【论文推荐】最新六篇视觉问答(VQA)相关论文—盲人问题、物体计数、多模态解释、视觉关系、对抗性网络、对偶循环注意力
【导读】专知内容组整理了最近六篇视觉问答(Visual Question Answering)相关文章,为大家进行介绍,欢迎查看!
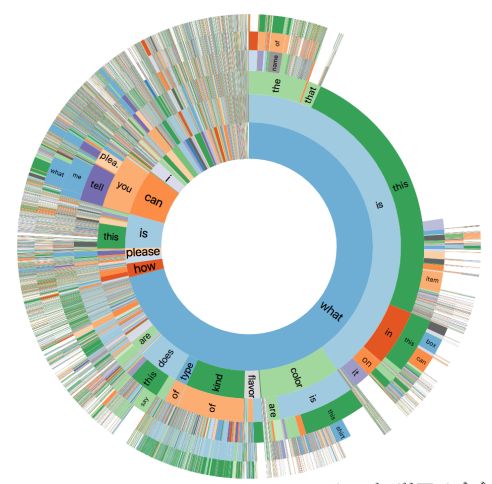
1. VizWiz Grand Challenge: Answering Visual Questions from Blind People(VizWiz Grand Challenge:回答来自于盲人的视觉问题)
作者:Danna Gurari,Qing Li,Abigale J. Stangl,Anhong Guo,Chi Lin,Kristen Grauman,Jiebo Luo,Jeffrey P. Bighamv
摘要:The study of algorithms to automatically answer visual questions currently is motivated by visual question answering (VQA) datasets constructed in artificial VQA settings. We propose VizWiz, the first goal-oriented VQA dataset arising from a natural VQA setting. VizWiz consists of over 31,000 visual questions originating from blind people who each took a picture using a mobile phone and recorded a spoken question about it, together with 10 crowdsourced answers per visual question. VizWiz differs from the many existing VQA datasets because (1) images are captured by blind photographers and so are often poor quality, (2) questions are spoken and so are more conversational, and (3) often visual questions cannot be answered. Evaluation of modern algorithms for answering visual questions and deciding if a visual question is answerable reveals that VizWiz is a challenging dataset. We introduce this dataset to encourage a larger community to develop more generalized algorithms that can assist blind people.
期刊:arXiv, 2018年2月23日
网址:
http://www.zhuanzhi.ai/document/b3f0b922c90530d80f8f197e0c3215e3
2. Learning to Count Objects in Natural Images for Visual Question Answering(学习自然图像中物体计数的视觉问答)
作者:Yan Zhang,Jonathon Hare,Adam Prügel-Bennettv
摘要:Visual Question Answering (VQA) models have struggled with counting objects in natural images so far. We identify a fundamental problem due to soft attention in these models as a cause. To circumvent this problem, we propose a neural network component that allows robust counting from object proposals. Experiments on a toy task show the effectiveness of this component and we obtain state-of-the-art accuracy on the number category of the VQA v2 dataset without negatively affecting other categories, even outperforming ensemble models with our single model. On a difficult balanced pair metric, the component gives a substantial improvement in counting over a strong baseline by 6.6%.
期刊:arXiv, 2018年2月16日
网址:
http://www.zhuanzhi.ai/document/3ff64a12875f66714212ee79d36be677
3. Multimodal Explanations: Justifying Decisions and Pointing to the Evidence(多模态解释: 为决策辩护并指出证据)
作者:Dong Huk Park,Lisa Anne Hendricks,Zeynep Akata,Anna Rohrbach,Bernt Schiele,Trevor Darrell,Marcus Rohrbach
摘要:Deep models that are both effective and explainable are desirable in many settings; prior explainable models have been unimodal, offering either image-based visualization of attention weights or text-based generation of post-hoc justifications. We propose a multimodal approach to explanation, and argue that the two modalities provide complementary explanatory strengths. We collect two new datasets to define and evaluate this task, and propose a novel model which can provide joint textual rationale generation and attention visualization. Our datasets define visual and textual justifications of a classification decision for activity recognition tasks (ACT-X) and for visual question answering tasks (VQA-X). We quantitatively show that training with the textual explanations not only yields better textual justification models, but also better localizes the evidence that supports the decision. We also qualitatively show cases where visual explanation is more insightful than textual explanation, and vice versa, supporting our thesis that multimodal explanation models offer significant benefits over unimodal approaches.

期刊:arXiv, 2018年2月16日
网址:
http://www.zhuanzhi.ai/document/7f6829afe611d3daa20a53b9a1b7d9be
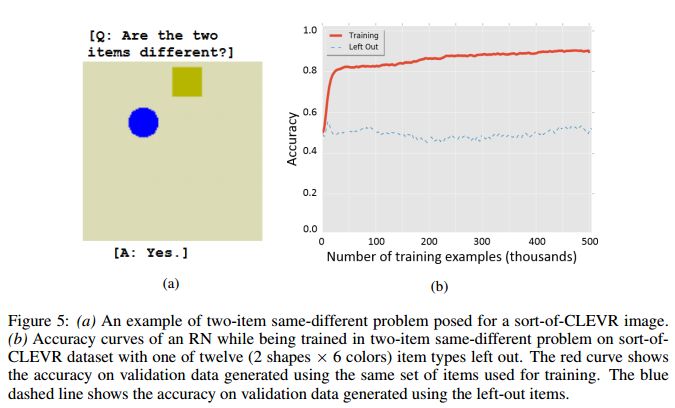
4. Not-So-CLEVR:Visual Relations Strain Feedforward Neural Networks(Not-So-CLEVR:视觉关系应变前馈神经网络)
作者:Matthew Ricci,Junkyung Kim,Thomas Serre
摘要:The robust and efficient recognition of visual relations in images is a hallmark of biological vision. Here, we argue that, despite recent progress in visual recognition, modern machine vision algorithms are severely limited in their ability to learn visual relations. Through controlled experiments, we demonstrate that visual-relation problems strain convolutional neural networks (CNNs). The networks eventually break altogether when rote memorization becomes impossible such as when the intra-class variability exceeds their capacity. We further show that another type of feedforward network, called a relational network (RN), which was shown to successfully solve seemingly difficult visual question answering (VQA) problems on the CLEVR datasets, suffers similar limitations. Motivated by the comparable success of biological vision, we argue that feedback mechanisms including working memory and attention are the key computational components underlying abstract visual reasoning.
