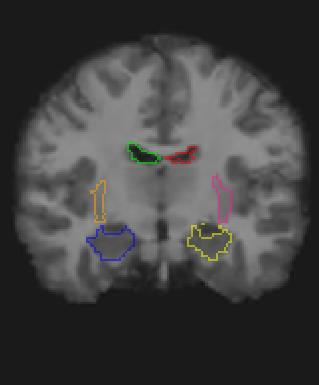
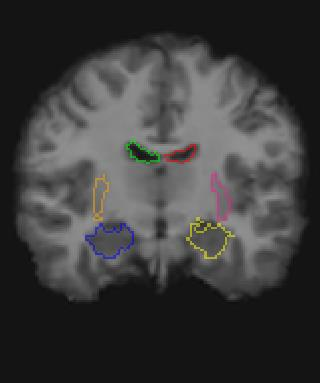
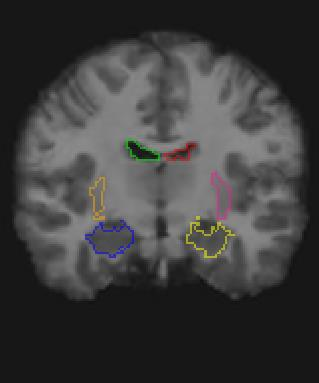
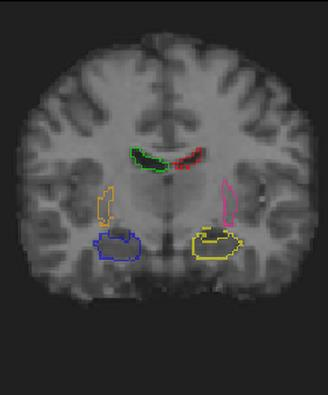
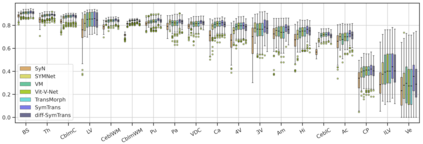
Medical image registration is a fundamental and critical task in medical image analysis. With the rapid development of deep learning, convolutional neural networks (CNN) have dominated the medical image registration field. Due to the disadvantage of the local receptive field of CNN, some recent registration methods have focused on using transformers for non-local registration. However, the standard Transformer has a vast number of parameters and high computational complexity, which causes Transformer can only be applied at the bottom of the registration models. As a result, only coarse information is available at the lowest resolution, limiting the contribution of Transformer in their models. To address these challenges, we propose a convolution-based efficient multi-head self-attention (CEMSA) block, which reduces the parameters of the traditional Transformer and captures local spatial context information for reducing semantic ambiguity in the attention mechanism. Based on the proposed CEMSA, we present a novel Symmetric Transformer-based model (SymTrans). SymTrans employs the Transformer blocks in the encoder and the decoder respectively to model the long-range spatial cross-image relevance. We apply SymTrans to the displacement field and diffeomorphic registration. Experimental results show that our proposed method achieves state-of-the-art performance in image registration. Our code is publicly available at \url{https://github.com/MingR-Ma/SymTrans}.
翻译:医学图像登记是医学图像分析中一项根本性和关键的任务。随着深层学习的迅速发展,进化神经网络(CNN)在医学图像登记领域占据了主导地位。由于CNN当地可接收域的不利之处,最近一些登记方法侧重于使用变压器进行非本地登记。然而,标准变压器有许多参数和高计算复杂性,导致变压器只能在注册模型的底部应用。结果,只有最低分辨率才能提供粗糙的信息,限制变压器在其模型中的贡献。为了应对这些挑战,我们建议建立一个基于变压器的高效多头自留(CEMSA)块,该块将减少传统变压器的参数,并捕捉当地空间背景信息,以减少注意机制中的语义模糊性。根据拟议的CEMSA,我们提出了一个新型的Symetricyter变压器模型(Symoration)。Symall 将变压器和解调器分别用于模拟长空跨空间互换器/变压器的模型。我们在Symal-Matial登记中可以获取的Sytraal-modroal-modal-motion mastration mastration