
语言模型的预训练已经被证明能够获取大量的世界知识,这对于NLP任务(如回答问题)是至关重要的。然而,这些知识隐式地存储在神经网络的参数中,需要更大的网络来覆盖更多的事实。
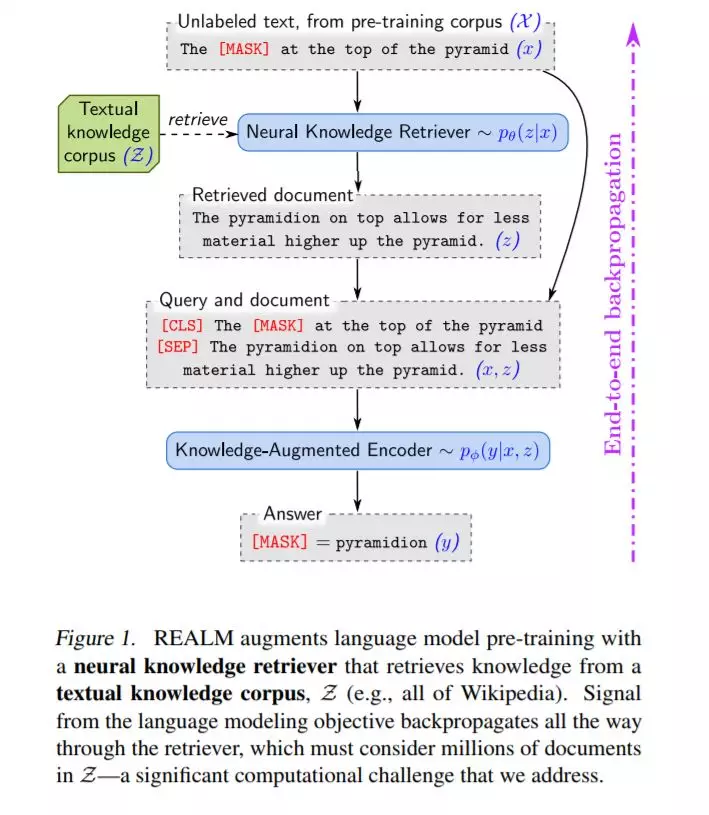
为了以更模块化和可解释性的方式捕获知识,我们在语言模型前训练中增加了一个潜在的知识检索器,它允许模型从一个大型语料库(如Wikipedia)中检索和处理文档,这些语料库在前训练、微调和推理期间使用。我们第一次展示了如何以一种无监督的方式预先训练这种知识检索器,
使用掩码语言建模作为学习信号,并通过一个考虑数百万文档的检索步骤进行反向传播。
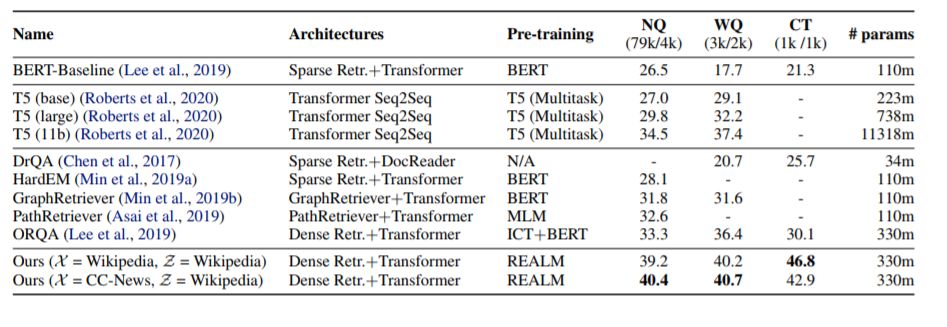
通过对具有挑战性的开放领域问题回答(Open-QA)任务进行微调,我们证明了增强语言模型预训练(REALM)的有效性。我们比较了三种流行的开放qa基准上的最先进的显式和隐式知识存储模型,发现我们的性能显著优于所有以前的方法(4-16%的绝对准确性),同时还提供了定性的好处,如可解释性和模块化。
地址:
成为VIP会员查看完整内容
相关内容

专知会员服务
95+阅读 · 2019年11月8日

相关VIP内容
专知会员服务
95+阅读 · 2019年11月8日
相关资讯