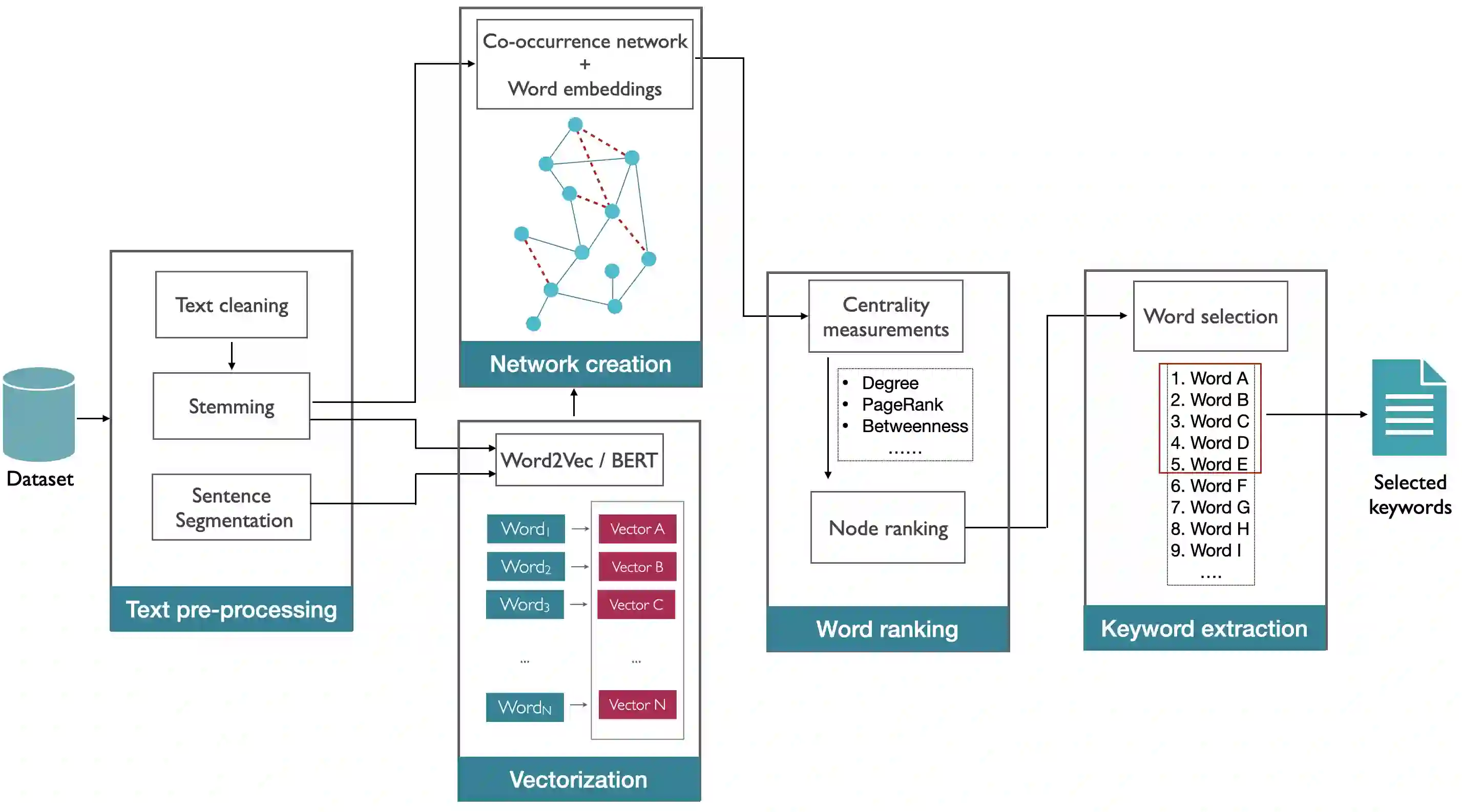
