行人再识别中的迁移学习:图像风格转换(Learning via Translation)

论文:Image-Image Domain Adaptation with Preserved Self-Similarity and Domain-Dissimilarity for Person Re-identification(链接:https://arxiv.org/pdf/1711.07027.pdf)
1 背景介绍
行人再识别(Person re-identification, re-ID)的核心目标是判断图像或者视频序列中是否存在特定行人。近年来,伴随着大数据集合(Market-1501【1】,DukeMTMC-reID 【2】等)的出现以及深度卷积神经网(ResNet【3】,GoogleNet【4】等)的发展,re-ID的性能不断攀升。那么,re-ID模型在跨数据集下的性能表现会是怎么样的?
由于不同数据集合之间的差异(dataset bias)【5】,在一个数据集合上训练的模型直接应用于另外一个数据集合上的时候,re-ID性能会出现大幅度的下降。《Image-Image Domain Adaptation with Preserved Self-Similarity and Domain-Dissimilarity for Person Re-identification》这篇论文探究re-ID模型在跨数据集合的性能表现,并构建了“Learning via Translation”的框架来进行不同数据集合之间的迁移学习。
2 方法综述
假设给定源域 S(source domain)上带标签的数据集合,以及目标域 T(target domain)上没有带标签的数据集合。迁移学习的目标是让在S域上训练的re-ID模型能很好地在T域上应用。为此,该论文提出“Learning via Translation”的框架。

图1 Learning via Translation框架流程图
图1为Learning via Translation框架流程图,该框架分为两个步骤:
Source-target Translation 首先,将S域上带标签的训练数据的风格迁移到T域的风格之上;
Feature Learning 其次,利用风格迁移后的训练数据,训练出一个re-ID模型。由于该模型是利用风格为T域上的数据训练的,所以能很好地在T域上使用。
该论文重点探究了第一个步骤,针对re-ID问题提出了Source-target Translation的方法:Similarity Preserving cycle-consistent Generative Adversarial Network (SPGAN)。由于迁移之后的图像是用于re-ID模型的训练,因此该论文提出了SPGAN。其的核心是:图像迁移前后能保持其ID信息不变。为了实现该目的,SPGAN构建了无监督的Self-Similarity和Domain-Dissimilarity关系来约束Source-target Translation的学习。
下面将对SPGAN做一个详细介绍。
3 SPGAN
3.1 图像风格化(Image-to-image translation)

