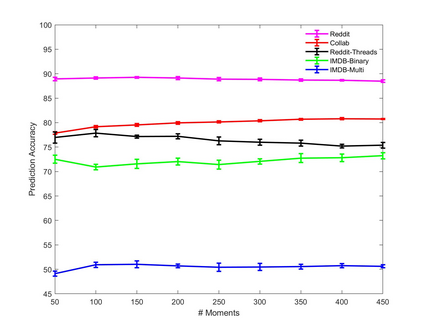
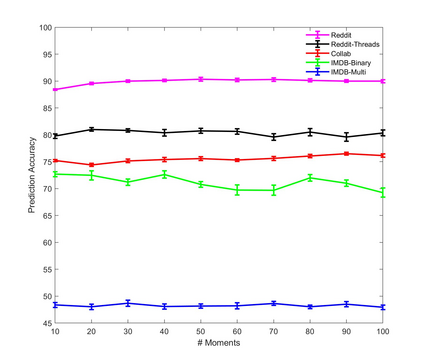
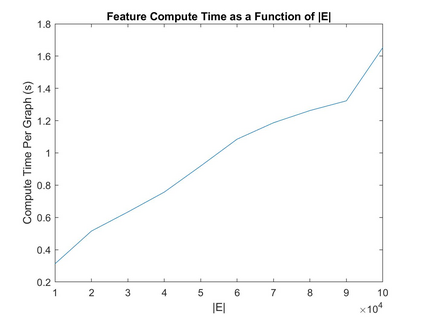
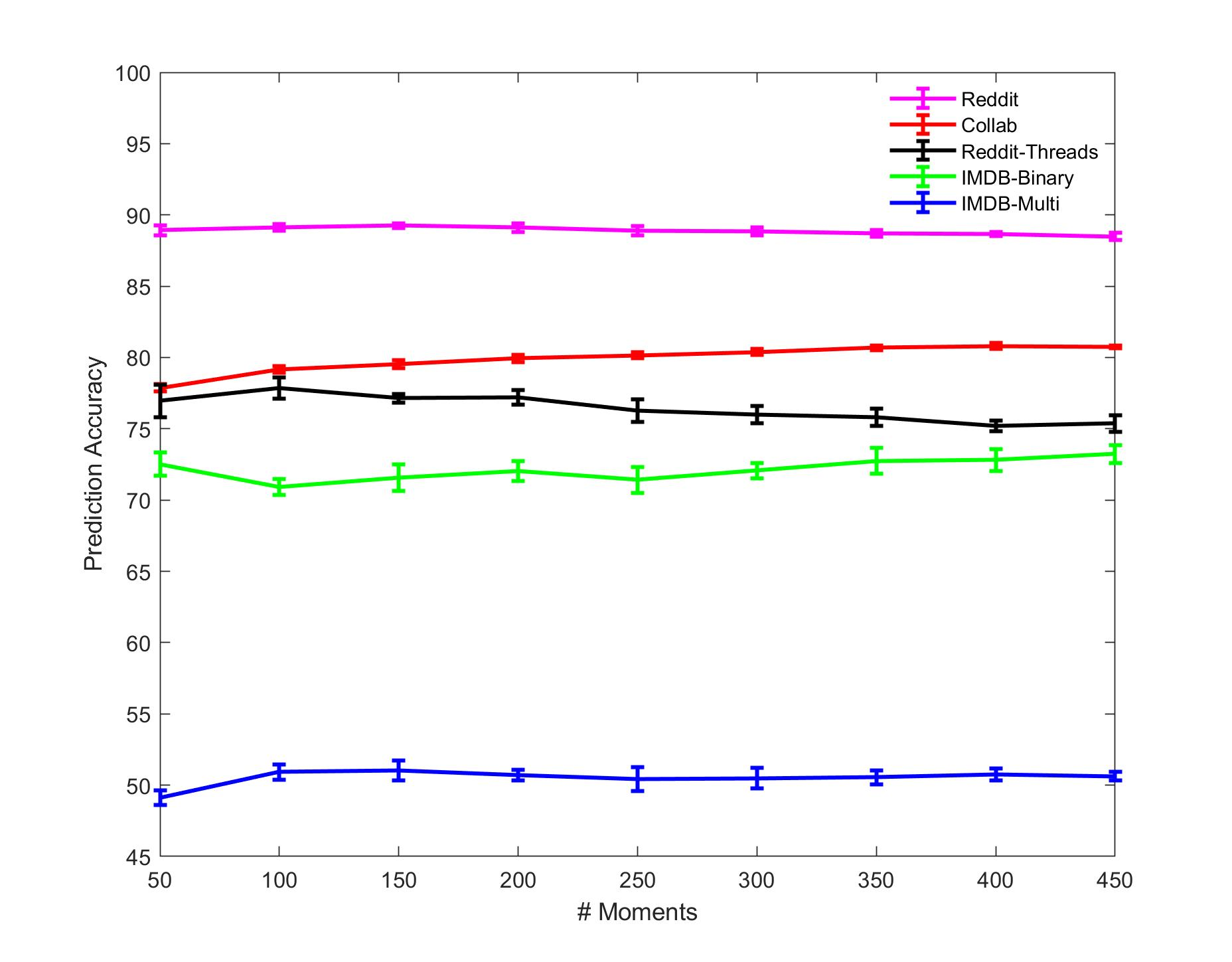
A fundamental problem on graph-structured data is that of quantifying similarity between graphs. Graph kernels are an established technique for such tasks; in particular, those based on random walks and return probabilities have proven to be effective in wide-ranging applications, from bioinformatics to social networks to computer vision. However, random walk kernels generally suffer from slowness and tottering, an effect which causes walks to overemphasize local graph topology, undercutting the importance of global structure. To correct for these issues, we recast return probability graph kernels under the more general framework of density of states -- a framework which uses the lens of spectral analysis to uncover graph motifs and properties hidden within the interior of the spectrum -- and use our interpretation to construct scalable, composite density of states based graph kernels which balance local and global information, leading to higher classification accuracies on a host of benchmark datasets.
翻译:图表结构数据的根本问题是图表结构数据之间的相似性。 图形内核是完成此类任务的既定技术; 特别是, 以随机行走和返回概率为基础的内核被证明在从生物信息学到社交网络到计算机视觉的广泛应用中是有效的。 然而, 随机行进内核一般会受到缓慢和乱七八糟的影响,这种影响导致过份强调本地图形表层,从而削弱了全球结构的重要性。 为了纠正这些问题,我们在国家密度这一更为普遍的框架下重新投放回概率图内核 -- -- 这个框架利用光谱分析的透镜来发现光谱内隐藏的图示和特性 -- -- 并使用我们的解释来构建基于图形内核的可缩放性、复合密度,从而平衡当地和全球信息,从而导致对一组基准数据集进行更高程度的分类。