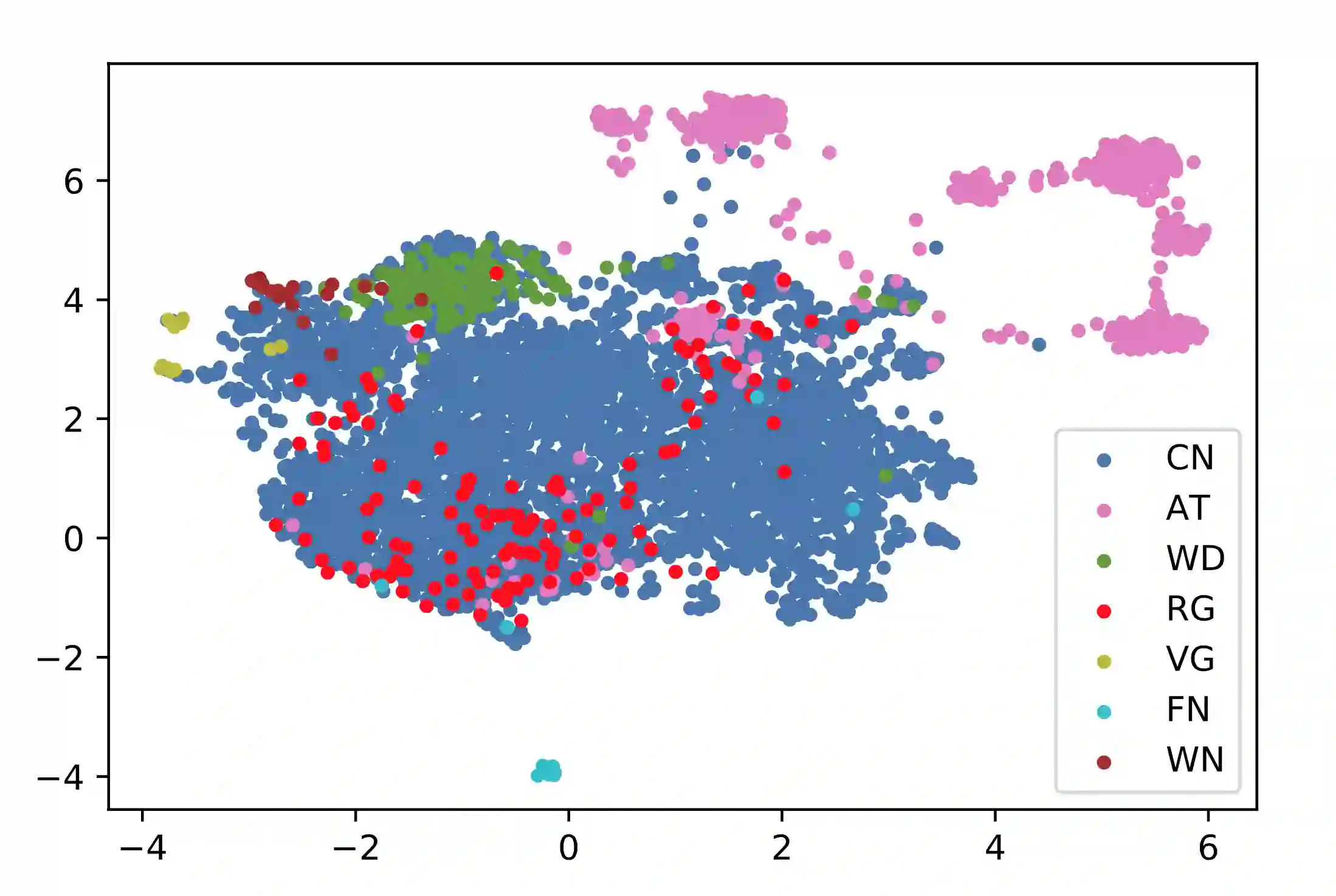
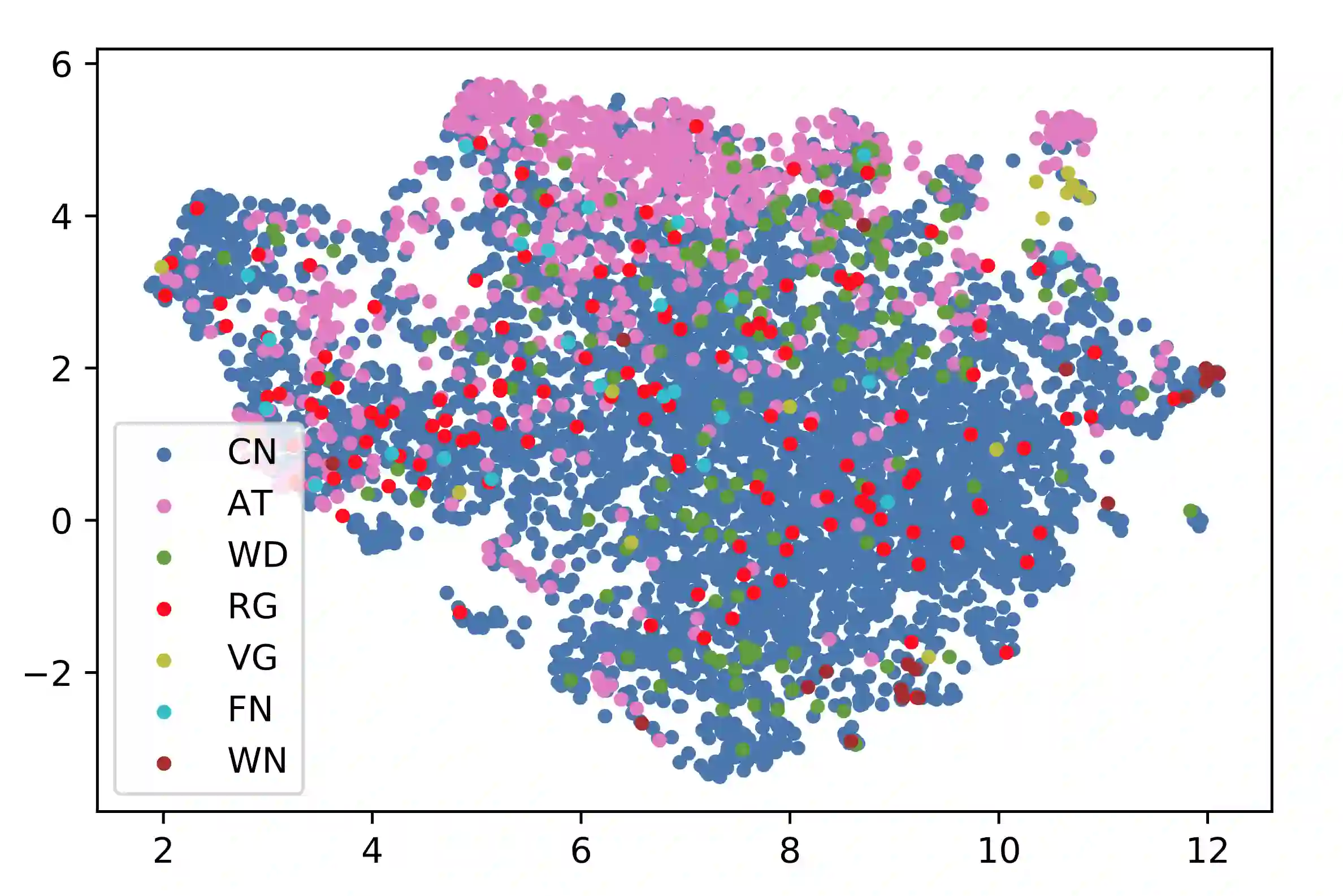
Sources of commonsense knowledge aim to support applications in natural language understanding, computer vision, and knowledge graphs. These sources contain complementary knowledge to each other, which makes their integration desired. Yet, such integration is not trivial because of their different foci, modeling approaches, and sparse overlap. In this paper, we propose to consolidate commonsense knowledge by following five principles. We apply these principles to combine seven key sources into a first integrated CommonSense Knowledge Graph (CSKG). We perform analysis of CSKG and its various text and graph embeddings, showing that CSKG is a well-connected graph and that its embeddings provide a useful entry point to the graph. Moreover, we show the impact of CSKG as a source for reasoning evidence retrieval, and for pre-training language models for generalizable downstream reasoning. CSKG and all its embeddings are made publicly available to support further research on commonsense knowledge integration and reasoning.
翻译:普通知识的来源旨在支持在自然语言理解、计算机视觉和知识图方面的应用,这些来源包含相互补充的知识,因此它们需要融合。然而,这种融合并非微不足道,因为它们有不同的调子、建模方法和零散的重叠。在本文件中,我们提议按照五项原则合并普通知识。我们运用这些原则将七个关键来源合并为第一个综合的普通知识图(CSKG),我们对CSKG及其各种文本和图集进行分析,表明CSKG是一个紧密相连的图表,其嵌入为图提供了有用的切入点。此外,我们展示了CSKG作为推理证据检索来源和通用下游推理培训前语言模型的影响。CSKG及其所有嵌入部分都可供公众使用,以支持关于普通知识整合和推理的进一步研究。