图2 DukeMTMC-reID 和 Market-1501 图像示例
图2为分别来自于Duke和Market的图像示例,可以观察到两个数据集合有着很大的风格差异,具体体现在不同光照、背景、季节(duke拍摄于冬季、Market拍摄于夏季)等上。基于数据集合风格差异的观察,作者从图像风格迁移的角度来对re-ID的迁移学习进行探索:
(1)、如果来自于源域S 的图像,风格迁移到目标域T 之后,迁移之后的图像的风格要和目标域的风格一致;
(2)、图像迁移前后需要保持它本身的ID信息不变。这种ID信息不是图像的背景或图像的风格,而是和ID信息有潜在关系的图像行人区域。(作者在文中是这样表述的: the visual content associated with the ID label of an image should be preserved after image-image translation. In our scenario, such visual content usually refers to the underlying (latent) ID information for a foreground pedestrian)
针对第一点,数据集合之间的Image-to-Image Translation,由于Duke和Market两个数据集合没有一一对应的标签信息(也就是来自一个数据的图像风格迁移到另外一个数据应该是什么样的图像对信息)。作者采用了CycleGAN【6】来实现Unpaired Image-to-Image Translation。(CycleGAN、DualGAN【7】、DiscoGAN【8】是孪生三姐妹,同样采用cycle-consistent loss来约束两个数据分布之间转换关系的学习,这里不再赘述)
此外,作者还引入了 target domain identity loss【9】来进一步约束源域S 和目标域T 之间映射关系的学习 。该loss具体为:假定一个generator是从域S 映射到域T ,那么来自于域T 的样本通过该generator得到的还是该样本。公式1为target domain identity loss。作者实验发现,该loss能够使得迁移前后的图像在颜色组成上保持一致。
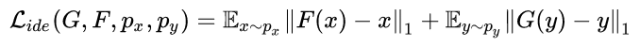
3.2 SPGAN
针对第二点,基于re-ID问题,作者构建了无监督的Self-Similarity和Domain-Dissimilarity关系来约束Source-target Translation的学习。具体介绍如下:
Self-Similarity 一张图像迁移前后需要让ID相关的图像保持不变。那么,一张图迁移前和迁移后的特征距离需要越近越好。
Domain-Dissimilarity 针对re-ID的跨数据集合迁移问题,由于两个数据集合里面图像的ID是不一样的(也就是 source and target domains contain the different set of classes),那么一张图A从域S 迁移到域T 之后的图像G(A),要和域T 中的任意一张图像在特征距离上远离一些(同样,一张图B从域T 迁移到域S 之后的图像F(B),要和域S 中的任意一张图像在特征距离上远离一些)。图3给出了Self-Similarity和Domain-Dissimilarity关系的示意图。
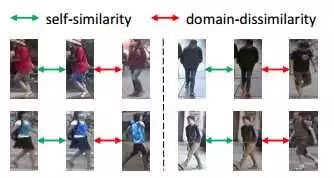
图3 Self-Similarity和Domain-Dissimilarity关系示意图
基于上述两点,作者在CycleGAN的基础上嵌入了一个Siamese Network,Self-Similarity和Domain-Dissimilarity刚好可以采用contrastive loss【10】来进行训练。
公式2为contrastive loss,x1 和 x2 为输入的图像样本对,i 为输入图像对的标签,i 为1表示是输入的图像对是正例对,i 为0表示是输入的图像对是反例对,m 表示反例对之间距离margin,d 为两个输入样本的欧式距离: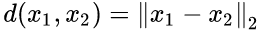
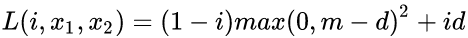
值得注意的是,样本对的选取方式是无监督的。给定 G,将图像从源域S 映射到目标域T;给定F ,将图像从目标域T 映射到源域S ;有来自于目标域T 和源域S 的图像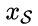
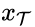
正例对: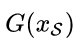
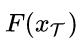
负例对:
每一次迭代的时候,都可以构造出上述的样本对,该样本对不需要额外的标记信息。SPGAN可以划分为三个部分:Discriminator、Generator、SiaNet,在训练的时候三个部分交替更新:更新D的时候固定G和S,更新G的时候固定D和S,更新S的时候固定D和G。
3.3 Feature Learning
Learning via Translation 框架的第二步是特征学习。将源域S 带标签的数据风格转换到目标T 之后,可以利用转换后的数据训练re-ID模型。作者的核心是第一个步骤,因此特征学习的方式,作者直接采用采用了IDE【11】来训练re-ID模型,IDE是基于ResNet-50修改的,只根据训练数据的类别数目修改了输出节点,其他的结构不变。训练好IDE之后,作者提取ResNet-50的Pool5特征来做图像的描述子,采用欧式距离进行检索。
此外作者提出了LMP (Local Max Pooling)来进一步提升re-ID模型在target dataset上性能的方式。LMP不需要训练,只需要在测试的时候直接使用就行。如图4所示,LMP先把ResNet-50的CONV5特征按overlap为一个像素的方式划分成P(图4中P为2)个部分,然后分别对P个部分做Global Max Pooling (GMP),最后concatenate P个pooling的结果作为最后的图像描述子。实验表明,P最大为6时性能最好,为此作者在实验时P都取6。(值得注意的是,当P=1且采用Global Average Pooling的时候,得到的是ResNet-50的Pool5特征)
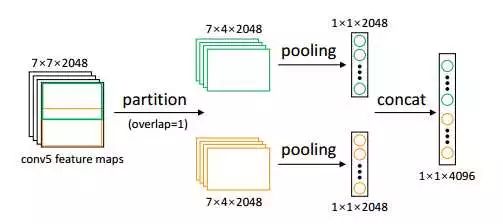
图4 LMP示意图
4 图像探究
4.1 图像风格化结果

