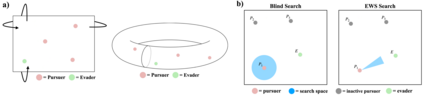
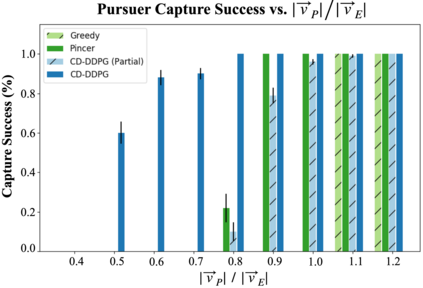
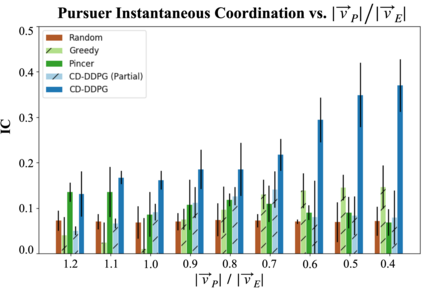
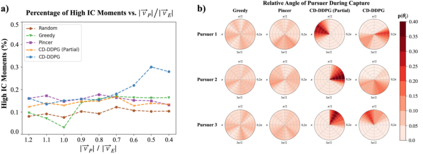
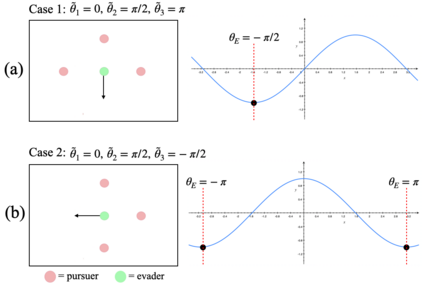
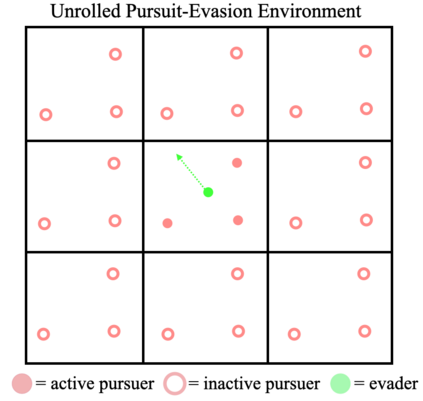
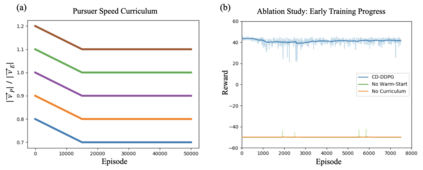
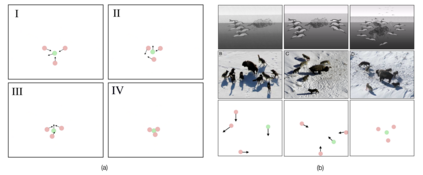
We propose a curriculum-driven learning strategy for solving difficult multi-agent coordination tasks. Our method is inspired by a study of animal communication, which shows that two straightforward design features (mutual reward and decentralization) support a vast spectrum of communication protocols in nature. We highlight the importance of similarly interpreting emergent communication as a spectrum. We introduce a toroidal, continuous-space pursuit-evasion environment and show that naive decentralized learning does not perform well. We then propose a novel curriculum-driven strategy for multi-agent learning. Experiments with pursuit-evasion show that our approach enables decentralized pursuers to learn to coordinate and capture a superior evader, significantly outperforming sophisticated analytical policies. We argue through additional quantitative analysis -- including influence-based measures such as Instantaneous Coordination -- that emergent implicit communication plays a large role in enabling superior levels of coordination.
翻译:我们提出了解决困难的多代理人协调任务的课程驱动学习战略。我们的方法受到动物交流研究的启发,研究显示两种直接的设计特征(相互奖励和分散管理)在性质上支持广泛的通信协议。我们强调类似地将突发通信解释为一个频谱的重要性。我们引入了一种非机器人的、连续的、空间探索的规避环境,并表明天真的分散化学习效果不佳。然后我们提出了一种由课程驱动的多代理人学习新颖战略。追逐实验表明,我们的方法使分散的追逐者能够学习如何协调和捕一个高超的逃逸者,其业绩大大超过复杂的分析政策。我们通过额外的定量分析 -- -- 包括基于影响力的措施,例如非即时协调 -- -- 来论证,隐含的交流在促成更高程度的协调方面起着很大作用。