论文浅尝 | 通过知识到文本的转换进行知识增强的常识问答

笔记整理:陈卓,浙江大学在读博士,主要研究方向为低资源学习和知识图谱
论文链接:https://www.aaai.org/AAAI21Papers/AAAI-10252.BianN.pdf
发表会议:AAAI 2021
动机
文章提出了对于未来CQA(Commonsense QA)问题的三个见解,首先其对于文本应该是比较敏感的,需要对于不同的知识选择不同的文本,然后要能够利用上异构的知识信息,同时它要使用到具有丰富常识知识的语言模型。此外,本文提出了3个未来的发展方向,然后在文章里提出了4个见解和挑战:
1.基于GNN的网络,很难把这些所有的有效的外部知识给利用上。2.这些外部知识应该用一种比较简单的方法注入到不同的模型里面,并且这种方法不应该是一些模型特定的方法,所以作者就后面提出了把知识转化成文本的形式。3.知识主要是三元组的形式存在,但是问题和答案是文本的形式,这存在一种模式上的一个gap。4.一个知识库里面有很多个这样的三元组,但是往往只有数个是跟某一个问题相关,这是一种稀疏性问题。

模型
模型分为三大步骤,其中第一步是把知识进行一个检索,第三步是进行一个MRC的阅读理解的任务,这两个其实比较简单。中间这个步骤就是它的创新点——如何把一个 QA的任务转化成一个阅读理解任务。
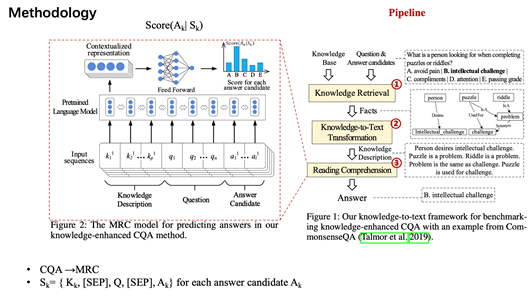
具体来说,第一步是根据一个问题和对应的候选答案,作者到一个知识库里面检索出来这样一个子图,第二步是把这个子图变成了一串知识的描述的文本,然后根据这个描述的文本以及这个问题和答案拼接到一起,最后放到这样一个MRC的预训练语言模型中,最后得到它的一个答案的概率分布,怎么预测到正确的答案。
第二步用了三种形式来实现这样一个fact到text的转换。分别是
(1)基于模板的方法,基于翻译的方法和基于检索的方法。其中基于模板大家应该也都能想到,就是说我把每一个关系定义一个模板,比如说像这个例子举的这样。然后如果是有多个三元组的话,那就把这些三人组的模板转化成之后的短句拼接成一个长句,并作为它这一个子图的知识表示。
(2)基于翻译的方法,作者觉得第一种方法最后得到的这样一段话可能是逻辑上不通的,因为每一个短句之间都独立也没有什么联系,而作者第二种方法就是把这样一一些短句用一种类似于机器翻译的方法,让它变得更加的多样化,然后更加的流畅,类似于进行了这样一个转化。
(3)基于搜索的方法,作者觉得不管是第一种还是第二种方法,它都存在语句不在真实世界中出现过的问题,所以用了一种基于检索的方法,在真实的维基百科语料中,基于这些出现的这些实体进行文本段落检索,最后把检验得到的语句作为知识的表示形式,然后它可以用到一些具体方法,这里不展开大家感兴趣的可以去看原文。

实验
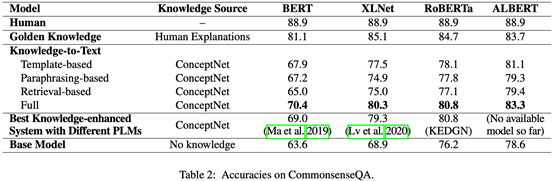
作者在不同预训练模型的基础上都进行了实验,因为因为CQA领域里面很多模型是基于不同的预训练模型实现的,分别达到了各自的SOTA,作者把作者们的方法加上作者这样一个knowledge-to-text的方法之后,转换成MRC任务,都实现了一个少量的提升。同时它也构造了一个golden knowledge,人工的把每个知识对应到一个ground truth knowledge上面,来进行一个上界的判定,看这样的方法它能够达到的上界是多少。可以看到跟人类的效果比起来已经接近了。
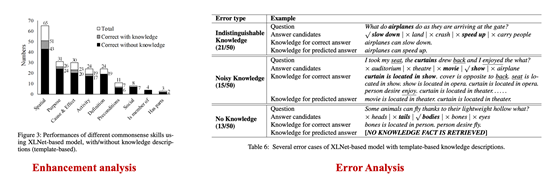
后面的一些 case study分别是证明这个方法加了知识之后到底有多少提升,在具体的例子上作者把那些问题分了一些类别。然后还进行了错误分析,但好像也没有体现出什么有价值的信息,因为这里面给出了几个错误类别基本上都是因为KG本身的一些知识不足所导致的,比如说作者知识区分度不够,就像第例子中飞机可以加速也可以减速,但是这两个东西都不能够精确的回答这一个问题:当飞机到达的时候,到底是该加速还是该减速。此外还有一些错误原因,比如知识根本就不存在,每一个问题可能找不到对应的知识。或者是知识噪音太多导致判断失误。
总结
该论文核心观点是 MRC的难度小于常识问答,所以作者把一个难的任务转化成一个容易的任务,这是作者的一个想法。另外一个想法就是把知识直接用一种更显著的方法(文本)建模,应该也许会好于图的结果(实验里面其实有一些方法是基于gnn的,但是那些方法的效果并不理想,作者觉得既然作者不能够把所有的知识都很好的利用起来,但是如果把它用一种更显著的方法建模的话,利用效果会更好一些。)。此外作者提出了一个观点:哪怕是最好的预训练语言模型,比如t5(训练语调是很庞大的),始终还是不能够包含足够的常识知识。
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。