图5 不同模型图像风格相互迁移实例图
图5展示了不同模型在Marke和Duke图像之间风格相互迁移的效果图:(a)为输入图像、(b)为cyclegan模型的效果图、(c)为CycleGAN+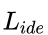
另外就是用SPGAN对Market图像和Duke图像风格相互迁移效果图,如图6所示。视觉感受上,能把Market和Duke的图像风格进行一个图像风格上的相互迁移。

图6 SPGAN对Market和Duke图像风格相互转换效果图
4.2 实验分析
下面介绍作者的定量实验。作者在Market-1501和DukeMTMC-reID两个数据集合上做了re-ID实验验证。
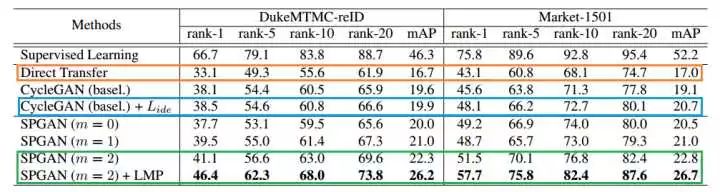
表1 Market和Duke跨域迁移性能对比表
从表1中,我们可以获取到很多信息,下面将相应阐述:
数据集合之间的dataset bias使得re-ID模型在跨数据集时的性能下降很剧烈 表1中,当Duke上训练的模型在Duke上测试的时候,rank-1 有66.7%,但是把Duke上训练的模型用在Market上测试的时候,性能只有43.1%。同样的情况也能从Market-->Duke上观察到;
Learning via Translation方法的有效性 通过对比Direct transfer(在源域S 上训练的模型直接用于目标域T ),CycleGAN以及CycleGAN+
都有性能上的提升,这说明Learning via Translation的方式对于re-ID任务是有效的。此外,CycleGAN+
相比于CycleGAN,在Duke上性能基本持平而在Market上性能表现更好一些,原因可能是Duke-->Market的时候难度稍微大一些,
能帮助模型去实现图像风格的转换。
SPGAN的有效性 相比于CycleGAN以及CycleGAN+
,SPGAN有者进一步的性能提升,这说明作者在训练CycleGAN的过程中加入Self-Similarity和Domain-Dissimilarity的有效性。另外作者还对公式3中的margin这个参数做了探究,发现m=2的时候性能会高一些,也就是要求负样本对距离要尽量远离。(当m=0的时候,相当于不考虑负样本对,这个时候loss退化到了content loss【13】,作者没有进一步探究)
LMP能进一步提升re-ID性能 可以看出LMP能使训练好的模型在性能上进一步提升。(作者在文中也对比了全监督和迁移学习情况下,LMP的有效性,发现LMP只对迁移学习的情况有效)
更多实验请查看作者论文。
5 小结
re-ID中的迁移学习 - 由于数据集合间的差异,在一个数据集合上训练好的re-ID模型在另外一个数据性能上下降很厉害;其次,re-ID数据的标定很耗费人力物力,那么让在已有标记数据上训练好的模型能够用于其他场景符合实际的需求。迁移学习下的re-ID还是一个开放问题,期待更多工作对其进行相关研究;
Learning via Translation - 作者针对re-ID的迁移学习,从图像风格转换角度构建了Learning via Translation的基础框架,并通过实验验证了该框架的有效性。此外,作者针对该框架的核心部分(第一步图像风格转换),提出了SPGAN,进一步提升框架的性能。那么,是否会存在其他re-ID迁移学习的解决方案呢?期待更多人回答。
扩展阅读,论文采用的图像风格转换是建立在两个数据集合上的,那么多个数据集合能不能同时进行转换呢?或许这个论文给出来答案:StarGAN【13】(论文链接:https://github.com/yunjey/StarGAN)。来源:行人重识别 - 知乎专栏



