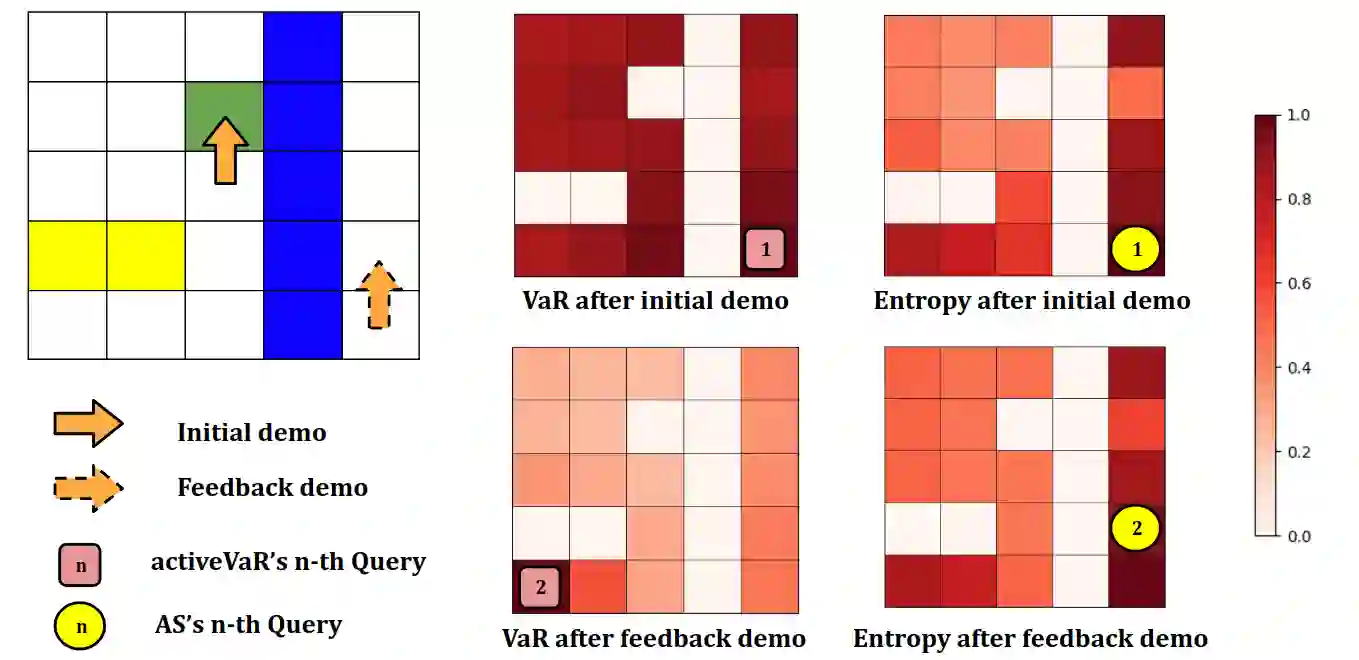
Active learning from demonstration allows a robot to query a human for specific types of input to achieve efficient learning. Existing work has explored a variety of active query strategies; however, to our knowledge, none of these strategies directly minimize the performance risk of the policy the robot is learning. Utilizing recent advances in performance bounds for inverse reinforcement learning, we propose a risk-aware active inverse reinforcement learning algorithm that focuses active queries on areas of the state space with the potential for large generalization error. We show that risk-aware active learning outperforms standard active IRL approaches on gridworld, simulated driving, and table setting tasks, while also providing a performance-based stopping criterion that allows a robot to know when it has received enough demonstrations to safely perform a task.
翻译:从演示中积极学习让机器人可以查询人的具体投入类型,从而实现高效学习。 现有工作探索了各种积极的查询策略; 但是,据我们所知,这些策略中没有一个直接将机器人正在学习的政策的性能风险降到最低。 利用最近在性能限制方面的进步来进行反向强化学习,我们提议了一种风险意识积极的反向强化学习算法,将积极查询的重点放在可能发生大规模一般化错误的州空间地区。 我们显示,风险意识的积极学习超越了在电网世界、模拟驾驶和表格设置任务上的标准性IRL方法,同时提供了基于性能的停止标准,使机器人能够知道何时收到足够的演示来安全地执行任务。