期刊:arXiv, 2018年2月13日
网址:
http://www.zhuanzhi.ai/document/29c9b137a6891efa4779acadea135e2c
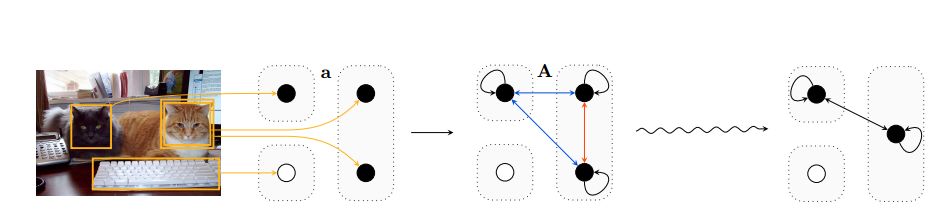
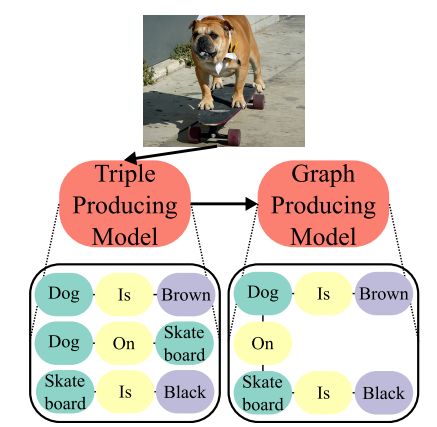
5. Generating Triples with Adversarial Networks for Scene Graph Construction(基于对抗性网络的三元组生成的场景图重建)
作者:Matthew Klawonn,Eric Heim
摘要:Driven by successes in deep learning, computer vision research has begun to move beyond object detection and image classification to more sophisticated tasks like image captioning or visual question answering. Motivating such endeavors is the desire for models to capture not only objects present in an image, but more fine-grained aspects of a scene such as relationships between objects and their attributes. Scene graphs provide a formal construct for capturing these aspects of an image. Despite this, there have been only a few recent efforts to generate scene graphs from imagery. Previous works limit themselves to settings where bounding box information is available at train time and do not attempt to generate scene graphs with attributes. In this paper we propose a method, based on recent advancements in Generative Adversarial Networks, to overcome these deficiencies. We take the approach of first generating small subgraphs, each describing a single statement about a scene from a specific region of the input image chosen using an attention mechanism. By doing so, our method is able to produce portions of the scene graphs with attribute information without the need for bounding box labels. Then, the complete scene graph is constructed from these subgraphs. We show that our model improves upon prior work in scene graph generation on state-of-the-art data sets and accepted metrics. Further, we demonstrate that our model is capable of handling a larger vocabulary size than prior work has attempted.
期刊:arXiv, 2018年2月8日
网址:
http://www.zhuanzhi.ai/document/763768a819284a56ccacadf3ba890310
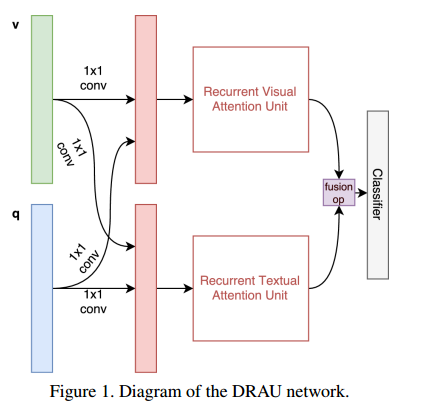
6. Dual Recurrent Attention Units for Visual Question Answering(基于对偶循环注意力单元的视觉问答)
作者:Ahmed Osman,Wojciech Samek
摘要:We propose an architecture for VQA which utilizes recurrent layers to generate visual and textual attention. The memory characteristic of the proposed recurrent attention units offers a rich joint embedding of visual and textual features and enables the model to reason relations between several parts of the image and question. Our single model outperforms the first place winner on the VQA 1.0 dataset, performs within margin to the current state-of-the-art ensemble model. We also experiment with replacing attention mechanisms in other state-of-the-art models with our implementation and show increased accuracy. In both cases, our recurrent attention mechanism improves performance in tasks requiring sequential or relational reasoning on the VQA dataset.
期刊:arXiv, 2018年2月1日
网址:
http://www.zhuanzhi.ai/document/81c316a4bd80772d930327ca3ce46f1b
-END-
专 · 知
人工智能领域主题知识资料查看获取:【专知荟萃】人工智能领域26个主题知识资料全集(入门/进阶/论文/综述/视频/专家等)
同时欢迎各位用户进行专知投稿,详情请点击:
【诚邀】专知诚挚邀请各位专业者加入AI创作者计划!了解使用专知!
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

请加专知小助手微信(Rancho_Fang),加入专知主题人工智能群交流!
点击“阅读原文”,使用专知!





