【论文推荐】最新六篇行人再识别(ReID)相关论文—和谐注意力网络、时序残差学习、评估和基准、图像生成、三元组、对抗属性-图像
【导读】专知内容组整理了最近六篇行人再识别(Person Re-Identification)相关文章,为大家进行介绍,欢迎查看!
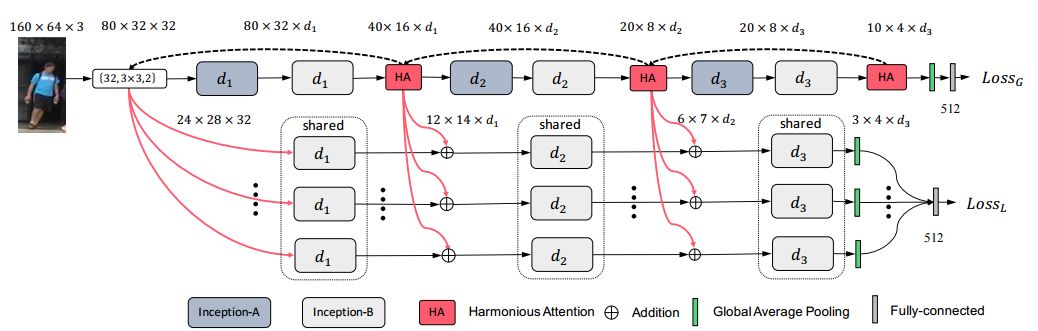
1. Harmonious Attention Network for Person Re-Identification(和谐注意力网络的行人再识别)
作者:Wei Li,Xiatian Zhu,Shaogang Gong
摘要:Existing person re-identification (re-id) methods either assume the availability of well-aligned person bounding box images as model input or rely on constrained attention selection mechanisms to calibrate misaligned images. They are therefore sub-optimal for re-id matching in arbitrarily aligned person images potentially with large human pose variations and unconstrained auto-detection errors. In this work, we show the advantages of jointly learning attention selection and feature representation in a Convolutional Neural Network (CNN) by maximising the complementary information of different levels of visual attention subject to re-id discriminative learning constraints. Specifically, we formulate a novel Harmonious Attention CNN (HA-CNN) model for joint learning of soft pixel attention and hard regional attention along with simultaneous optimisation of feature representations, dedicated to optimise person re-id in uncontrolled (misaligned) images. Extensive comparative evaluations validate the superiority of this new HA-CNN model for person re-id over a wide variety of state-of-the-art methods on three large-scale benchmarks including CUHK03, Market-1501, and DukeMTMC-ReID.
期刊:arXiv, 2018年2月23日
网址:
http://www.zhuanzhi.ai/document/8de7cacc9829744baf6f1f62fc7bdc13
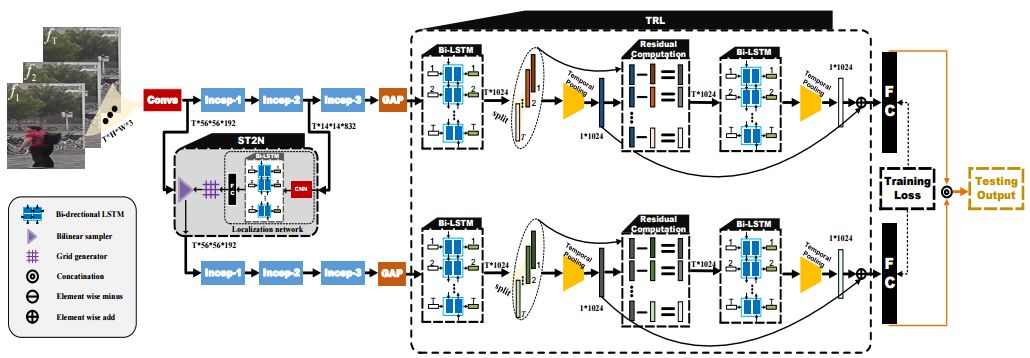
2. Video Person Re-identification by Temporal Residual Learning(基于时序残差学习机制的视频行人再识别)
作者:Ju Dai,Pingping Zhang,Huchuan Lu,Hongyu Wang
摘要:In this paper, we propose a novel feature learning framework for video person re-identification (re-ID). The proposed framework largely aims to exploit the adequate temporal information of video sequences and tackle the poor spatial alignment of moving pedestrians. More specifically, for exploiting the temporal information, we design a temporal residual learning (TRL) module to simultaneously extract the generic and specific features of consecutive frames. The TRL module is equipped with two bi-directional LSTM (BiLSTM), which are respectively responsible to describe a moving person in different aspects, providing complementary information for better feature representations. To deal with the poor spatial alignment in video re-ID datasets, we propose a spatial-temporal transformer network (ST^2N) module. Transformation parameters in the ST^2N module are learned by leveraging the high-level semantic information of the current frame as well as the temporal context knowledge from other frames. The proposed ST^2N module with less learnable parameters allows effective person alignments under significant appearance changes. Extensive experimental results on the large-scale MARS, PRID2011, ILIDS-VID and SDU-VID datasets demonstrate that the proposed method achieves consistently superior performance and outperforms most of the very recent state-of-the-art methods.
