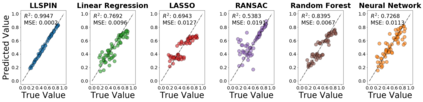
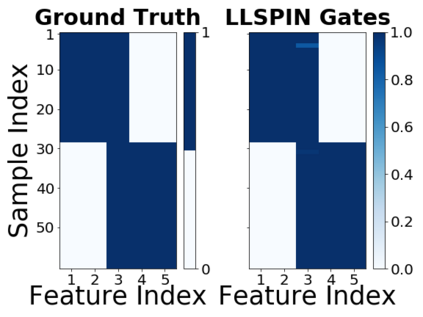
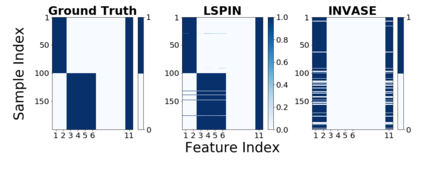
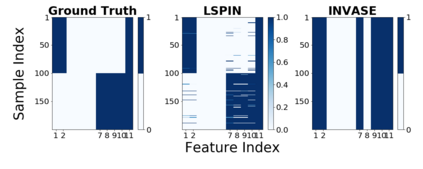
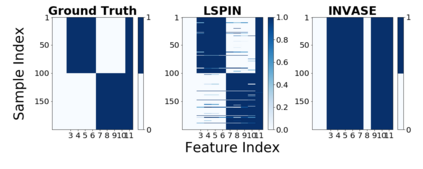
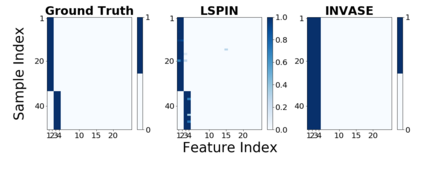
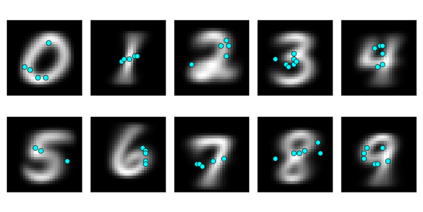
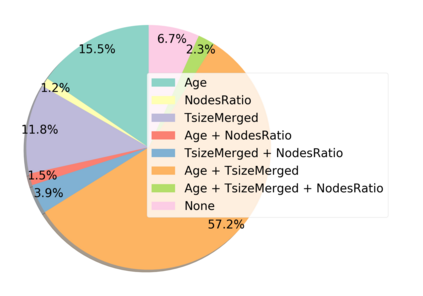
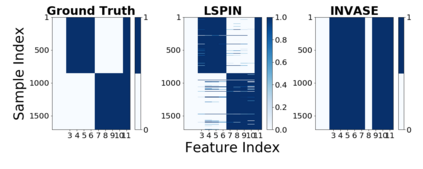
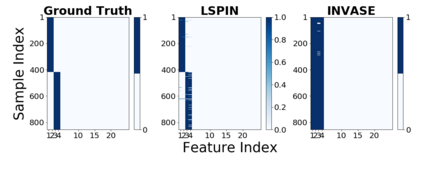
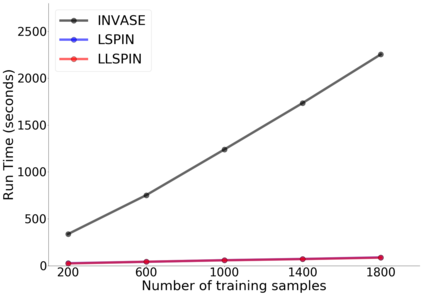
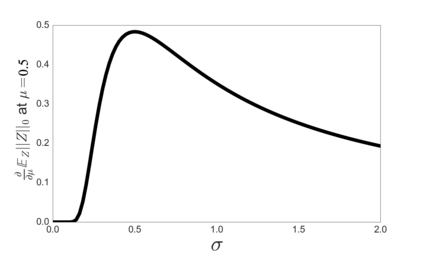
Despite the enormous success of neural networks, they are still hard to interpret and often overfit when applied to low-sample-size (LSS) datasets. To tackle these obstacles, we propose a framework for training locally sparse neural networks where the local sparsity is learned via a sample-specific gating mechanism that identifies the subset of most relevant features for each measurement. The sample-specific sparsity is predicted via a \textit{gating} network, which is trained in tandem with the \textit{prediction} network. By learning these subsets and weights of a prediction model, we obtain an interpretable neural network that can handle LSS data and can remove nuisance variables, which are irrelevant for the supervised learning task. Using both synthetic and real-world datasets, we demonstrate that our method outperforms state-of-the-art models when predicting the target function with far fewer features per instance.
翻译:尽管神经网络取得了巨大成功,但是在应用到低缩缩(LSS)数据集时,它们仍然很难解释,而且往往过于适合。为了克服这些障碍,我们提议了一个框架,用于培训本地稀疏神经网络,通过一个抽样专用的格子机制,确定每种测量最相关特征的子集,从而学习本地宽度。通过一个与 kextit{ging} 网络同时培训的\ textit{pregy} 网络,可以预测样本特定的宽度。通过学习预测模型的这些子集和重量,我们获得了一个可解释的神经网络,可以处理LSS数据,并可以消除与监督的学习任务无关的棘手变量。我们利用合成和真实世界数据集,证明我们的方法在预测目标功能时,在以非常少的特点预测时,超过了最新模型。