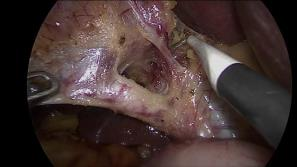
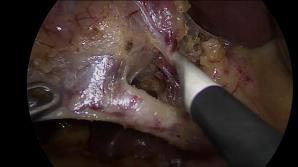
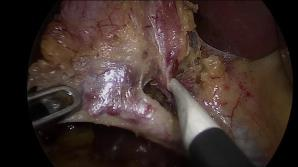
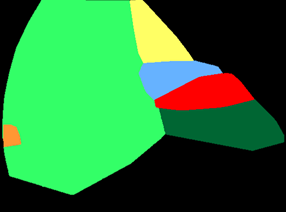
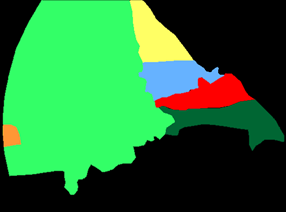
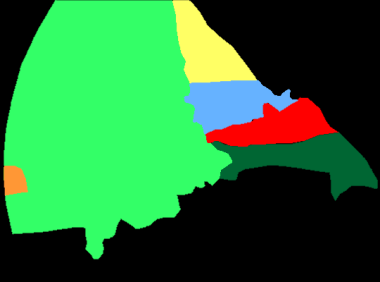
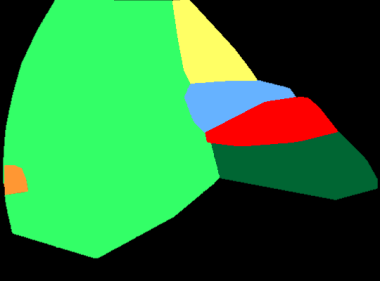
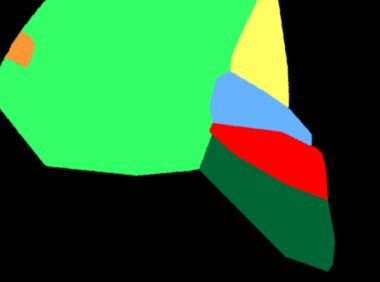
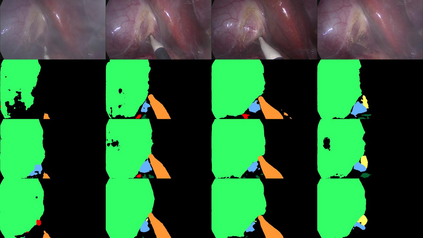
A major obstacle to building models for effective semantic segmentation, and particularly video semantic segmentation, is a lack of large and well annotated datasets. This bottleneck is particularly prohibitive in highly specialized and regulated fields such as medicine and surgery, where video semantic segmentation could have important applications but data and expert annotations are scarce. In these settings, temporal clues and anatomical constraints could be leveraged during training to improve performance. Here, we present Temporally Constrained Neural Networks (TCNN), a semi-supervised framework used for video semantic segmentation of surgical videos. In this work, we show that autoencoder networks can be used to efficiently provide both spatial and temporal supervisory signals to train deep learning models. We test our method on a newly introduced video dataset of laparoscopic cholecystectomy procedures, Endoscapes, and an adaptation of a public dataset of cataract surgeries, CaDIS. We demonstrate that lower-dimensional representations of predicted masks can be leveraged to provide a consistent improvement on both sparsely labeled datasets with no additional computational cost at inference time. Further, the TCNN framework is model-agnostic and can be used in conjunction with other model design choices with minimal additional complexity.
翻译:建立有效语义分解模型的主要障碍是缺少大量且有良好注释的数据集。 这种瓶颈在医学和手术等高度专门和监管领域特别令人望而却步,因为视频语义分解可能具有重要的应用,但数据和专家说明却很少。在这些环境下,在培训过程中可以利用时间线索和解剖限制来提高性能。在这里,我们介绍了用于外科视频视频语义分解的半监督框架“TTCNNN”(TTCNN),即用于外科视频视频语义分解的半监督框架。在这项工作中,我们表明可使用自动代码网络有效提供空间和时间监督信号,以培训深层学习模型。我们测试我们新推出的关于腹腔孔切除程序的视频数据集、视镜和解剖限制方法,以及调制白内障手术手术公共数据集CaDIS。我们表明,预测的口罩的低维度表达方式可以被利用,以持续改进N稀疏的模型化数据集型式和时间框架,在不使用其他复杂度设计框架中可进一步使用。