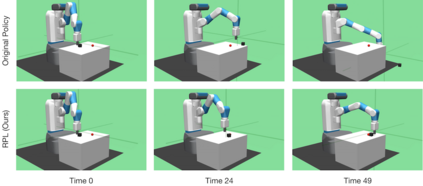
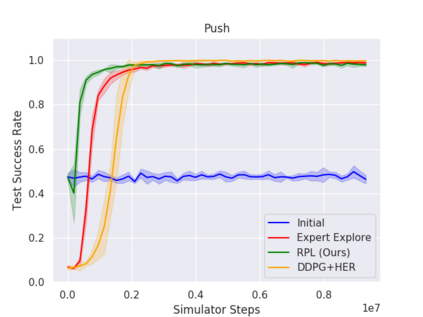
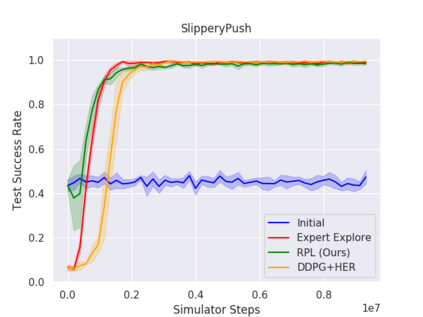
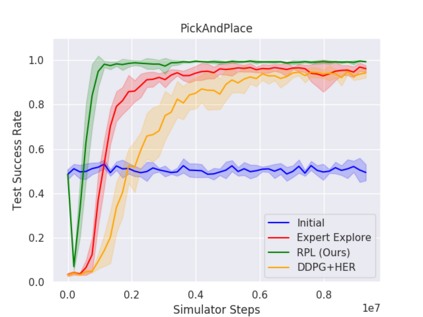
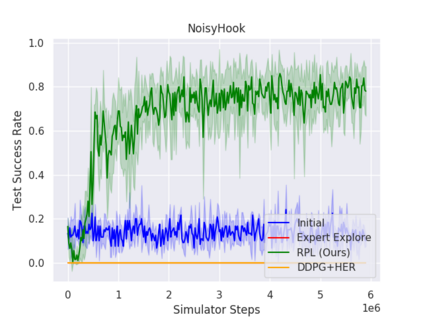
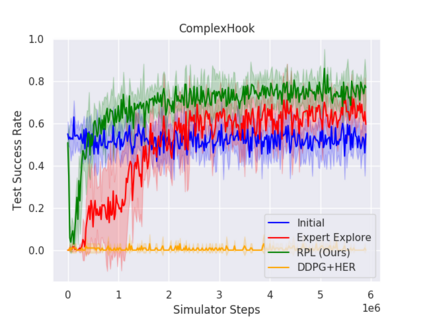
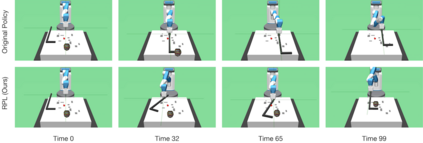
We present Residual Policy Learning (RPL): a simple method for improving nondifferentiable policies using model-free deep reinforcement learning. RPL thrives in complex robotic manipulation tasks where good but imperfect controllers are available. In these tasks, reinforcement learning from scratch remains data-inefficient or intractable, but learning a residual on top of the initial controller can yield substantial improvement. We study RPL in five challenging MuJoCo tasks involving partial observability, sensor noise, model misspecification, and controller miscalibration. By combining learning with control algorithms, RPL can perform long-horizon, sparse-reward tasks for which reinforcement learning alone fails. Moreover, we find that RPL consistently and substantially improves on the initial controllers. We argue that RPL is a promising approach for combining the complementary strengths of deep reinforcement learning and robotic control, pushing the boundaries of what either can achieve independently.
翻译:我们提出残余政策学习(RPL):这是利用无模型深度强化学习来改进非差别政策的简单方法。RPL在有良好但不完美的控制器的情况下,在复杂的机器人操作任务中繁忙发展。在这些任务中,从零到零的强化学习仍然是数据效率不高或难以操作的,但在初始控制器的顶端学习剩余部分可以产生很大的改进。我们在五项挑战性 MuJoC任务中研究了RPL,这五项任务涉及部分易懂性、感应噪音、模型偏差以及控制器的错误校正。通过将学习与控制算法相结合,RPL可以完成长期和稀疏的任务,只有强化学习才能成功。此外,我们发现在初始控制器上不断和大幅度改进RPL。我们争论说,RPL是将深度强化学习和机器人控制的互补优势结合起来的有希望的方法,可以推开两者中任何一个独立实现的目标的界限。