。
正如前面提到的,推理语言模型中知识的典型方法就是完形填空 (cloze prompting),即将带空位的自然语言陈述输入到 BERT 中,然后让模型预测空位中的单词。可以看到,在该方法中,如何将关系性知识转化为陈述句便是关键了。
人工模板:典型的方法便是针对某个关系,人工撰写一个模板,如“出生于”对应的模板为“[marie curie] was born in [warsaw]”;“职业”对应的模板为“[obama] worked as a [president]”。
自动模板:人工模板的劣势是显然的,耗时耗力、也不一定好使。于是很多工作研究了如何自动产生模板。以Jiang et al(2020) [2] 为例,对于某个关系实例 (x, r, y),它首先识别维基百科中同时包含 x 和 y 的句子,然后将句子中 x 和 y 去掉,变成模板。这些针对关系 r 的模板通过重构(如翻译两次),生成更多模板。然后从这些候选模板中,选择性能最好的模板。下面是一些模板的例子。当然,自动模板的方法中也有不同流派,这里不展开了。
![]()
除了完形填空之外,句子打分(statement scoring)也是一种典型的抽取知识方法。我想该方法应该是主要是面向生成模型的。
![]()
entity-level masking
是最简单直接的方法,即在对句子进行 masking 的时候,将实体作为一个整体进而选择 mask 或者不 mask。此外,也可以增加实体对应的 mask 概率,让模型更关注实体信息。有工作 [3][4] 称之为 Salient Span Masking。
![]()
将实体视作 token
当然我们也可以将实体整体作为一个 token。在 E-BERT [5] 中,作者将实体对应的 token 合并为一个 token,如下图中的 Jean_Marais;作者发现将合并后的 token 和原本的 tokens 一起保留下来 (E-BERT-concat),效果会比较好。但是该方法带来的一个明显问题是词表的规模大大增加了(30k->6m)。
![]()
上面两种方法可以说都是在输入层面对 mask language modeling 进行改动。也有研究者通过增加其他训练目标的方式,在预训练阶段注入实体级别的知识,典型的两种为:
entity replacement detection [6]:
将句子中的实体替换为同类型的其他实体,然后让模型预测替换是否存在。这有些类似 ELECTRA [7] 中的 replaced token detection。
entity linking[8]:
实体链接是指将文本中的字符映射到知识库对应的实体上。将该任务加入到预训练过程中,相应的标注便是来源于百科文本中指向其他词条的链接。
![]()
entities as embeddings 以 transE [9] 为代表的知识嵌入(knowledge embeddings)可以为知识图谱中的实体的得到一个表示。一些工作将这些实体表示和 BERT 中的 token 表示结合在一起。
-
align & fusion:
Peters et al (2019)[10] 通过 word-to-entity attention,融合实体表示和 BERT 输出 token 表示。
-
early fusion:
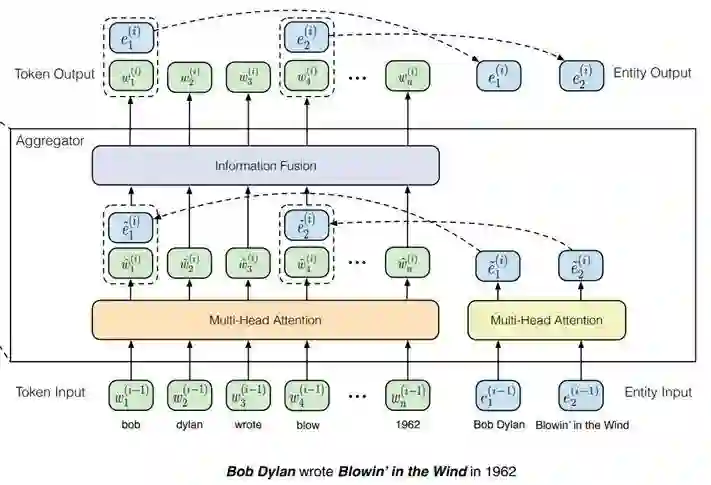
在 BERT 内部,进行句子的编码时,显式地引入 entity embeddings。输入的实体表示可以来源模型外部 [11],也可以是在模型中学习 [12]。以 ERNIE-THU [11] 为例,如下图,除了建模原本句子内部 token 之间交互外,还建模 entity 与对应的 token 的交互,以及 entity 之间的交互。
![]()
![]()
这部分内容可大致分为两类方法:
1. relations as templated assetions:
将关系三元组转化为陈述句,作为预训练的文本。将关系三元组转化为文本,和前面提到的完形填空有些类似,具体方法不展开。
2. relations as pretraining objective:
引入一个或多个额外的训练目标。这个思路下感觉还是有很大做的空间。接下来,本文选择下面三个工作进行介绍:
Matching the Blanks [13]
ERICA [14]
KEPLER [15]
Matching the Blanks
这是 2019 年的工作,算 BERT+relation 的工作中比较早期了。其思路是具有相同关系的句子表示应当相似。考虑到大规模的关系标注语料的缺乏,因此将“具有相同关系”这一限制放松为 “包含相同实体对”。进一步,考虑到实体对本身可能泄露答案,因此将句子中实体对 mask 掉。
ERICA
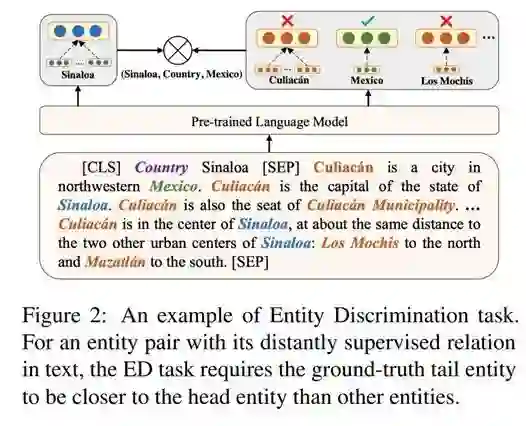
与 Matching the Blanks 类似,从“具有相同关系的句子表示应当相似”这个出发点训练模型。而关系标签则是通过远程监督获得的。该任务被称为关系鉴别任务。此外,这个工作还引入了实体鉴别任务,具体来说,输入头实体+关系以及一段包含尾实体的文本,让模型找到尾实体。下图给出了一个例子。
KEPLER
