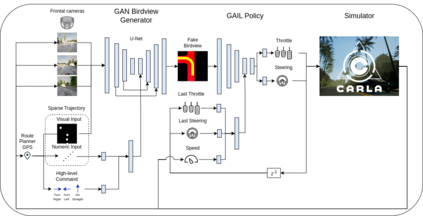
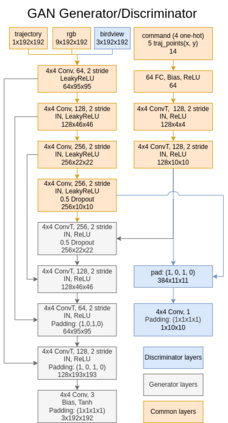
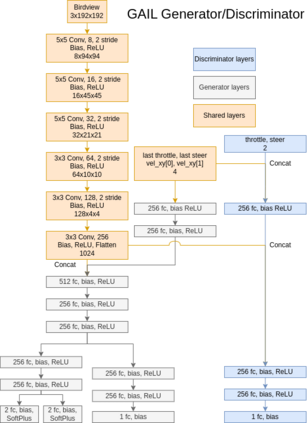
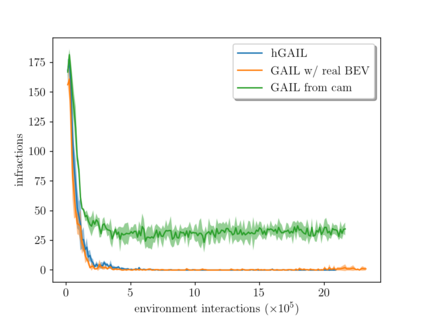
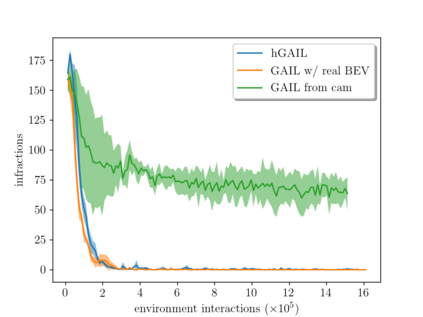
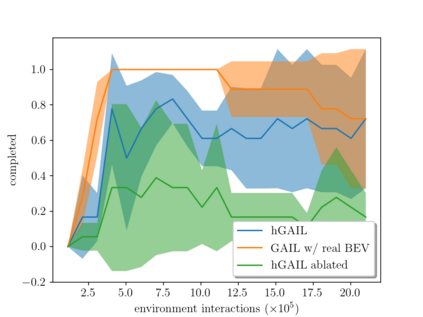
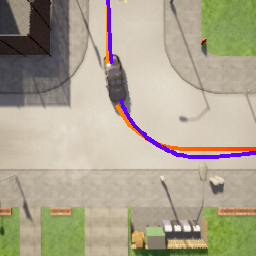
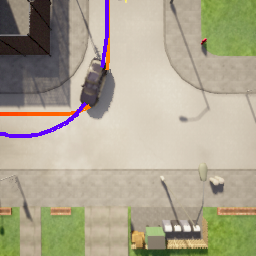
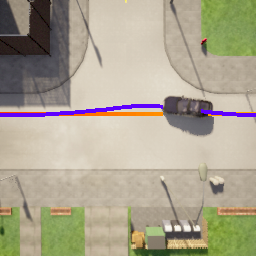
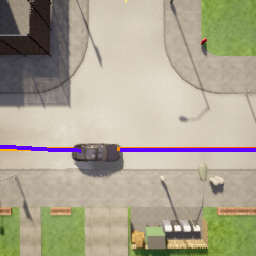
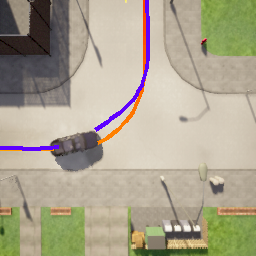
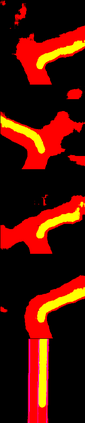
Deriving robust control policies for realistic urban navigation scenarios is not a trivial task. In an end-to-end approach, these policies must map high-dimensional images from the vehicle's cameras to low-level actions such as steering and throttle. While pure Reinforcement Learning (RL) approaches are based exclusively on rewards,Generative Adversarial Imitation Learning (GAIL) agents learn from expert demonstrations while interacting with the environment, which favors GAIL on tasks for which a reward signal is difficult to derive. In this work, the hGAIL architecture was proposed to solve the autonomous navigation of a vehicle in an end-to-end approach, mapping sensory perceptions directly to low-level actions, while simultaneously learning mid-level input representations of the agent's environment. The proposed hGAIL consists of an hierarchical Adversarial Imitation Learning architecture composed of two main modules: the GAN (Generative Adversarial Nets) which generates the Bird's-Eye View (BEV) representation mainly from the images of three frontal cameras of the vehicle, and the GAIL which learns to control the vehicle based mainly on the BEV predictions from the GAN as input.Our experiments have shown that GAIL exclusively from cameras (without BEV) fails to even learn the task, while hGAIL, after training, was able to autonomously navigate successfully in all intersections of the city.
翻译:暂无翻译