【浙大-WWW2022】OntoPrompt & KnowPrompt:知识提示的预训练微调
一、引言


二、背景知识
三、KnowPrompt:“知识提示”学习之知识约束

论文题目:KnowPrompt: Knowledge-aware Prompt-tuning with Synergistic Optimization for Relation Extraction
本文作者:陈想(浙江大学)、张宁豫(浙江大学)、谢辛(陈想)、邓淑敏(浙江大学)、姚云志(浙江大学)、谭传奇(阿里巴巴)、黄非(阿里巴巴)、司罗(阿里巴巴)、陈华钧(浙江大学)
接收会议:WWW2022
论文链接:https://www.zhuanzhi.ai/paper/9e969d1df4eed9ed5bbfde00777b3ab8
代码链接:https://github.com/zjunlp/KnowPrompt
3.1 动机
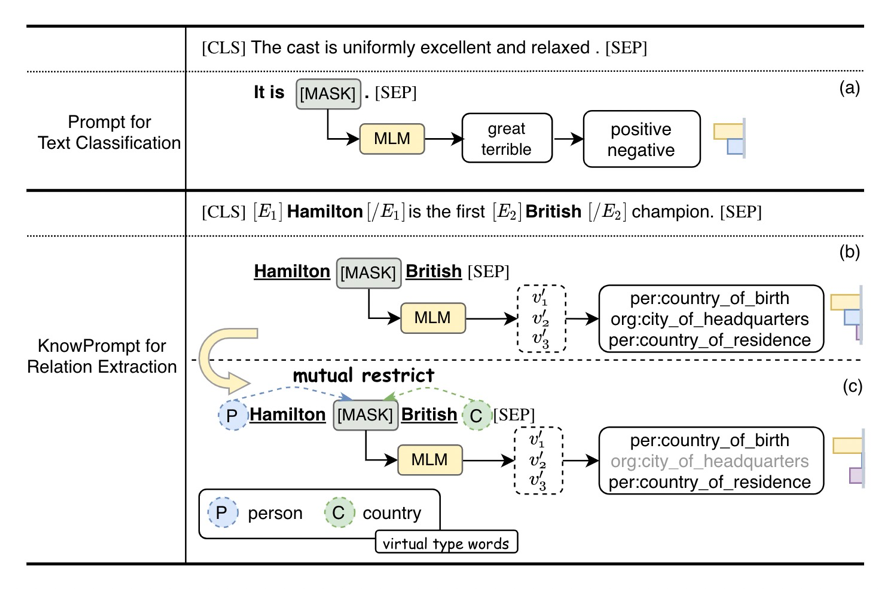
受此启发,我们将实体关系约束知识植入提示学习过程,并提出了KnowPrompt方法。我们通过可学习的虚拟答案词和虚拟类型词构建知识注入的提示,并通过实体关系约束植入外部结构化知识,以降低模板构建成本并提升任务对领域任务的感知。
3.2 方法
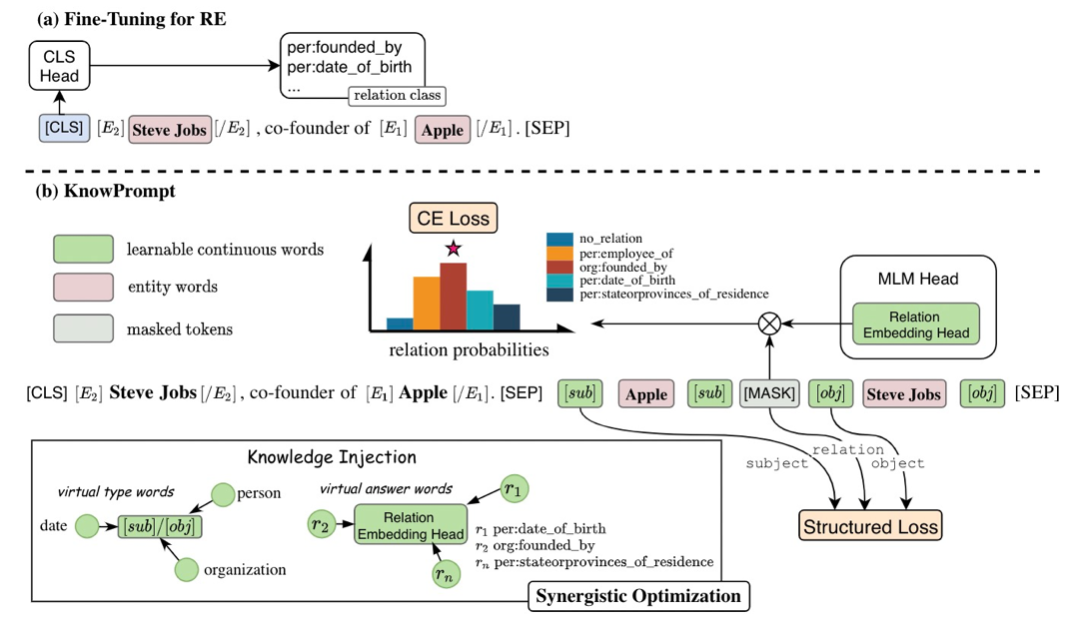
具体来说,KnowPrompt模型分为提示的构建和优化两个步骤:
因为一个经典的提示由两个部分组成,即模板和一组标签词映射,我们提出了虚拟类型词(实体)和虚拟答案词(关系)的构建,用于关系抽取任务的知识注入。
Type Marker 方法可以额外引入实体的类型信息以提高性能,但需要对类型信息进行额外注释,而实体类型标注在数据集中并不总是可用的。因此,我们通过特定关系中包含的先验知识而不是注释来获得潜在实体类型的范围。例如,给定关系“per:country_of_birth”,很明显与该关系匹配的头实体属于“人”,而与该关系匹配的尾实体属于“国家”。直观地说,我们根据关系类型分别估计在候选集𝐶𝑠𝑢𝑏和𝐶𝑜𝑏𝑗上的潜在实体类型对应的先验分布𝜙𝑠𝑢𝑏和𝜙𝑜𝑏𝑗,其中先验分布是通过频率统计来得到的。我们在实体周围分配虚拟类型词,这些词使用一组潜在实体类型的聚合嵌入进行初始化。由于初始化的虚拟类型词对于特定实体来说不是精确类型,这些可学习的虚拟类型词可以根据上下文动态调整,起到类弱化的Type Marker的作用。具体初始化方法如下:
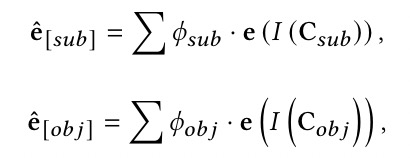
