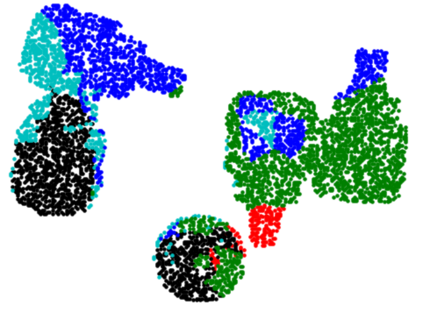
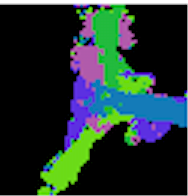
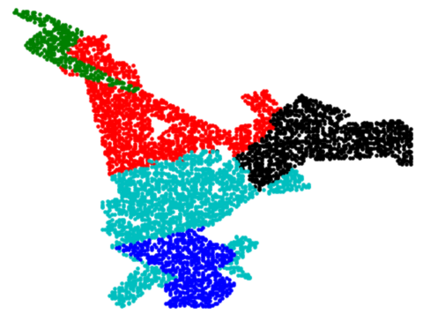
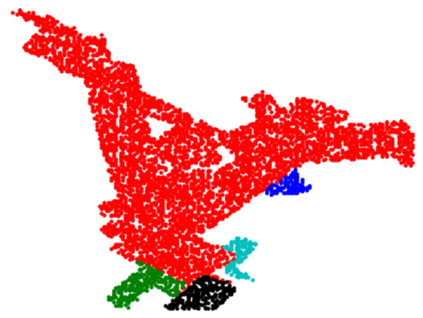
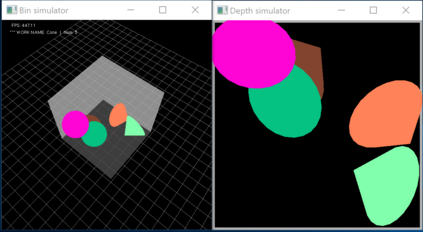
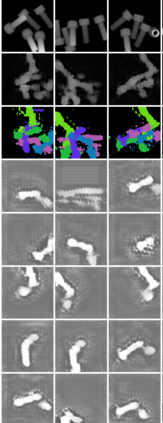
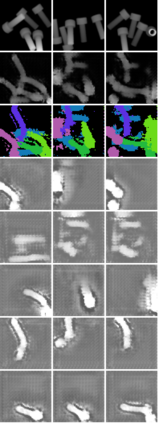
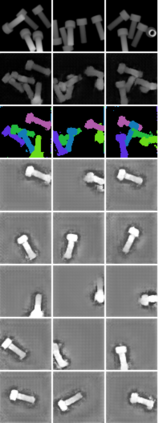
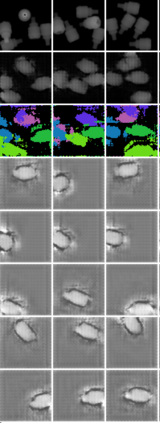
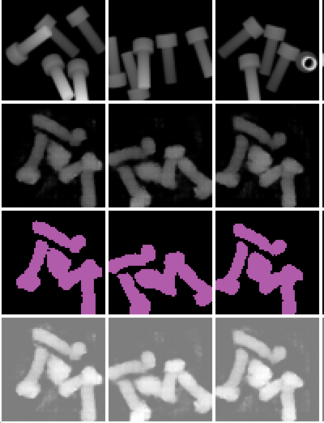
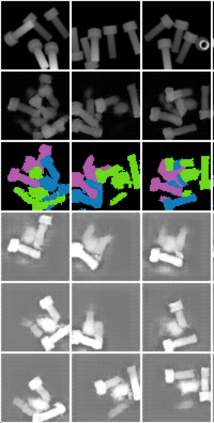
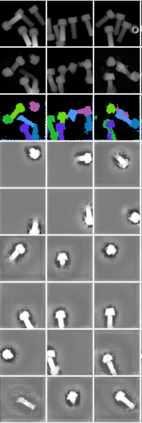
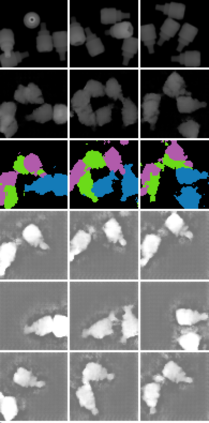
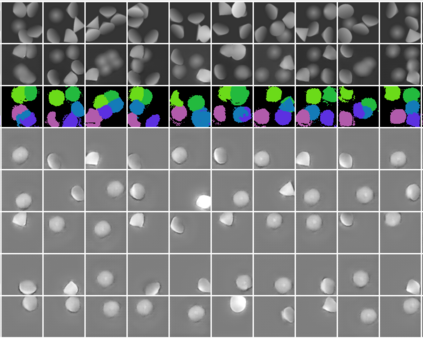
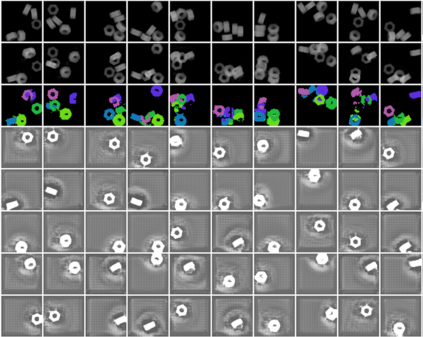
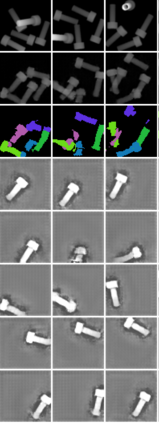
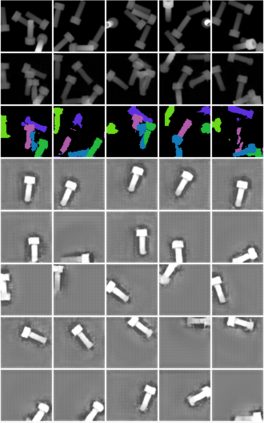
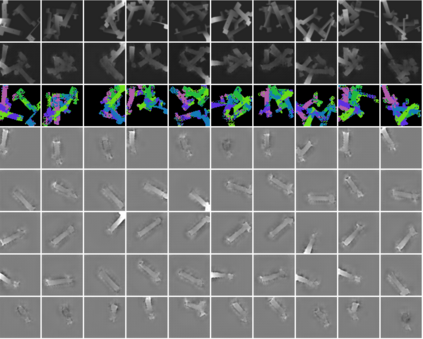
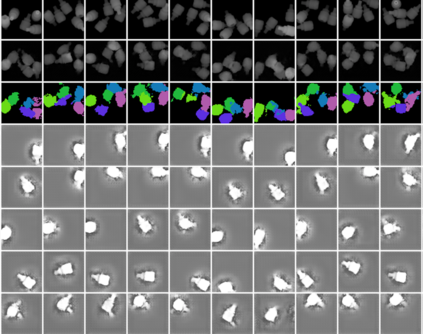
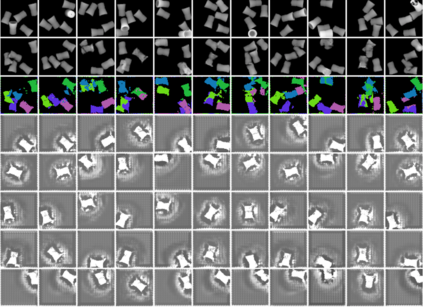
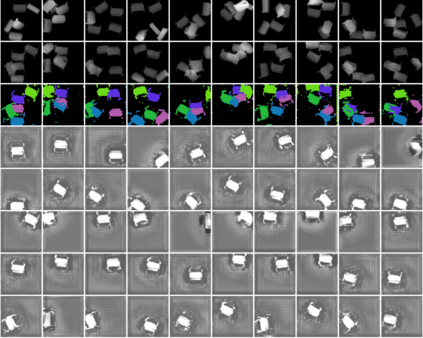
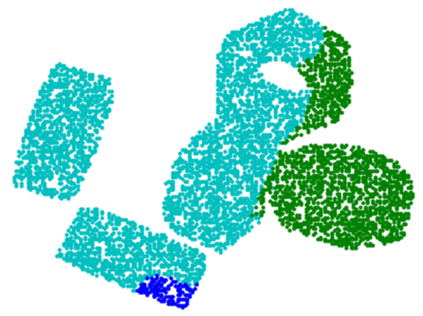In this paper, we present InSeGAN, an unsupervised 3D generative adversarial network (GAN) for segmenting (nearly) identical instances of rigid objects in depth images. Using an analysis-by-synthesis approach, we design a novel GAN architecture to synthesize a multiple-instance depth image with independent control over each instance. InSeGAN takes in a set of code vectors (e.g., random noise vectors), each encoding the 3D pose of an object that is represented by a learned implicit object template. The generator has two distinct