摘要——在过去十年中,生成对抗网络(GANs)、掩码自编码器(Masked Autoencoders)和扩散模型(Diffusion Models)等生成建模技术的进展极大地推动了生物学研究与发现,促成了分子设计、蛋白质生成、药物研发等领域的突破。与此同时,生物学应用也为评估生成模型的能力提供了宝贵的测试平台。近年来,**流匹配(Flow Matching)**作为一种强大且高效的替代扩散模型的生成建模方法,逐渐受到关注,并在生物学与生命科学中的应用不断增长。
本文首次对流匹配的发展与其在生物领域的应用进行了全面综述。我们首先系统回顾了流匹配的基础原理及其变体,随后将其应用划分为三个主要方向:生物序列建模、分子生成与设计、以及肽类与蛋白质生成,并对每一方向的最新进展进行了深入分析。此外,我们还总结了常用的数据集与软件工具,并在最后讨论了未来可能的研究方向。
相关整理资源可访问:https://github.com/Violet24K/Awesome-Flow-Matching-Meets-Biology。 关键词:流匹配,生成建模,分子生成,蛋白质生成,计算生物学,人工智能,综述
一、引言
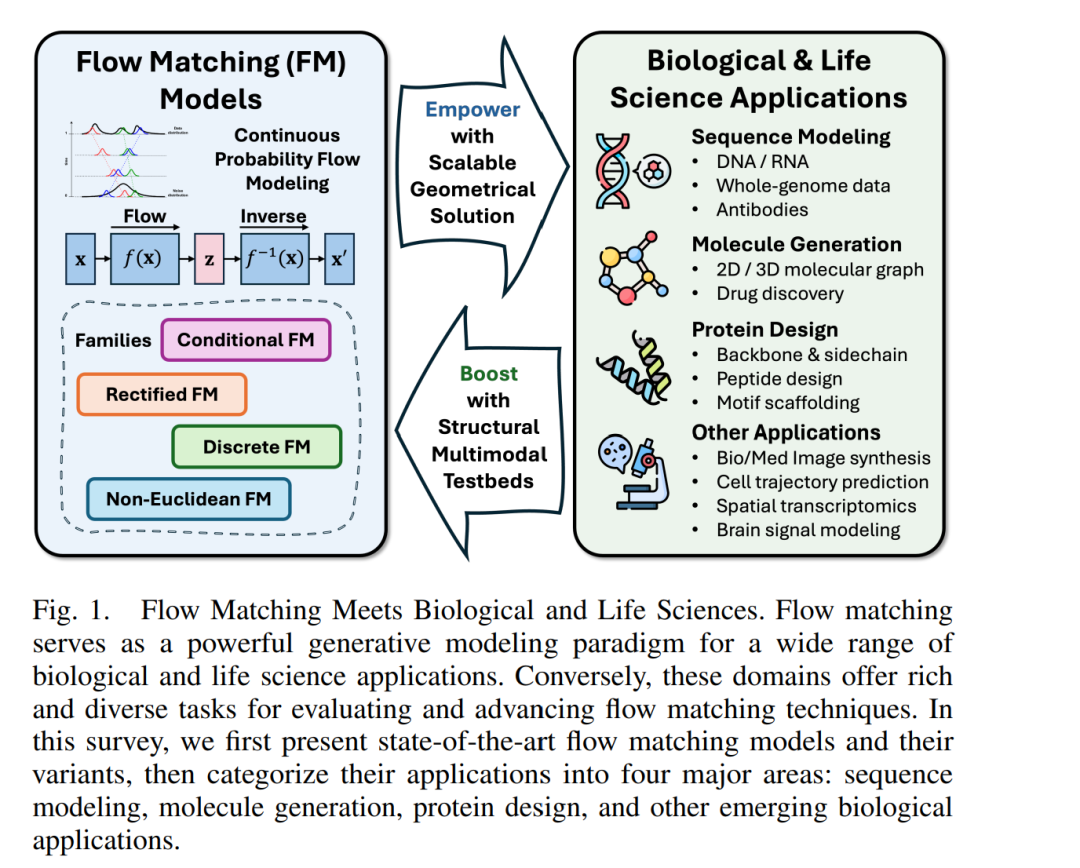
流匹配(Flow Matching, FM) [1] 近期作为一种强大的生成建模范式崭露头角,提供了一个灵活且具可扩展性的框架,已广泛应用于多个领域,如计算机视觉 [1, 2] 和自然语言处理 [3, 4]。通过在简单分布与复杂分布之间构建连续的概率轨迹,FM 提供了一种高效且有理论支持的方法来建模高维结构化数据。虽然 FM 已在图像、视频和语言生成等常规生成任务中展现出卓越性能,其潜力远不止于此。尤其值得关注的是,它能够在保持结构和几何约束的同时建模多种模态,使其非常适用于生物与生命科学中的应用场景。 与此同时,生物与生命科学应用也为 FM 提供了天然的测试平台(见图 1)。这类任务涵盖从基因组序列建模 [5, 6, 7]、分子图生成 [8, 9, 10] 和蛋白质结构预测 [11, 12, 13],到生物医学图像合成 [14, 15, 16, 17] 等多个方面,通常具有高维度、多模态以及受结构、物理或生化约束严格支配的特性。