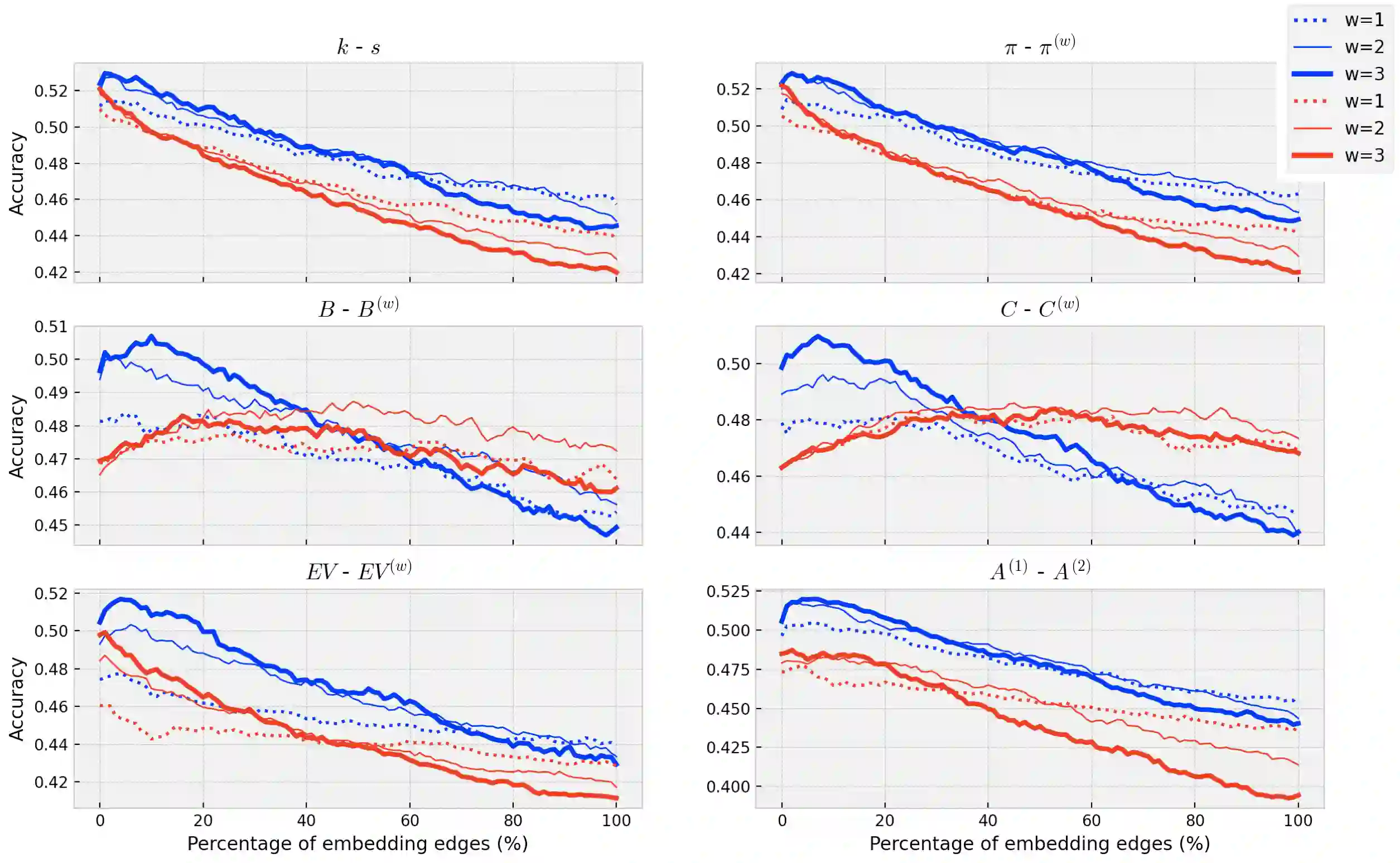