modules. The first module, the instance feature generator, uses each encoded pose to transform the implicit template into a feature map representation of each object instance. The second module, the depth image renderer, aggregates all of the single-instance feature maps output by the first module and generates a multiple-instance depth image. A discriminator distinguishes the generated multiple-instance depth images from the distribution of true depth images. To use our model for instance segmentation, we propose an instance pose encoder that learns to take in a generated depth image and reproduce the pose code vectors for all of the object instances. To evaluate our approach, we introduce a new synthetic dataset, "Insta-10", consisting of 100,000 depth images, each with 5 instances of an object from one of 10 classes. Our experiments on Insta-10, as well as on real-world noisy depth images, show that InSeGAN achieves state-of-the-art performance, often outperforming prior methods by large margins.
翻译:在本文中, 我们介绍 InSeGAN 是一个不受监督的 3D 3D 组合对抗网络( GAN ), 在深度图像中分割( 近距离) 相同的刻板对象。 我们使用分析并合成的方法设计了一个新型 GAN 结构, 以合成多份深度图像, 对每个实例进行独立控制。 在SeGAN 中, 使用一套代码矢量( 例如随机噪声矢量), 每套编码一个由学习的隐含对象模板所代表对象的 3D 深度图像。 生成器有两个不同的模块。 第一个模块, 实例特性生成器, 使用每个编码组合将隐含的模板转换为每个对象实例的特征映像 。 第二个模块, 深度图像转换器, 将所有单份深度图像映射成第一个模块的图像, 生成多份深度图像。 导师将生成的多份深度图像与真实深度图像区分。 例如, 我们使用模型, 我们建议用一个示例, 显示一个显示一个图像的颜色, 显示一个实例, 显示每个图像的深度, 显示我们之前的 10 的图像的深度, 显示一个模型, 复制的10 。