【论文推荐】最新六篇图像描述生成相关论文—字符级推断、视觉解释、语义对齐、实体感知、确定性非自回归
【导读】专知内容组既昨天推出七篇图像描述生成(Image Captioning)相关文章,又整理了近期七篇图像描述生成(Image Captioning)相关文章,为大家进行介绍,欢迎查看!
8.Token-level and sequence-level loss smoothing for RNN language models(对RNN语言模型的标记级和序列级的损失平滑)
作者:Maha Elbayad,Laurent Besacier,Jakob Verbeek
ACL 2018
摘要:Despite the effectiveness of recurrent neural network language models, their maximum likelihood estimation suffers from two limitations. It treats all sentences that do not match the ground truth as equally poor, ignoring the structure of the output space. Second, it suffers from "exposure bias": during training tokens are predicted given ground-truth sequences, while at test time prediction is conditioned on generated output sequences. To overcome these limitations we build upon the recent reward augmented maximum likelihood approach \ie sequence-level smoothing that encourages the model to predict sentences close to the ground truth according to a given performance metric. We extend this approach to token-level loss smoothing, and propose improvements to the sequence-level smoothing approach. Our experiments on two different tasks, image captioning and machine translation, show that token-level and sequence-level loss smoothing are complementary, and significantly improve results.

期刊:arXiv, 2018年5月14日
网址:
http://www.zhuanzhi.ai/document/a47a8abfe92ca72c552ec96275024a11
9.Pragmatically Informative Image Captioning with Character-Level Inference(具有字符级推断语用信息的图像描述生成)
作者:Reuben Cohn-Gordon,Noah Goodman,Christopher Potts
NAACL Paper
机构:Stanford University
摘要:We combine a neural image captioner with a Rational Speech Acts (RSA) model to make a system that is pragmatically informative: its objective is to produce captions that are not merely true but also distinguish their inputs from similar images. Previous attempts to combine RSA with neural image captioning require an inference which normalizes over the entire set of possible utterances. This poses a serious problem of efficiency, previously solved by sampling a small subset of possible utterances. We instead solve this problem by implementing a version of RSA which operates at the level of characters ("a","b","c"...) during the unrolling of the caption. We find that the utterance-level effect of referential captions can be obtained with only character-level decisions. Finally, we introduce an automatic method for testing the performance of pragmatic speaker models, and show that our model outperforms a non-pragmatic baseline as well as a word-level RSA captioner.

期刊:arXiv, 2018年5月11日
网址:
http://www.zhuanzhi.ai/document/38a48688afedbc47de881d60c005bd0a
10.Grad-CAM++: Generalized Gradient-based Visual Explanations for Deep Convolutional Networks(Grad-CAM++:深度卷积网络的广义梯度视觉解释)
作者:Aditya Chattopadhyay,Anirban Sarkar,Prantik Howlader,Vineeth N Balasubramanian
WACV2018
摘要:Over the last decade, Convolutional Neural Network (CNN) models have been highly successful in solving complex vision based problems. However, these deep models are perceived as "black box" methods considering the lack of understanding of their internal functioning. There has been a significant recent interest to develop explainable deep learning models, and this paper is an effort in this direction. Building on a recently proposed method called Grad-CAM, we propose a generalized method called Grad-CAM++ that can provide better visual explanations of CNN model predictions, in terms of better object localization as well as explaining occurrences of multiple object instances in a single image, when compared to state-of-the-art. We provide a mathematical derivation for the proposed method, which uses a weighted combination of the positive partial derivatives of the last convolutional layer feature maps with respect to a specific class score as weights to generate a visual explanation for the corresponding class label. Our extensive experiments and evaluations, both subjective and objective, on standard datasets showed that Grad-CAM++ provides promising human-interpretable visual explanations for a given CNN architecture across multiple tasks including classification, image caption generation and 3D action recognition; as well as in new settings such as knowledge distillation.

