【论文推荐】最新五篇视觉问答相关论文—深度学习评价、交互注意融合、VizWiz、引导注意力、
【导读】专知内容组既昨天推出六篇视觉问答(Visual Question Answering, VQA)相关论文,今天为大家推出最新五篇视觉问答相关论文,欢迎查看!
8.Did the Model Understand the Question?(模型理解问题了吗?)
作者:Pramod Kaushik Mudrakarta,Ankur Taly,Mukund Sundararajan,Kedar Dhamdhere
ACL 2018 long paper
机构:University of Chicago
摘要:We analyze state-of-the-art deep learning models for three tasks: question answering on (1) images, (2) tables, and (3) passages of text. Using the notion of \emph{attribution} (word importance), we find that these deep networks often ignore important question terms. Leveraging such behavior, we perturb questions to craft a variety of adversarial examples. Our strongest attacks drop the accuracy of a visual question answering model from $61.1\%$ to $19\%$, and that of a tabular question answering model from $33.5\%$ to $3.3\%$. Additionally, we show how attributions can strengthen attacks proposed by Jia and Liang (2017) on paragraph comprehension models. Our results demonstrate that attributions can augment standard measures of accuracy and empower investigation of model performance. When a model is accurate but for the wrong reasons, attributions can surface erroneous logic in the model that indicates inadequacies in the test data.

期刊:arXiv, 2018年5月15日
网址:
http://www.zhuanzhi.ai/document/0851e20a331fc05fcd7228666f3b7539
9.Deep learning evaluation using deep linguistic processing(使用深度语言处理的深度学习评价)
作者:Alexander Kuhnle,Ann Copestake
机构:University of Cambridge
摘要:We discuss problems with the standard approaches to evaluation for tasks like visual question answering, and argue that artificial data can be used to address these as a complement to current practice. We demonstrate that with the help of existing 'deep' linguistic processing technology we are able to create challenging abstract datasets, which enable us to investigate the language understanding abilities of multimodal deep learning models in detail, as compared to a single performance value on a static and monolithic dataset.