事实上,这些任务已被广泛用作生成模型的性能评估基准,如生成对抗网络(GANs)[18, 19, 20]、掩码自编码器(MAEs)[21, 22, 23, 24] 和扩散模型(Diffusion Models)[25, 26, 27]。与传统的基于规则的模拟方法 [28–31] 和基于物理的模型 [32–35] 相比,这些机器学习驱动的生成模型提供了一种数据驱动的替代方案,能够扩展到复杂的生物系统,适应多样的模态,并突破人工设计规则的局限 [36–44]。通过直接从经验数据中学习,这些模型不仅能生成具有生物合理性的结果,还显著降低了对领域知识的依赖。 作为一种新兴且前景广阔的方法,FM 不仅继承了前述模型在表达能力、可扩展性和数据效率方面的优势,还引入了基于连续概率流的更稳定的训练目标。其在推理步骤较少的情况下生成高质量样本的能力,使其在精度和效率都至关重要的生物应用中尤为具有吸引力。
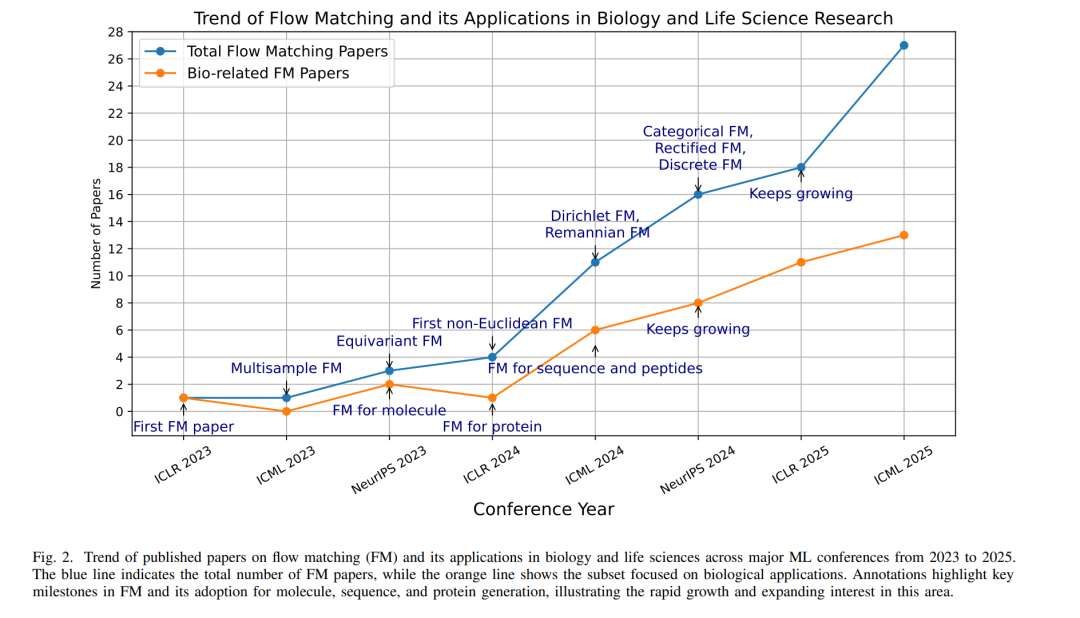
对 FM 在生物问题上的应用兴趣正在迅速增长。如图 2 所示,FM 相关论文数量呈持续上升趋势,尤其是生物相关应用的增幅显著。首次在生物领域应用 FM 的研究出现在 NeurIPS 2023 [45, 46],聚焦于分子生成。随后,该势头延续至 ICLR 2024,推出了基于 FM 的蛋白质生成模型 [47],ICML 2024 进一步推动了在生物序列与肽类生成方面的进展。2024 与 2025 年更是涌现出多个专业化的 FM 变体,如分类型 FM(categorical FM) [48]、修正型 FM(rectified FM) [49],以及非欧几里得形式,包括黎曼型(Riemannian) [50] 与狄利克雷型(Dirichlet) FM [51]。这些方法开始应用于结构生物学、分子构象建模和生物医学影像等领域。
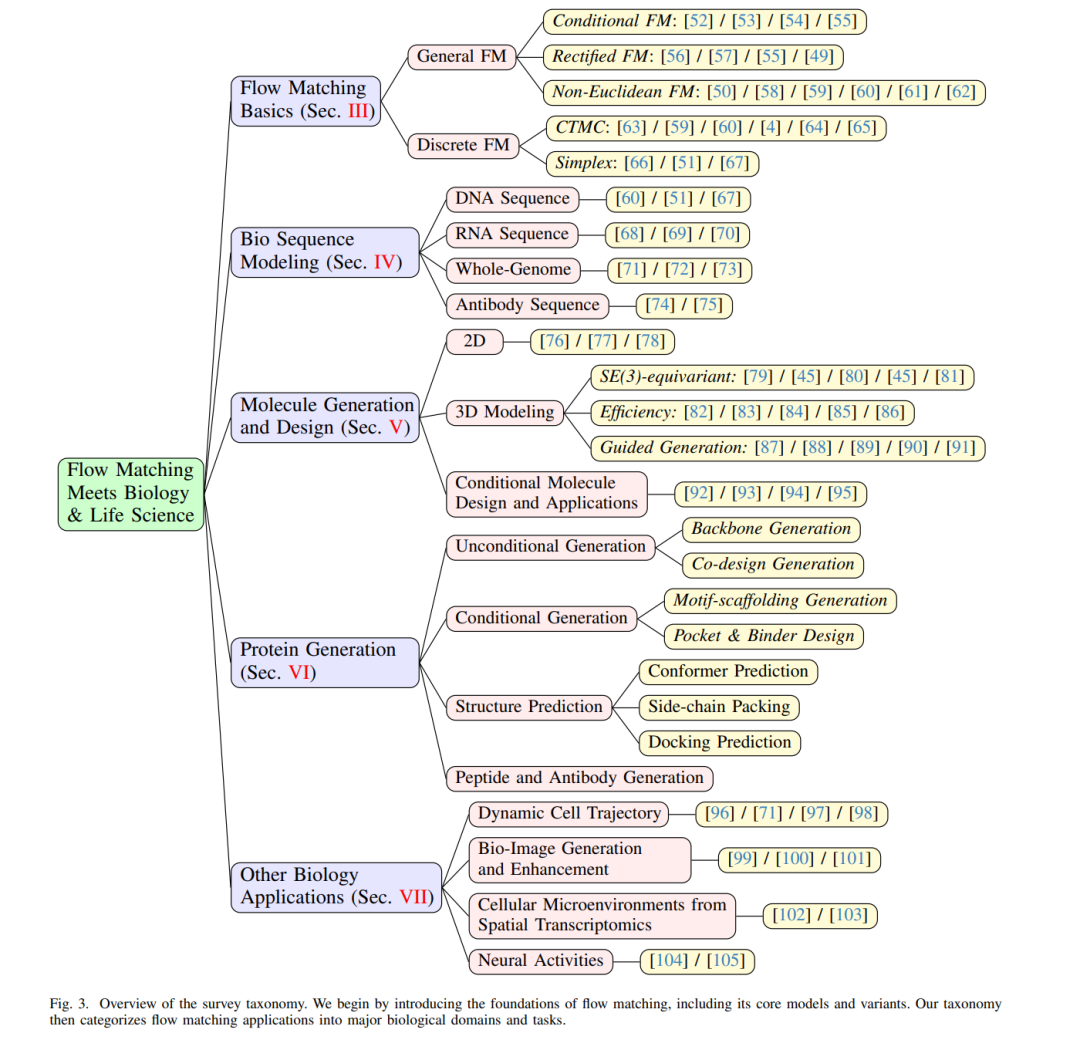