期刊:arXiv, 2018年2月22日
网址:
http://www.zhuanzhi.ai/document/35e9bad2861c1b00d01a1af4431041ec
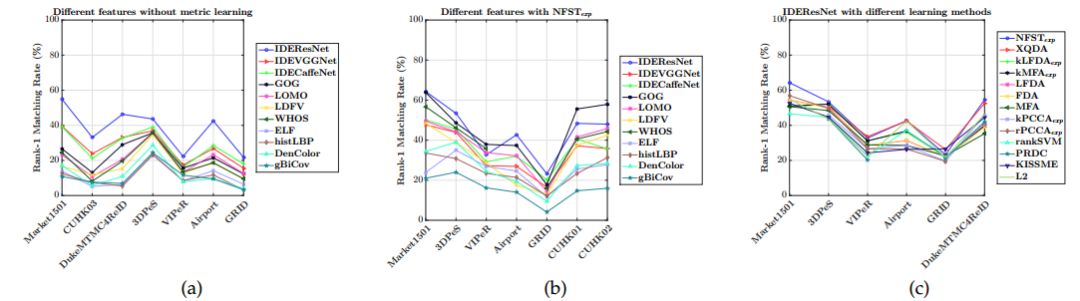
3. A Systematic Evaluation and Benchmark for Person Re-Identification: Features, Metrics, and Datasets(行人再识别的系统评估和基准:特性、度量和数据集)
作者:Srikrishna Karanam,Mengran Gou,Ziyan Wu,Angels Rates-Borras,Octavia Camps,Richard J. Radke
摘要:Person re-identification (re-id) is a critical problem in video analytics applications such as security and surveillance. The public release of several datasets and code for vision algorithms has facilitated rapid progress in this area over the last few years. However, directly comparing re-id algorithms reported in the literature has become difficult since a wide variety of features, experimental protocols, and evaluation metrics are employed. In order to address this need, we present an extensive review and performance evaluation of single- and multi-shot re-id algorithms. The experimental protocol incorporates the most recent advances in both feature extraction and metric learning. To ensure a fair comparison, all of the approaches were implemented using a unified code library that includes 11 feature extraction algorithms and 22 metric learning and ranking techniques. All approaches were evaluated using a new large-scale dataset that closely mimics a real-world problem setting, in addition to 16 other publicly available datasets: VIPeR, GRID, CAVIAR, DukeMTMC4ReID, 3DPeS, PRID, V47, WARD, SAIVT-SoftBio, CUHK01, CHUK02, CUHK03, RAiD, iLIDSVID, HDA+ and Market1501. The evaluation codebase and results will be made publicly available for community use.
期刊:arXiv, 2018年2月15日
网址:
http://www.zhuanzhi.ai/document/7bf2307d60a318b6c3a5b1f965995a4c
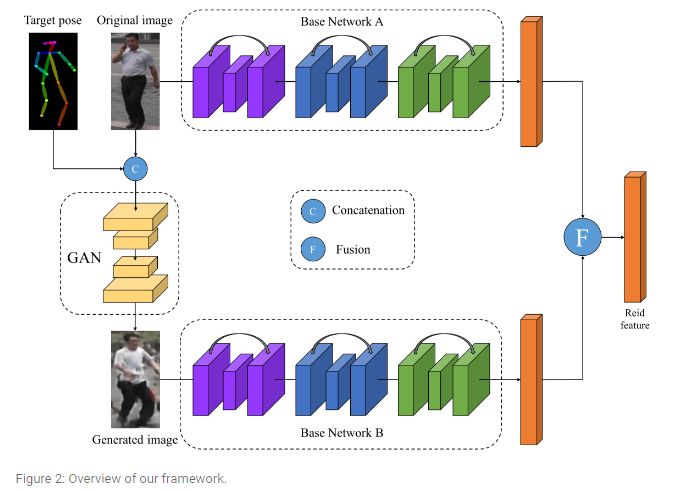
4. Pose-Normalized Image Generation for Person Re-identification(pose归一化图像生成的行人再识别)
作者:Xuelin Qian,Yanwei Fu,Wenxuan Wang,Tao Xiang,Yang Wu,Yu-Gang Jiang,Xiangyang Xue
摘要:Person Re-identification (re-id) faces two major challenges: the lack of cross-view paired training data and learning discriminative identity-sensitive and view-invariant features in the presence of large pose variations. In this work, we address both problems by proposing a novel deep person image generation model for synthesizing realistic person images conditional on pose. The model is based on a generative adversarial network (GAN) and used specifically for pose normalization in re-id, thus termed pose-normalization GAN (PN-GAN). With the synthesized images, we can learn a new type of deep re-id feature free of the influence of pose variations. We show that this feature is strong on its own and highly complementary to features learned with the original images. Importantly, we now have a model that generalizes to any new re-id dataset without the need for collecting any training data for model fine-tuning, thus making a deep re-id model truly scalable. Extensive experiments on five benchmarks show that our model outperforms the state-of-the-art models, often significantly. In particular, the features learned on Market-1501 can achieve a Rank-1 accuracy of 68.67% on VIPeR without any model fine-tuning, beating almost all existing models fine-tuned on the dataset.
