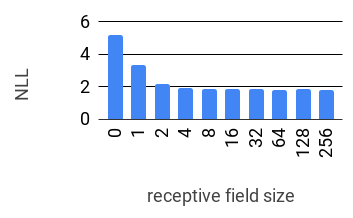
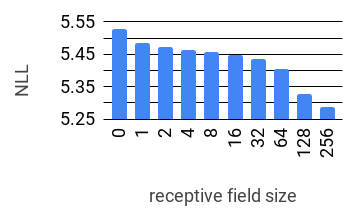
Realistic music generation is a challenging task. When building generative models of music that are learnt from data, typically high-level representations such as scores or MIDI are used that abstract away the idiosyncrasies of a particular performance. But these nuances are very important for our perception of musicality and realism, so in this work we embark on modelling music in the raw audio domain. It has been shown that autoregressive models excel at generating raw audio waveforms of speech, but when applied to music, we find them biased towards capturing local signal structure at the expense of modelling long-range correlations. This is problematic because music exhibits structure at many different timescales. In this work, we explore autoregressive discrete autoencoders (ADAs) as a means to enable autoregressive models to capture long-range correlations in waveforms. We find that they allow us to unconditionally generate piano music directly in the raw audio domain, which shows stylistic consistency across tens of seconds.
翻译:现实音乐的产生是一项具有挑战性的任务。 当建立从数据中学习的音乐的基因模型时, 典型的高层代表, 比如分数或MIDI, 被使用, 抽象地排除了某种表演的特异性。 但是这些细微差别对于我们对音乐和现实主义的感知非常重要, 因此在这项工作中, 我们开始在原始音频域模拟音乐。 已经证明, 自动递减模型在产生原始音频波形式方面非常出色, 但是当应用到音乐时, 我们发现它们偏向于捕捉当地信号结构, 而忽略了模拟远程关联。 这有问题, 因为音乐展览结构在不同的时间尺度上。 在这项工作中, 我们探索自动递增的离心自动立器( ADADs), 作为一种工具, 使自动递增模型能够捕捉波形中的长距离相关性。 我们发现, 它们允许我们无条件地直接在原始音域中生成钢琴音乐, 显示时, 数十秒的音调一致性。