FM 的方法创新与其在生命科学中的不断扩展共同推动了该研究方向的快速演进。然而,相关研究日益碎片化,导致难以系统追踪关键进展与新兴趋势。因此,本文旨在填补该空白,首次系统综述 FM 在生物与生命科学领域中的方法演化与应用实践。我们将从 FM 的基础与变体出发,梳理其在生物序列建模、分子生成与设计、蛋白质生成三大核心领域的应用,并探讨生物图像建模、空间转录组学等辅助主题,最终总结常用数据集与工具,并探讨未来的挑战与研究方向。我们的目标是为初学者提供清晰的入门路径,同时为经验研究者勾勒该领域的整体发展图景。
A. 生物生成建模的挑战
生物系统是自然界中最复杂、最多面性的系统之一 [106–108],其结构与功能历经数十亿年演化,并受物理、化学与信息机制深度耦合的控制。对这类系统的建模一直是科学界的重要挑战,亟需能在精确性与灵活性之间取得平衡的工具 [109–114]。生物数据与现象的复杂性源于多种因素交织,主要挑战包括: 1. 需要嵌入丰富的领域知识,如物理定律与生化约束,以保证生成样本的结构与功能有效性; 1. 数据稀缺、缺失与噪声普遍存在,这通常源自昂贵或易出错的实验程序; 1. 生物过程天然具有多尺度与多模态特性,从原子层级到细胞行为,同时整合序列、结构与时空信号等多种数据类型; 1. 对可控与条件感知生成的需求不断提升,例如生成满足特定生物属性或治疗目标的样本; 1. 模型需具备高准确性同时兼具可扩展性与采样效率,尤其在药物发现与蛋白质设计等场景中,推理速度至关重要。
FM 作为一种新近提出的生成建模范式,在应对上述挑战方面展现出巨大潜力。它通过学习一个确定性的向量场,将简单的基础分布连续映射到复杂目标数据,从而带来多项对生物建模尤为有利的优势,如更快更稳定的采样过程、更易于在结构化输入条件下进行建模,并可自然引入几何或物理先验。近年来,已有越来越多的研究将 FM 应用于生物任务。这些早期成果不仅验证了方法的通用性,也展示了其对结构化、多模态且受约束的生物系统的良好建模能力,使其有望成为生命科学中传统生成框架的有力替代者。
B. 我们的贡献