以往关于提示学习的研究通常通过自动生成在词汇表中的一个标签词和一个任务标签之间建立一对一的映射,这种搜索计算复杂度高,且未能利用关系标签中丰富的语义知识。为此,我们假设在语言模型的词汇空间中存在一个虚拟答案词𝑣′∈V′,它可以表示关系的隐含语义。从这个角度来看,我们在MLM Head 层拓展额外的可学习关系嵌入来作为虚拟答案词集 V',以表示相应的关系标签 Y。我们用掩码位置处的 V′上的概率分布重新形式化 𝑝(𝑦|𝑥)。具体来说,我们设置𝜙𝑅=[𝜙𝑟1,𝜙𝑟2, ...,𝜙𝑟𝑚]和C𝑅=[C𝑟1,C𝑟2, ...,C𝑟𝑚],其中𝜙𝑟表示通过分解关系标签𝑟得到的关系语义词在候选集C𝑟上的概率分布,𝑚是关系标签的数量。此外,我们采用𝜙𝑟的加权平均函数来平均C𝑟中每个单词的嵌入并初始化这些关系表示,这可以为提示构建注入关系的语义知识。虚拟答案词𝑣′=M(𝑦)的可学习关系嵌入初始化如下:
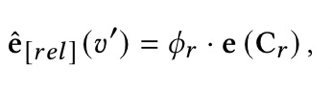
其中
3.2.2 Synergistic Optimization with Knowledge Constraints
由于实体类型和关系标签之间存在密切的交互和联系,且虚拟类型词以及答案词应该与周围的上下文相关联,我们进一步引入了包含结构约束的协同优化方法来优化虚拟类型词和虚拟答案词{
(1)Context-aware Prompt Calibration
尽管虚拟类型和答案词是基于知识初始化的,但它们在潜在变量空间中并非最优,它们应该与周围输入的上下文相关联。因此,需要通过感知上下文来校准它们的表示。给定掩码位置 V′上的概率分布 𝑝(𝑦|𝑥)=𝑝([MASK]=V′|𝑥prompt),我们通过下列损失函数优化虚拟类型词以及答案词:
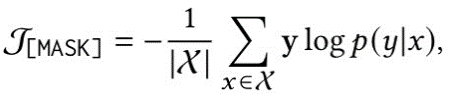
(2)Implicit Structured Constraints
为了融合结构化知识,我们使用了额外的结构化约束来优化提示。具体来说,我们使用三元组(𝑠,𝑟,𝑜) 来描述关系事实,并定义隐式结构化约束的损失如下:
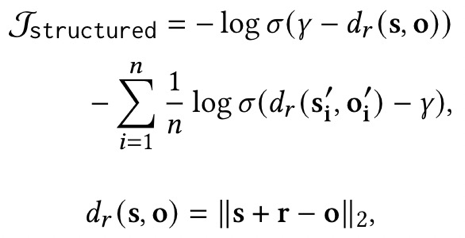
3.3 实验
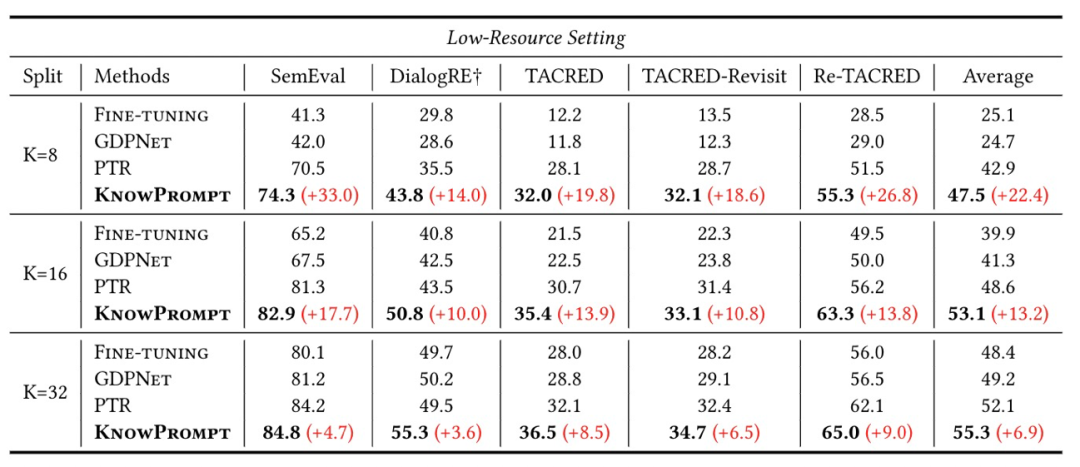
为了验证KnowPrompt的效果,我们在五个常见的关系抽取数据集上评测(具体的数据已在Github开源发布),并在全监督和少样本两个设定下进行了实验。如下表所示,KnowPrompt在全监督场景和低资源少样本场景都取得了最优的性能。具体的实验结果和分析可以参见论文。
四、OntoPrompt:“知识提示”学习之选择性知识植入
论文题目:Ontology-enhanced Prompt-tuning for Few-shot Learning
本文作者:叶宏彬(浙江大学)、张宁豫(浙江大学)、邓淑敏(浙江大学)、陈想(浙江大学)、陈辉(阿里巴巴)、熊飞宇(阿里巴巴)、陈华钧(浙江大学)
