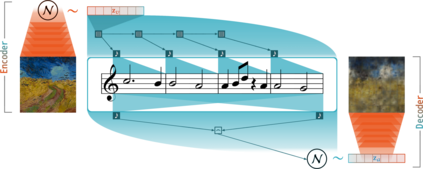
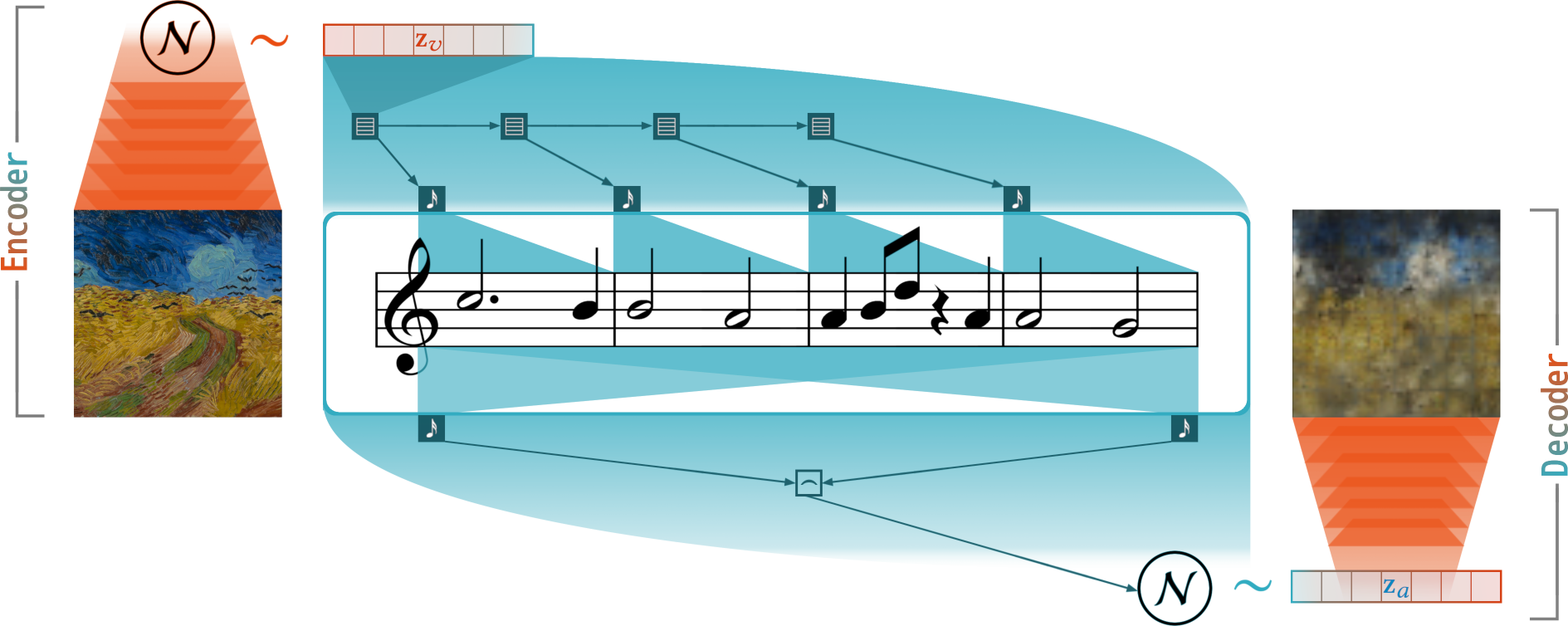
The Synesthetic Variational Autoencoder (SynVAE) introduced in this research is able to learn a consistent mapping between visual and auditive sensory modalities in the absence of paired datasets. A quantitative evaluation on MNIST as well as the Behance Artistic Media dataset (BAM) shows that SynVAE is capable of retaining sufficient information content during the translation while maintaining cross-modal latent space consistency. In a qualitative evaluation trial, human evaluators were furthermore able to match musical samples with the images which generated them with accuracies of up to 73%.
翻译:这项研究中引入的合成审美变异自动编码器(SynVAE)能够在没有配对数据集的情况下,在视觉和审计感知模式之间取得一致的制图。对MNIST和Behance艺术媒体数据集的定量评价表明,SynVAE能够在翻译过程中保留足够的信息内容,同时保持跨模式潜藏空间的一致性。在定性评价试验中,人类评价员还能够将音乐样品与产生这些样品的图像相匹配,其精密度高达73%。