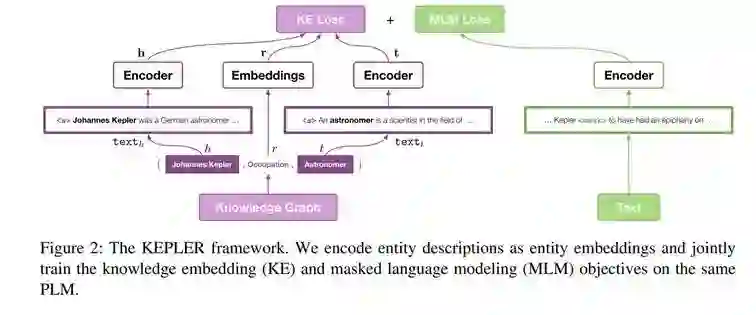
与 ERICA 一样,都是 21 年发布的工作。相比之外,KEPLER 看来更加科学一点(个人观点)。TransE 的目标是头实体的表示 h,尾实体的表示t,与关系的表示 r,满足 h+t=r。在原本的 TransE 的工作中,实体的表示都是没有结合上下文的;而在 KEPLER 中,则是结合了上下文。在 KEPLER 中,知识嵌入和 language modeling,是共享编码器,同时训练的。不得不说,这个框架看起来简洁有力。
[1] Petroni, Fabio, et al. "Language models as knowledge bases?." arXiv preprint arXiv:1909.01066 (2019).
[2] Jiang, Zhengbao, et al. "How can we know what language models know?." Transactions of the Association for Computational Linguistics 8 (2020): 423-438.
[3] Guu, Kelvin, et al. "Retrieval augmented language model pre-training.“ ICML 2020.
[4] Roberts, Adam, et al. "How Much Knowledge Can You Pack Into the Parameters of a Language Model?." EMNLP 2020.
[5] Poerner, Nina, Ulli Waltinger, and Hinrich Schütze. "E-BERT: Efficient-yet-effective entity embeddings for BERT." EMNLP 2020.
[6] Xiong, Wenhan, et al. "Pretrained encyclopedia: Weakly supervised knowledge-pretrained language model.“, ICLR 2020.
[7] Clark, Kevin, et al. "Electra: Pre-training text encoders as discriminators rather than generators." arXiv preprint arXiv:2003.10555 (2020).
[8] Ling, Jeffrey, et al. "Learning cross-context entity representations from text." ICLR 2020.
[9] Bordes, Antoine, et al. "Translating embeddings for modeling multi-relational data." Advances in neural information processing systems 26 (2013).
[10] Peters, Matthew E., et al. "Knowledge enhanced contextual word representations." EMNLP 2019.
[11] Zhang, Zhengyan, et al. "ERNIE: Enhanced language representation with informative entities." ACL 2019.
[12] Févry, Thibault, et al. "Entities as experts: Sparse memory access with entity supervision." EMNLP 2020.
[13] Soares, Livio Baldini, et al. "Matching the Blanks: Distributional Similarity for Relation Learning." ACL 2019.
[14] Qin, Yujia, et al. "ERICA: improving entity and relation understanding for pre-trained language models via contrastive learning." ACL 2021.
[1] 5Wang, Xiaozhi, et al. "KEPLER: A unified model for knowledge embedding and pre-trained language representation." TACL 2021.
感谢 TCCI 天桥脑科学研究院对于 PaperWeekly 的支持。TCCI 关注大脑探知、大脑功能和大脑健康。
![]()
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿
![]()
△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
![]()