发表会议:WWW2022
论文链接:即将发布
4.1 动机
近年来,不少知识植入预训练语言模型的方法被提出,然而并非所有的外部知识都有利于模型性能的提升,不少外部知识会带来噪音并损害模型性能。针对提示学习,如何在植入外部知识过程中选择任务需要的合规、合适、合理的外部知识,并解决知识噪音和知识异构性仍面临一定的挑战。比如,在模板构建中,是否所有的外部提示语料和外部领域词典都有利于知识提示的性能提升?如何高效地选择合适的任务相关的知识并优化学习知识表示?在本文,我们针对上述挑战,提出了基于本体增强的知识提示方法,并通过知识线性化和选择性植入来降低知识噪音和异构性带来的影响。
4.2 方法
具体的说,我们利用任务相关的外部本体知识,将本体知识线性化成文本来作为一种特殊的提示,提出了本体增强知识提示方法OntoPrompt。一种直觉是,预训练语言模型可以从大数据中获取大量的统计信息;而外部知识,如知识图谱和本体库,是人类智慧结晶。如下图所示,本体增强的知识提示学习,可以充分利用大数据先验和人类的智慧结晶。接下来我们介绍方法的细节。
我们的方法是一个通用的框架。如图所示,我们遵循之前的提示学习思路,使用特定的任务提示模板来构建任务输入和生成。提示模板构建如下公式所示:
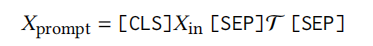
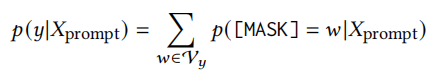
我们的方法将外部的知识以文本形式植入提示学习框架中,以实现模型对任务和领域的感知具体的输入如下图所示:
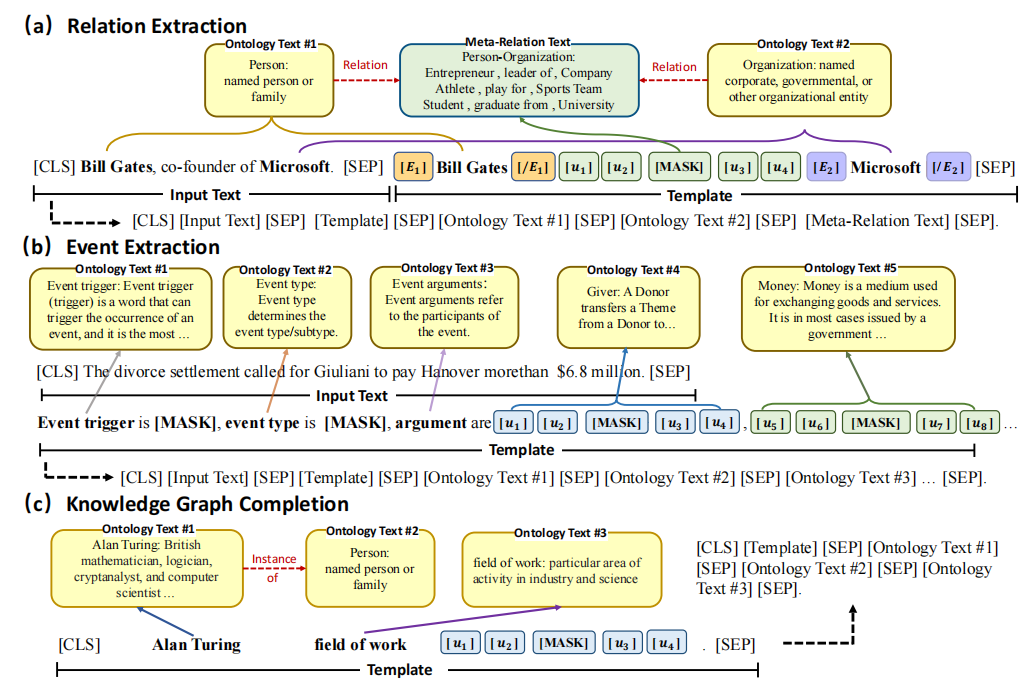
4.2.1 知识线性转换
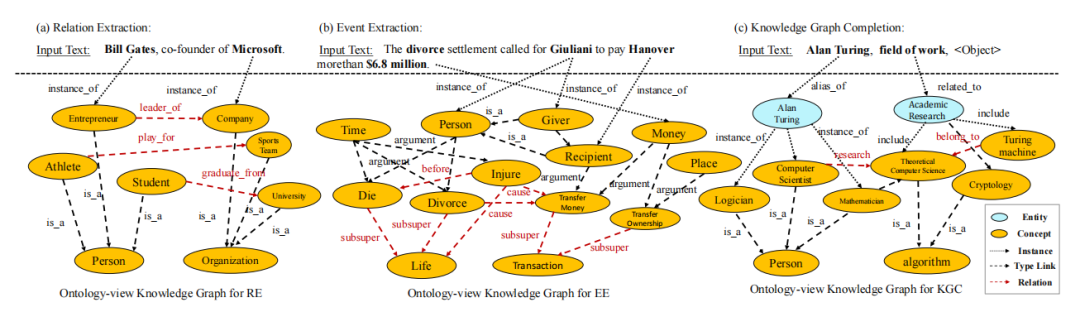
在本文中,外部的本体知识表示为O={C,E,D},其中C是一组概念,E是本体论之间的边,D是每个本体知识的文本描述(本体框架包含一段文本描述,它们是概念的词汇信息,也可以使用属性信息,记作rdfs:comment)。我们在关系抽取和事件抽取中利用与实体相关的类型本体,在知识图补全中利用Domain(即头部实体类型)和Range(即尾部实体类型)约束。对于下游不同任务,我们对每个任务利用不同的本体源进行本体线性化转换。我们首先从外部知识图谱中提取每个实例的本体,然后将这些本体转换为文本形式作为辅助提示,并拼接到原始的提示末尾。
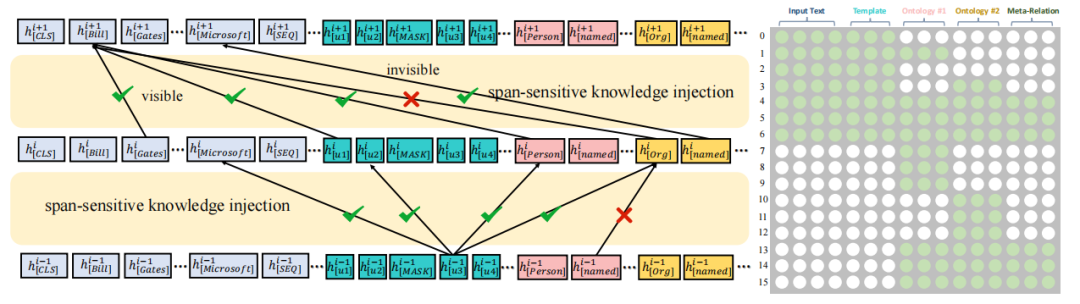
4.2.2 知识选择性注入
由于不加选择的知识植入可能会给原始文本引入一些噪声,并导致性能下降。为了解决这一问题,受到K-BERT[31]启发,我们提出了跨片段选择性知识植入方法。如下图所示。我们使用一个可见矩阵来限制知识注入对输入文本的影响。在语言模型体系结构中,我们在softmax层之前添加了具有自注意权重的注意掩码矩阵。
