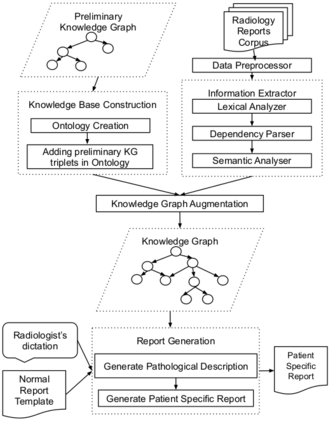
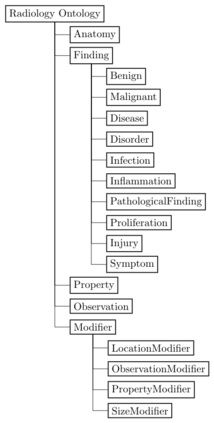
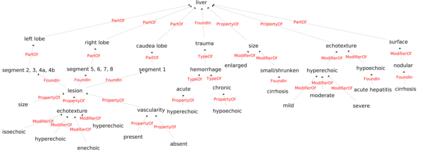
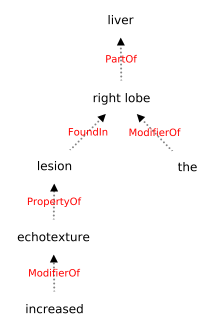
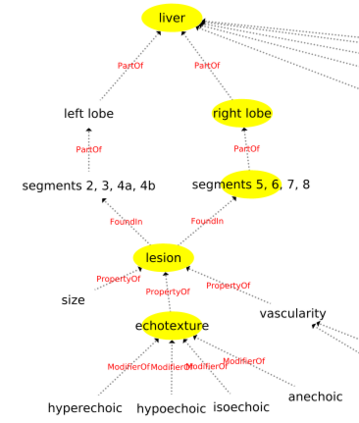
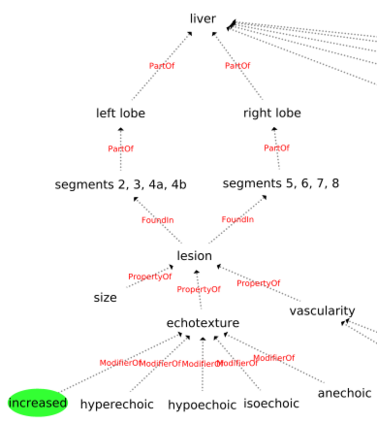
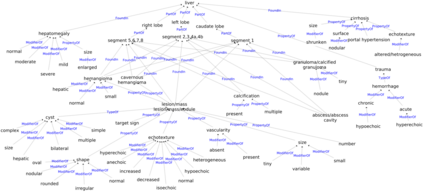
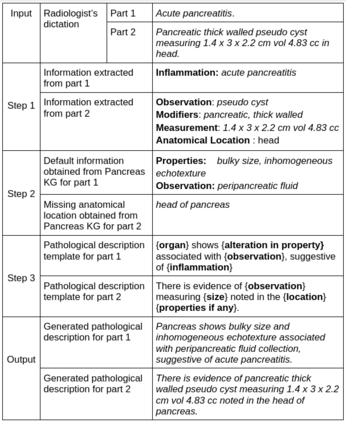
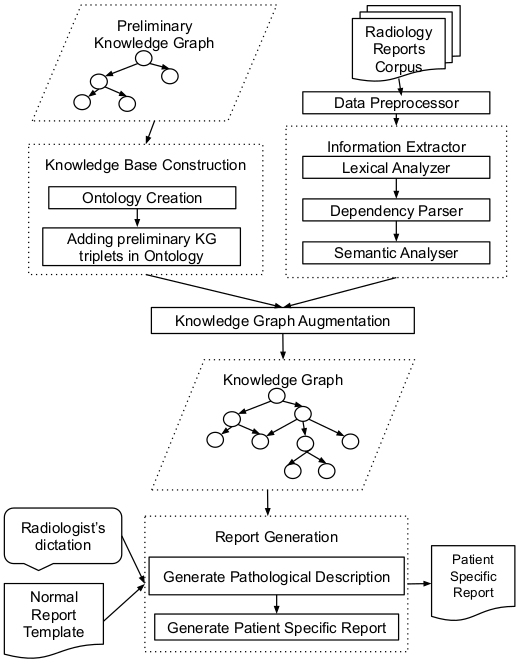
Conventionally, the radiologist prepares the diagnosis notes and shares them with the transcriptionist. Then the transcriptionist prepares a preliminary formatted report referring to the notes, and finally, the radiologist reviews the report, corrects the errors, and signs off. This workflow causes significant delays and errors in the report. In current research work, we focus on applications of NLP techniques like Information Extraction (IE) and domain-specific Knowledge Graph (KG) to automatically generate radiology reports from radiologist's dictation. This paper focuses on KG construction for each organ by extracting information from an existing large corpus of free-text radiology reports. We develop an information extraction pipeline that combines rule-based, pattern-based, and dictionary-based techniques with lexical-semantic features to extract entities and relations. Missing information in short dictation can be accessed from the KGs to generate pathological descriptions and hence the radiology report. Generated pathological descriptions evaluated using semantic similarity metrics, which shows 97% similarity with gold standard pathological descriptions. Also, our analysis shows that our IE module is performing better than the OpenIE tool for the radiology domain. Furthermore, we include a manual qualitative analysis from radiologists, which shows that 80-85% of the generated reports are correctly written, and the remaining are partially correct.
翻译:在《公约》中,放射学家编写诊断说明,并将这些诊断说明与抄录员分享。然后,抄录员编写初步格式化报告,提及笔记,最后,放射学家审查报告,纠正错误和签名。这一工作流程导致报告出现重大延误和错误。在目前的研究工作中,我们侧重于应用国家实验室技术,如信息提取(IE)和特定域知识图(KG),从放射学家的口述中自动生成放射报告。本文侧重于每个器官的KG构造,从现有的大量自由文本放射报告中提取信息。我们开发了一个信息提取管道,将基于规则的、基于模式的和基于字典的技术与基于词汇的技术结合起来,以提取实体和关系。短口述中缺失的信息可以从 KGs获得,以生成病理描述,从而生成放射学报告。使用语义相似度度度测量的基因学描述显示病理学描述,显示97%与金质标准病理描述相似性。此外,我们的分析显示,我们的IE模块将基于规则的、模式和基于字典的技术与基于词汇的特性特性特性的特性技术结合,我们从80年的放射学中还含有了正确性分析。