期刊:arXiv, 2018年5月8日
网址:
http://www.zhuanzhi.ai/document/673991df8c7d9ef9f1d5e59634757334
11.Improved Image Captioning with Adversarial Semantic Alignment(改进的图像描述生成与对抗性的语义对齐)
作者:Igor Melnyk,Tom Sercu,Pierre L. Dognin,Jarret Ross,Youssef Mroueh
机构:IBM Research
摘要:In this paper we propose a new conditional GAN for image captioning that enforces semantic alignment between images and captions through a co-attentive discriminator and a context-aware LSTM sequence generator. In order to train these sequence GANs, we empirically study two algorithms: Self-critical Sequence Training (SCST) and Gumbel Straight-Through. Both techniques are confirmed to be viable for training sequence GANs. However, SCST displays better gradient behavior despite not directly leveraging gradients from the discriminator. This ensures a stronger stability of sequence GANs training and ultimately produces models with improved results under human evaluation. Automatic evaluation of GAN trained captioning models is an open question. To remedy this, we introduce a new semantic score with strong correlation to human judgement. As a paradigm for evaluation, we suggest that the generalization ability of the captioner to Out of Context (OOC) scenes is an important criterion to assess generalization and composition. To this end, we propose an OOC dataset which, combined with our automatic metric of semantic score, is a new benchmark for the captioning community to measure the generalization ability of automatic image captioning. Under this new OOC benchmark, and on the traditional MSCOCO dataset, our models trained with SCST have strong performance in both semantic score and human evaluation.
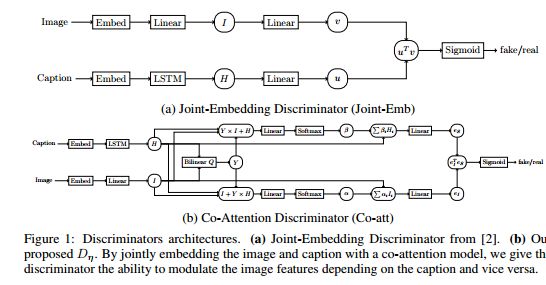
期刊:arXiv, 2018年5月1日
网址:
http://www.zhuanzhi.ai/document/ba4de394724144531093790fb8ad8250
12.Entity-aware Image Caption Generation(实体感知的图像描述生成器)
作者:Di Lu,Spencer Whitehead,Lifu Huang,Heng Ji,Shih-Fu Chang
机构:Columbia University
摘要:Image captioning approaches currently generate descriptions which lack specific information, such as named entities that are involved in the images. In this paper we propose a new task which aims to generate informative image captions, given images and hashtags as input. We propose a simple, but effective approach in which we, first, train a CNN-LSTM model to generate a template caption based on the input image. Then we use a knowledge graph based collective inference algorithm to fill in the template with specific named entities retrieved via the hashtags. Experiments on a new benchmark dataset collected from Flickr show that our model generates news-style image descriptions with much richer information. The METEOR score of our model almost triples the score of the baseline image captioning model on our benchmark dataset, from 4.8 to 13.60.
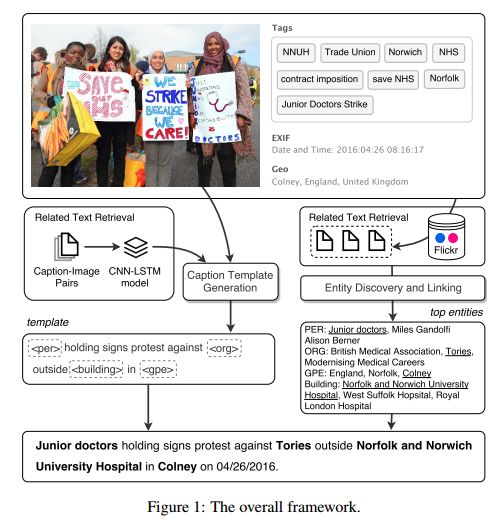
期刊:arXiv, 2018年4月21日
网址:
http://www.zhuanzhi.ai/document/202e05be9d06f4da971b2ca959241cbb
13.Deterministic Non-Autoregressive Neural Sequence Modeling by Iterative Refinement(确定性非自回归神经序列模型的迭代细化)
作者:Jason Lee,Elman Mansimov,Kyunghyun Cho
Submitted to ICML 2018
摘要:We propose a conditional non-autoregressive neural sequence model based on iterative refinement. The proposed model is designed based on the principles of latent variable models and denoising autoencoders, and is generally applicable to any sequence generation task. We extensively evaluate the proposed model on machine translation (En-De and En-Ro) and image caption generation, and observe that it significantly speeds up decoding while maintaining the generation quality comparable to the autoregressive counterpart.
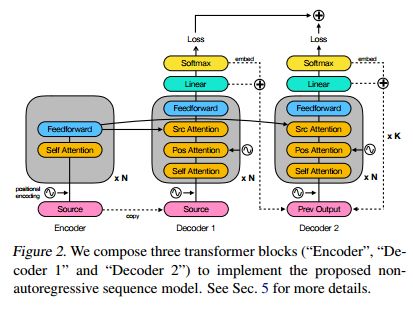
期刊:arXiv, 2018年4月18日
网址:
http://www.zhuanzhi.ai/document/714005ea52db2a8a6b4f5cb1b8f27b1d
-END-
专 · 知
人工智能领域主题知识资料查看与加入专知人工智能服务群:
【专知AI服务计划】专知AI知识技术服务会员群加入与人工智能领域26个主题知识资料全集获取。欢迎微信扫一扫加入专知人工智能知识星球群,获取专业知识教程视频资料和与专家交流咨询!

请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请加专知小助手微信(扫一扫如下二维码添加),加入专知主题群(请备注主题类型:AI、NLP、CV、 KG等)交流~

请关注专知公众号,获取人工智能的专业知识!
点击“阅读原文”,使用专知