4.2.3 协同训练算法联合优化知识和文本
由于从本体库植入的知识应与输入文本序列相关联。因此,我们使用联合优化方法来学习外部的本体序列表示和输入文本序列的表示。首先,我们使用实体词嵌入来初始化和优化本体词令牌,同时固定语言模型中的其他参数。然后,我们对模型的所有参数进行优化。
4.3 实验结果
我们在关系抽取、事件抽取、知识图谱链接预测三个任务上验证了模型的性能。在多个数据集包含TACRED-Revisit、SemEval-2010Task8、Wiki80、DialogRE、ACE2005、 UMLS、WN18RR、FB15K-237,我们的方法在少样本设定下均取得了较好的效果。囿于篇幅原因,具体的实验结果可查阅在未来出版(近期会挂出)的正式论文。
五、一些思考和展望
[1] Exploiting cloze-questions for few-shot text classification and natural language inference EACL2021
[2] It’s not just size that matters: Small language models are also few-shot learners NAACL2021
[3] Making Pre-trained Language Models Better Few-shot Learners ACL2021
[4] Pre-train, Prompt, and Predict: A Systematic Survey of Prompting Methods in Natural Language Processing 2021
[5] GPT Understands, Too 2021
[6] Pre-trained Prompt Tuning for Few-shot Learning 2021
[7] Prefix-Tuning: Optimizing Continuous Prompts for Generation ACL2021
[8] Fine-tuned Language Models Are Zero-Shot Learners 2021
[9] Multitask Prompted Training Enables Zero-Shot Task Generalization 2021
[10] Differentiable Prompt Makes Pre-trained Language Models Better Few-shot Learners ICLR2022
[11] Lightner: A lightweight generative framework with prompt-guided attention for low-resource ner 2021
