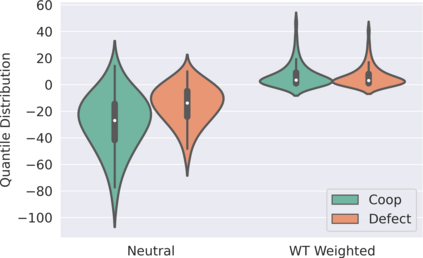
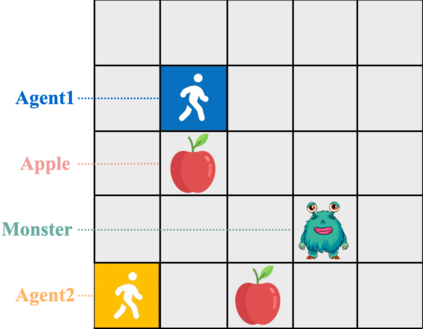
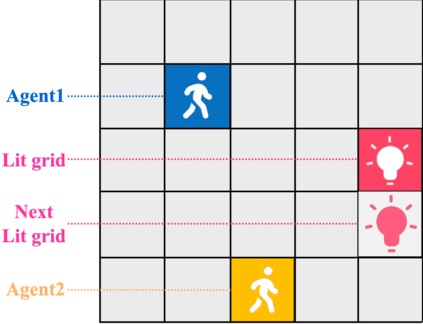
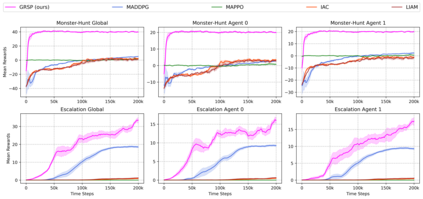
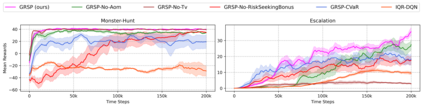
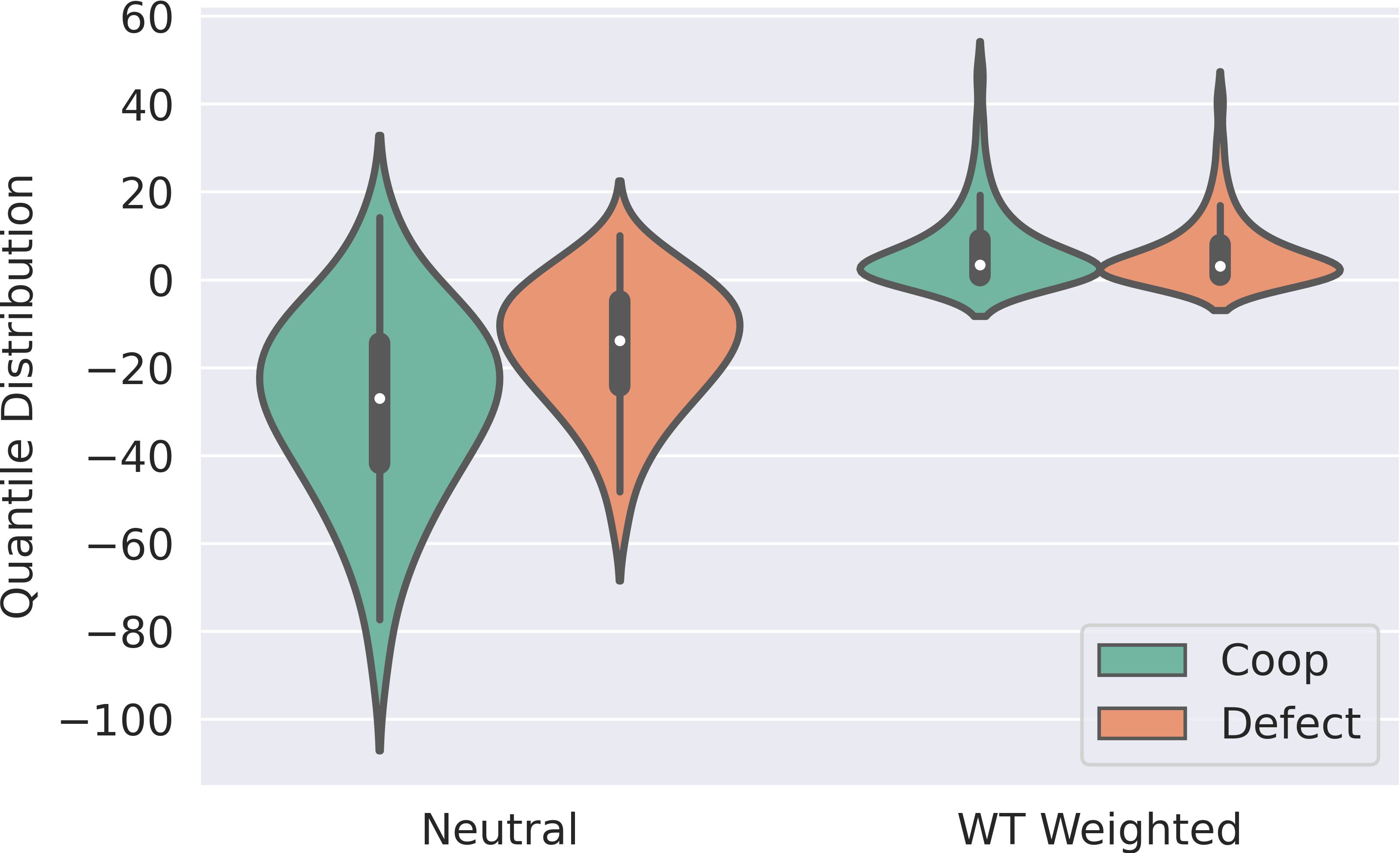
While various multi-agent reinforcement learning methods have been proposed in cooperative settings, few works investigate how self-interested learning agents achieve mutual coordination in decentralized general-sum games and generalize pre-trained policies to non-cooperative opponents during execution. In this paper, we present a generalizable and sample efficient algorithm for multi-agent coordination in decentralized general-sum games without any access to other agents' rewards or observations. Specifically, we first learn the distributions over the return of individuals and estimate a dynamic risk-seeking bonus to encourage agents to discover risky coordination strategies. Furthermore, to avoid overfitting opponents' coordination strategies during training, we propose an auxiliary opponent modeling task so that agents can infer their opponents' type and dynamically alter corresponding strategies during execution. Empirically, we show that agents trained via our method can achieve mutual coordination during training and avoid being exploited by non-cooperative opponents during execution, which outperforms other baseline methods and reaches the state-of-the-art.
翻译:虽然在合作环境中提出了多种多剂强化学习方法,但很少有人会调查自我感兴趣的学习者如何在分散的普通游戏中实现相互协调,并在执行过程中将事先训练的政策推广到不合作的反对者。在本文件中,我们提出了在分散的普通游戏中进行多剂协调的通用和抽样有效算法,而没有任何机会获得其他代理人的奖赏或观察。具体地说,我们首先了解个人返回的分布情况,并估计一个动态的风险搜索奖金,以鼓励代理人发现危险的协调战略。此外,为了避免在培训中过度适应对手的协调战略,我们提议了一项辅助对手的示范任务,以便代理人能够推断其反对者的类型,并在执行过程中动态地改变相应的战略。我们生动地表明,通过我们的方法培训的代理人可以在培训中实现相互协调,避免在执行过程中被不合作的反对者利用,因为这些方法超越了其他基线方法,到达了最先进的地方。