本综述首次系统总结了流匹配方法及其在生物与生命科学领域的应用。我们的主要贡献包括: * 流匹配方法的统一分类体系:我们提出了一个结构化的 FM 方法分类,包括通用 FM、条件型与修正型 FM、非欧几里得与离散 FM,以及混合变体。 * 生物应用的系统综述:我们将 FM 的生物应用划分为三大核心方向:生物序列建模、分子生成与设计、蛋白质生成,并进一步探讨了若干新兴应用。 * 全面的数据集与基准总结:整理并评述了 FM 研究中常用的生物数据集、基准与软件工具。 * 趋势、挑战与研究前沿分析:通过文献计量趋势梳理 FM 的发展脉络,识别关键方法创新,分析领域建模挑战,启发未来研究方向。 * 促进建模与生物领域的跨界连接:通过将 FM 的方法进展映射至多种生物挑战,搭建起机器学习研究者与生物科学研究者之间的桥梁。
C. 与现有综述的关系
相关已有综述可大致分为三类。第一类专注于生成建模方法本身,或是系统回顾某一类生成模型 [115, 118, 121],或是聚焦特定领域的应用,如计算机视觉 [119]、推荐系统 [120] 与异常检测 [116]。第二类综述则关注 FM 出现之前生成模型在生物领域的应用,如 [124] 回顾了用于分子设计的生成模型,[123] 聚焦于新药设计,[117] 总览了预测与生成建模在生物学中的应用。表 I 对比了各综述所覆盖的生成模型类型与应用领域。 据我们所知,本文是首个专门面向 FM 及其在生物与生命科学中应用的系统综述。我们希望通过链接生成建模的最新进展与其在生物领域的迅速发展,填补当前文献中的关键空白。
D. 综述结构概览
为全面展现 FM 在生物与生命科学中的发展图谱,本文结构如下: * 第 III 节介绍 FM 的基本概念与核心方法,为其在生物场景中的应用奠定基础; * 第 IV–VI 节依次探讨其在生物序列生成、分子生成与设计、肽类与蛋白质生成等具体应用场景中的进展; * 第 VII 节拓展讨论其他新兴应用,如生物图像建模与空间转录组学; * 最后,总结未来研究方向与挑战,旨在激发对该快速演进领域的进一步探索与创新。
图 3 展示了本综述的整体结构,并细分每个部分下的若干子主题以供深入探讨。