[12] Plug-Tagger: A Pluggable Sequence Labeling Framework Using Language Models 2021
[13] Template-free Prompt Tuning for Few-shot NER 2021
[14] Prompt-Learning for Fine-Grained Entity Typing 2021
[15] Label Verbalization and Entailment for Effective Zero and Few-Shot Relation Extraction EMNLP2021
[16] Few-Shot Text Generation with Pattern-Exploiting Training 2021
[17] Learning to Ask for Data-Efficient Event Argument Extraction AAAI2022(SA)
[18] Eliciting Knowledge from Language Models for Event Extraction 2021
[19] DEGREE: A Data-Efficient Generative Event Extraction Model 2021
[20] Sentiprompt: Sentiment knowledge enhanced prompt-tuning for aspect-based sentiment analysis 2021
[21] Open Aspect Target Sentiment Classification with Natural Language Prompts 2021
[22] The Power of Prompt Tuning for Low-Resource Semantic Parsing 2021
[23] CPT: Colorful Prompt Tuning for Pre-trained Vision-Language Models 2021
[24] Learning to Prompt for Vision-Language Models 2021
[25] Multimodal Few-Shot Learning with Frozen Language Models NeurIPS2021
[26] An Empirical Study of GPT-3 for Few-Shot Knowledge-Based VQA 2021