期刊:arXiv, 2018年2月13日
网址:
http://www.zhuanzhi.ai/document/d7ba094688fc85c5f1b958023d1adfe9
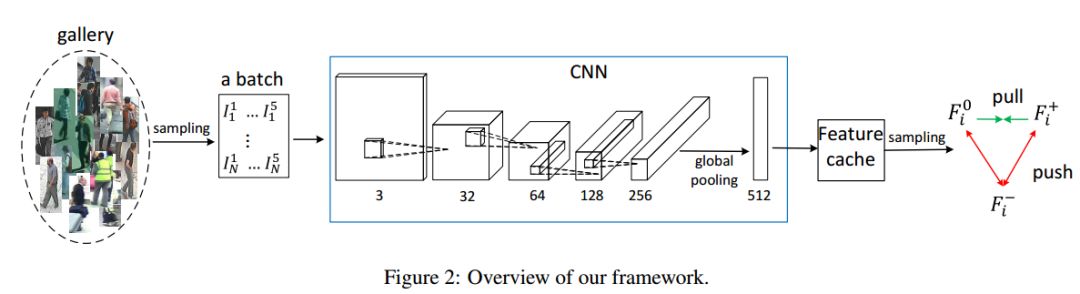
5. Triplet-based Deep Similarity Learning for Person Re-Identification(基于三元组的深度相似性学习的行人再识别)
作者:Wentong Liao,Michael Ying Yang,Ni Zhan,Bodo Rosenhahn
摘要:In recent years, person re-identification (re-id) catches great attention in both computer vision community and industry. In this paper, we propose a new framework for person re-identification with a triplet-based deep similarity learning using convolutional neural networks (CNNs). The network is trained with triplet input: two of them have the same class labels and the other one is different. It aims to learn the deep feature representation, with which the distance within the same class is decreased, while the distance between the different classes is increased as much as possible. Moreover, we trained the model jointly on six different datasets, which differs from common practice - one model is just trained on one dataset and tested also on the same one. However, the enormous number of possible triplet data among the large number of training samples makes the training impossible. To address this challenge, a double-sampling scheme is proposed to generate triplets of images as effective as possible. The proposed framework is evaluated on several benchmark datasets. The experimental results show that, our method is effective for the task of person re-identification and it is comparable or even outperforms the state-of-the-art methods.
期刊:arXiv, 2018年2月9日
网址:
http://www.zhuanzhi.ai/document/84a25d8af361247b4a3bc487ee56493f
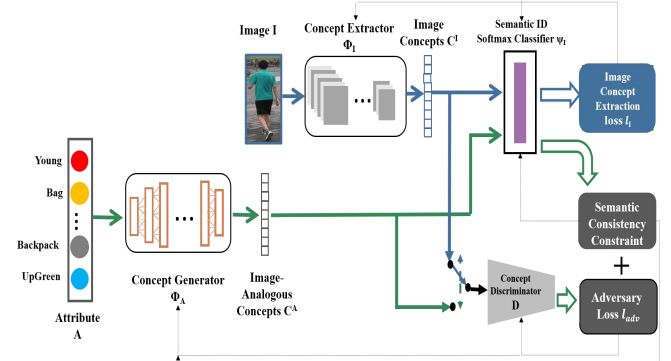
6. Adversarial Attribute-Image Person Re-identification(基于对抗属性-图像的行人再识别)
作者:Zhou Yin,Wei-Shi Zheng,Ancong Wu,Hong-Xing Yu,Hai Wang,Jianhuang Lai
摘要:While attributes have been widely used for person re-identification (Re-ID) that matches the same person images across disjoint camera views, they are used either as extra features or for performing multi-task learning to assist the image-image person matching task. However, how to find a set of person images according to a given attribute description, which is very practical in many surveillance applications, remains a rarely investigated cross-modal matching problem in Person Re-ID. In this work, we present this challenge and employ adversarial learning to formulate the attribute-image cross-modal person Re-ID model. By imposing the regularization on the semantic consistency constraint across modalities, the adversarial learning enables generating image-analogous concepts for query attributes and getting it matched with image in both global level and semantic ID level. We conducted extensive experiments on three attribute datasets and demonstrated that the adversarial modelling is so far the most effective for the attributeimage cross-modal person Re-ID problem.
期刊:arXiv, 2018年2月6日
网址:
http://www.zhuanzhi.ai/document/d6697d1a774afd59e7e8a218d8f4c36a
-END-
专 · 知
人工智能领域主题知识资料查看获取:【专知荟萃】人工智能领域26个主题知识资料全集(入门/进阶/论文/综述/视频/专家等)
同时欢迎各位用户进行专知投稿,详情请点击:
【诚邀】专知诚挚邀请各位专业者加入AI创作者计划!了解使用专知!
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

请加专知小助手微信(Rancho_Fang),加入专知主题人工智能群交流!
点击“阅读原文”,使用专知!


