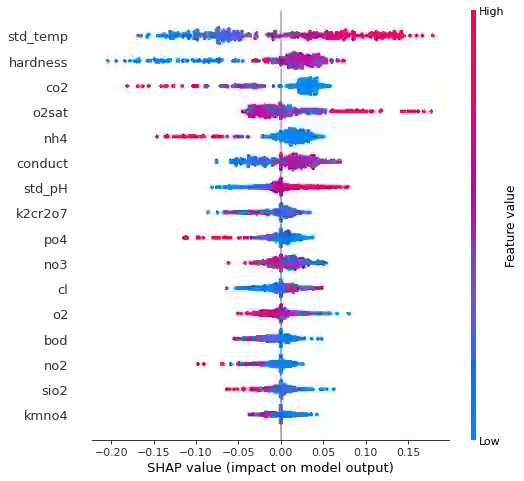
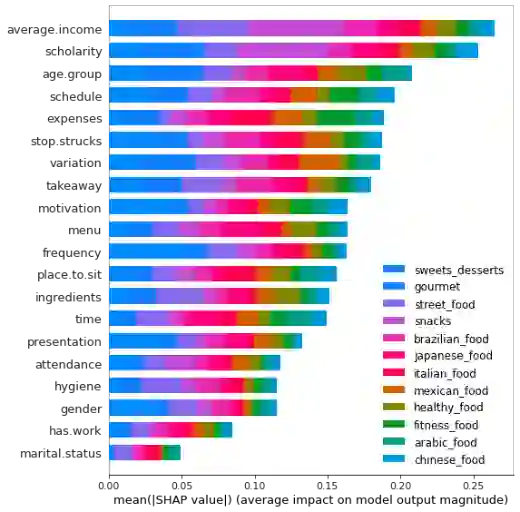
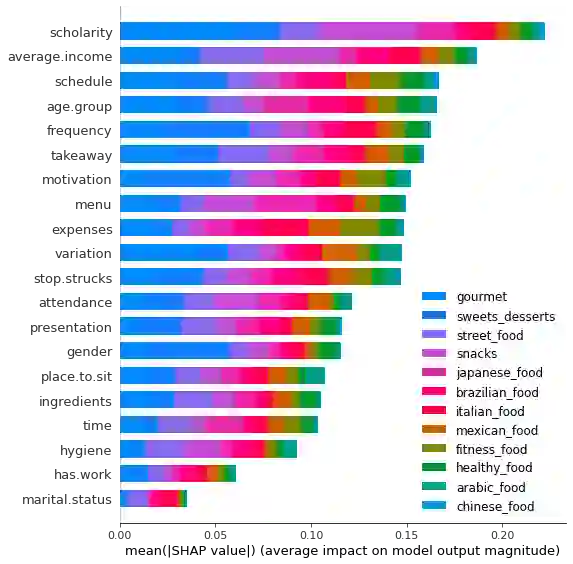
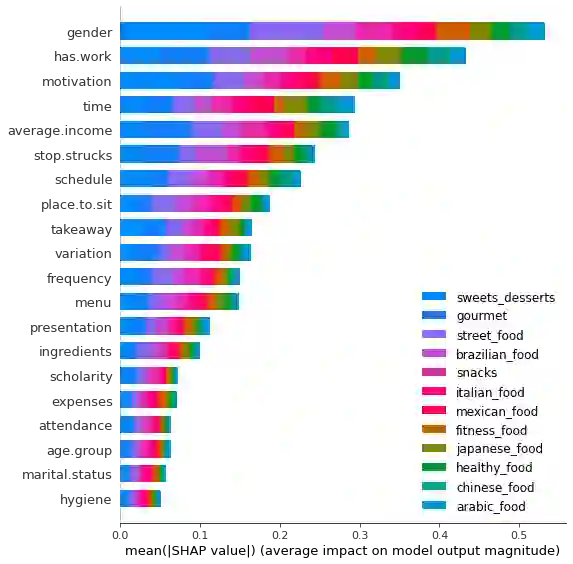
Multi-label classification is a type of classification task, it is used when there are two or more classes, and the data point we want to predict may belong to none of the classes or all of them at the same time. In the real world, many applications are actually multi-label involved, including information retrieval, multimedia content annotation, web mining, and so on. A game theory-based framework known as SHapley Additive exPlanations (SHAP) has been applied to explain various supervised learning models without being aware of the exact model. Herein, this work further extends the explanation of multi-label classification task by using the SHAP methodology. The experiment demonstrates a comprehensive comparision of different algorithms on well known multi-label datasets and shows the usefulness of the interpretation.
翻译:多标签分类是一种分类任务,在有两种或两种以上类别时使用,而我们想要预测的数据点可能不属于任何一个类别或所有类别,同时也可能属于所有类别或所有类别。在现实世界中,许多应用实际上涉及多个标签,包括信息检索、多媒体内容说明、网络挖掘等等。已经应用了一个以游戏理论为基础的框架,称为Shamapley Additive Explectations(SHAP),用于解释各种受监督的学习模式,而没有确切的模型。在这里,这项工作通过使用 SHAP 方法进一步扩展了多标签分类任务的解释。该实验展示了对众所周知的多标签数据集的不同算法的全面比较,并展示了解释的有用性。