期刊:arXiv, 2018年5月12日
网址:
http://www.zhuanzhi.ai/document/09d0309bd825aacee63502631c317504
10.Reciprocal Attention Fusion for Visual Question Answering(视觉问题回答的交互注意融合)
作者:Moshiur R Farazi,Salman Khan
机构:Australian National University
摘要:Existing attention mechanisms either attend to local image grid or object level features for Visual Question Answering (VQA). Motivated by the observation that questions can relate to both object instances and their parts, we propose a novel attention mechanism that jointly considers reciprocal relationships between the two levels of visual details. The bottom-up attention thus generated is further coalesced with the top-down information to only focus on the scene elements that are most relevant to a given question. Our design hierarchically fuses multi-modal information i.e., language, object- and gird-level features, through an efficient tensor decomposition scheme. The proposed model improves the state-of-the-art single model performances from 67.9% to 68.2% on VQAv1 and from 65.3% to 67.4% on VQAv2, demonstrating a significant boost.
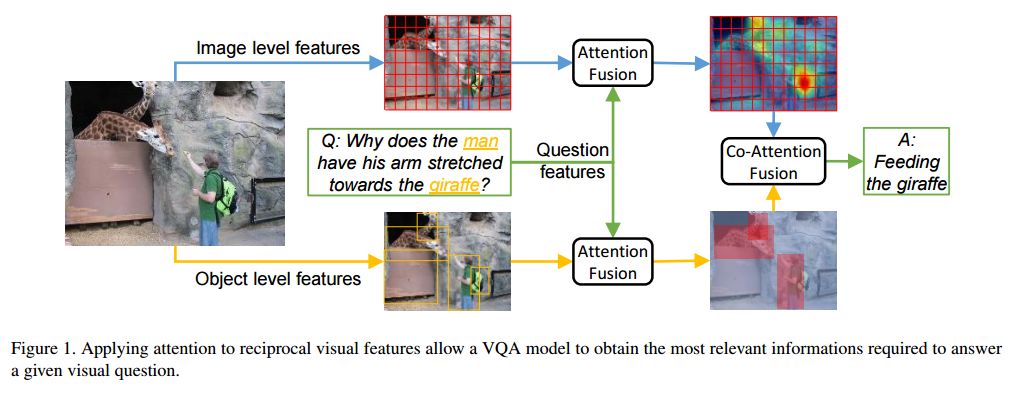
期刊:arXiv, 2018年5月11日
网址:
http://www.zhuanzhi.ai/document/3e4851d75cdd3c9e57d95bf61ad183a2
11.VizWiz Grand Challenge: Answering Visual Questions from Blind People(VizWiz Grand Challenge:回答盲人的视觉问题)
作者:Danna Gurari,Qing Li,Abigale J. Stangl,Anhong Guo,Chi Lin,Kristen Grauman,Jiebo Luo,Jeffrey P. Bigham
机构:University of Texas at Austin,University of Science and Technology of China,University of Colorado Boulder,Carnegie Mellon University,University of Rochester
摘要:The study of algorithms to automatically answer visual questions currently is motivated by visual question answering (VQA) datasets constructed in artificial VQA settings. We propose VizWiz, the first goal-oriented VQA dataset arising from a natural VQA setting. VizWiz consists of over 31,000 visual questions originating from blind people who each took a picture using a mobile phone and recorded a spoken question about it, together with 10 crowdsourced answers per visual question. VizWiz differs from the many existing VQA datasets because (1) images are captured by blind photographers and so are often poor quality, (2) questions are spoken and so are more conversational, and (3) often visual questions cannot be answered. Evaluation of modern algorithms for answering visual questions and deciding if a visual question is answerable reveals that VizWiz is a challenging dataset. We introduce this dataset to encourage a larger community to develop more generalized algorithms that can assist blind people.
期刊:arXiv, 2018年5月10日
网址:
http://www.zhuanzhi.ai/document/3a6116d0d7b4f29153b220e7de0745d3
12.Guided Attention for Large Scale Scene Text Verification(大规模场景文本验证的引导注意力)
作者:Dafang He,Yeqing Li,Alexander Gorban,Derrall Heath,Julian Ibarz,Qian Yu,Daniel Kifer,C. Lee Giles
机构:The Pennsylvania State University
摘要:Many tasks are related to determining if a particular text string exists in an image. In this work, we propose a new framework that learns this task in an end-to-end way. The framework takes an image and a text string as input and then outputs the probability of the text string being present in the image. This is the first end-to-end framework that learns such relationships between text and images in scene text area. The framework does not require explicit scene text detection or recognition and thus no bounding box annotations are needed for it. It is also the first work in scene text area that tackles suh a weakly labeled problem. Based on this framework, we developed a model called Guided Attention. Our designed model achieves much better results than several state-of-the-art scene text reading based solutions for a challenging Street View Business Matching task. The task tries to find correct business names for storefront images and the dataset we collected for it is substantially larger, and more challenging than existing scene text dataset. This new real-world task provides a new perspective for studying scene text related problems. We also demonstrate the uniqueness of our task via a comparison between our problem and a typical Visual Question Answering problem.
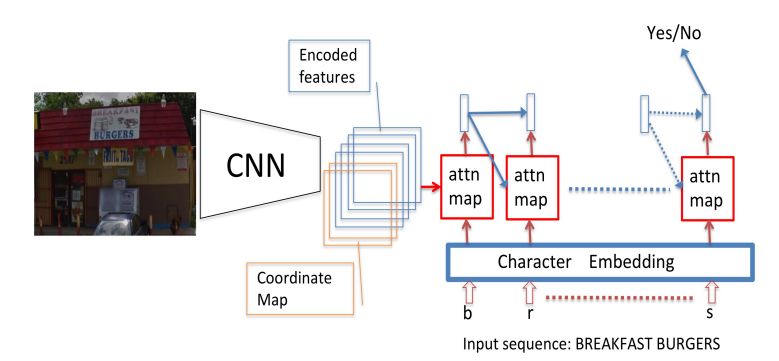
期刊:arXiv, 2018年4月24日
网址:
http://www.zhuanzhi.ai/document/3062537c307bfe8eee23308ae822e746
-END-
专 · 知
人工智能领域主题知识资料查看与加入专知人工智能服务群:
【专知AI服务计划】专知AI知识技术服务会员群加入与人工智能领域26个主题知识资料全集获取。欢迎微信扫一扫加入专知人工智能知识星球群,获取专业知识教程视频资料和与专家交流咨询!

请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请加专知小助手微信(扫一扫如下二维码添加),加入专知主题群(请备注主题类型:AI、NLP、CV、 KG等)交流~

请关注专知公众号,获取人工智能的专业知识!
点击“阅读原文”,使用专知





