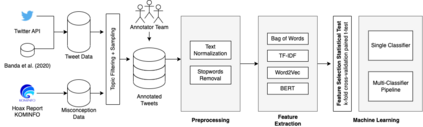
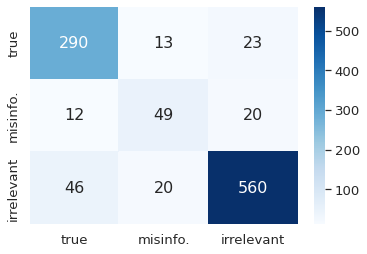
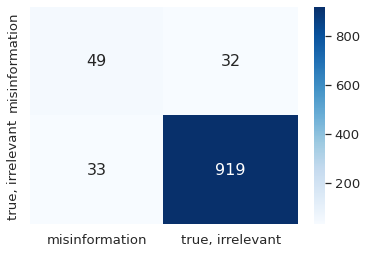
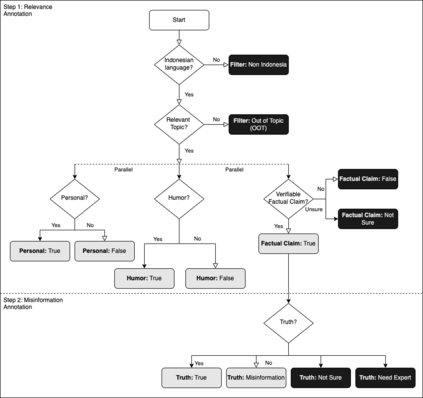
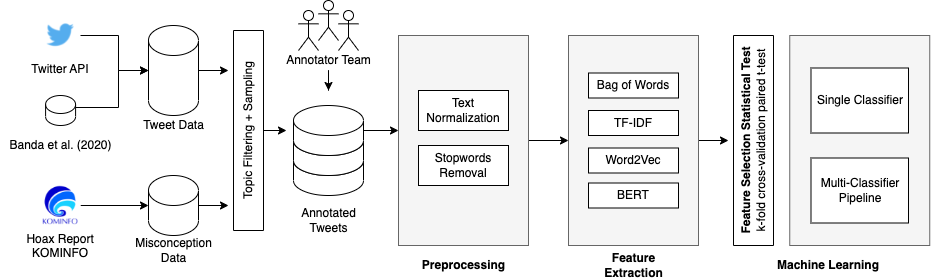
The COVID-19 pandemic has caused globally significant impacts since the beginning of 2020. This brought a lot of confusion to society, especially due to the spread of misinformation through social media. Although there were already several studies related to the detection of misinformation in social media data, most studies focused on the English dataset. Research on COVID-19 misinformation detection in Indonesia is still scarce. Therefore, through this research, we collect and annotate datasets for Indonesian and build prediction models for detecting COVID-19 misinformation by considering the tweet's relevance. The dataset construction is carried out by a team of annotators who labeled the relevance and misinformation of the tweet data. In this study, we propose the two-stage classifier model using IndoBERT pre-trained language model for the Tweet misinformation detection task. We also experiment with several other baseline models for text classification. The experimental results show that the combination of the BERT sequence classifier for relevance prediction and Bi-LSTM for misinformation detection outperformed other machine learning models with an accuracy of 87.02%. Overall, the BERT utilization contributes to the higher performance of most prediction models. We release a high-quality COVID-19 misinformation Tweet corpus in the Indonesian language, indicated by the high inter-annotator agreement.
翻译:自2020年初以来,COVID-19大流行给全球造成了巨大的影响,这给社会带来了许多混乱,特别是由于通过社交媒体传播错误信息。虽然已经进行了若干项研究,涉及在社交媒体数据中发现错误信息,但大多数研究都集中在英语数据集上。关于印度尼西亚COVID-19错误信息检测的研究仍然稀缺。因此,通过这项研究,我们收集了印度尼西亚的COVID-19大流行数据集并做了注释,并建立了探测COVID-19错误信息的预测模型。数据集的构建是由一组贴上推文数据相关性和错误信息的告示员组成的团队进行的。在本研究中,我们提出了使用IndoBERT预先培训的语言模型进行两阶段分类模型,用于Tweet错误检测任务。我们还试验了其他一些文本分类基准模型。实验结果显示,将相关预测的BERT序列分类器和用于识别错误信息的Bi-LSTM组合,比其他机器学习模型精确度高87.02 %。总体来说,BERTERP的利用有助于大多数预测模型的更高性表现。我们发布了高品质的CVI-D号之间的协议。我们在印度尼西亚高质量的TRIDAD号之间协议。