[27] 联手信息系统专业委员会:“提示学习”术语发布 | CCF术语快线https://mp.weixin.qq.com/s/WMWn9aA6UFRZdeJuhGeWwA
[28] PTR: Prompt Tuning with Rules for Text Classification 2021
[29] Knowledgeable Prompt-tuning: Incorporating Knowledge into Prompt Verbalizer for Text Classification 2021
[30]Knowledgeable machine learning for natural language processing. Communications of the ACM 2021
[31] K-BERT: Enabling Language Representation with Knowledge Graph AAAI2021
[32] Drop Redundant, Shrink Irrelevant: Selective Knowledge Injection for Language Pretraining IJCAI2021
[33] Prompt Programming for Large Language Models: Beyond the Few-Shot Paradigm CHI2021
[34] Why Do Pretrained Language Models Help in Downstream Tasks? An Analysis of Head and Prompt Tuning NeurIPS2021
[35] Knowledge Neurons in Pretrained Transformers 2021
[36] Exploring Low-dimensional Intrinsic Task Subspace via Prompt Tuning 2021
[37] Acquisition of Chess Knowledge in AlphaZero 2021
[38] A few more examples may be worth billions of parameters 2021
[39] Black-Box Tuning for Language-Model-as-a-Service 2021
[40] Openprompt: an open-source framework for prompt-learning 2021
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“KPSO” 就可以获取《【浙大-WWW2022】OntoPrompt & KnowPrompt:知识提示的预训练微调》专知下载链接