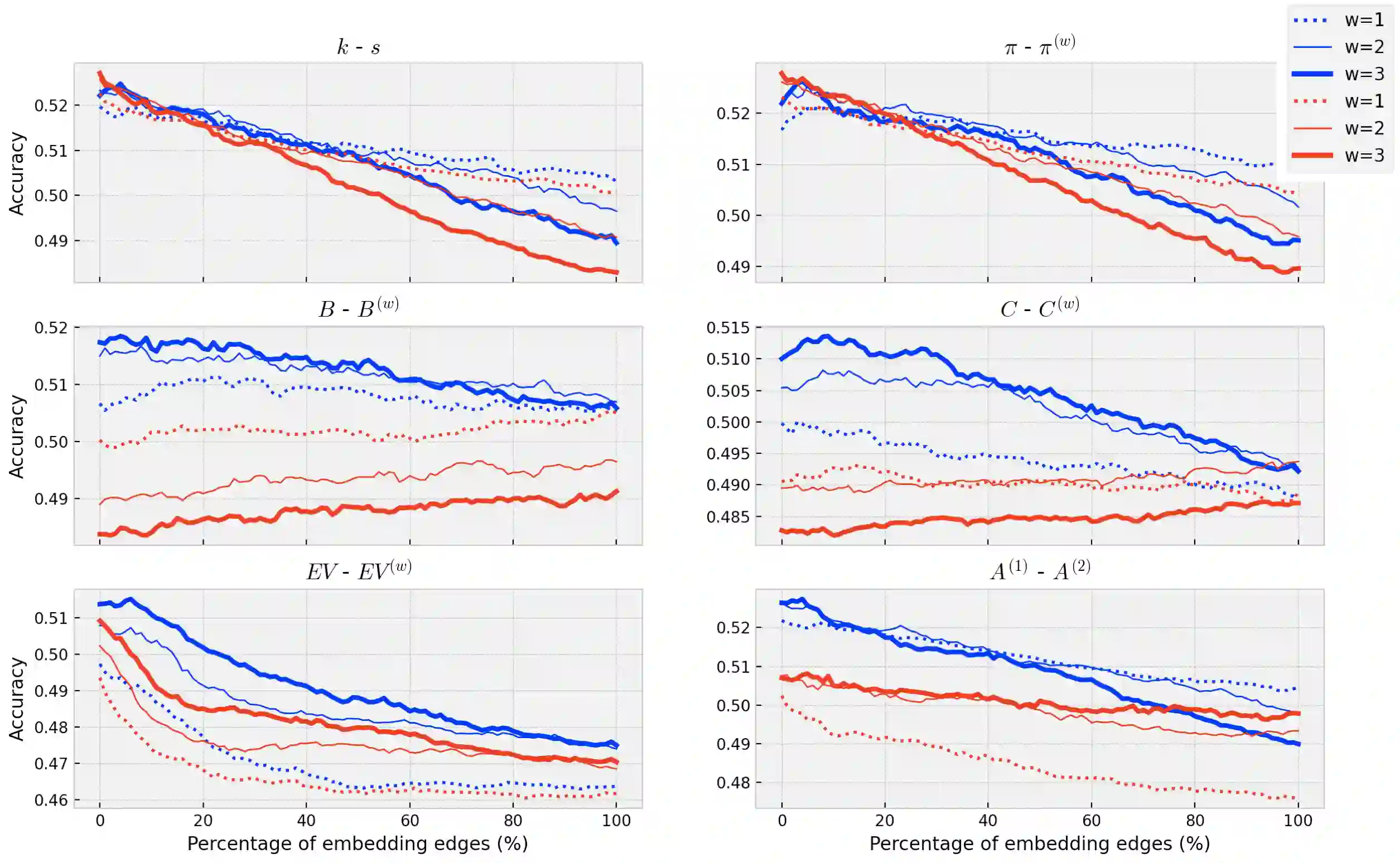
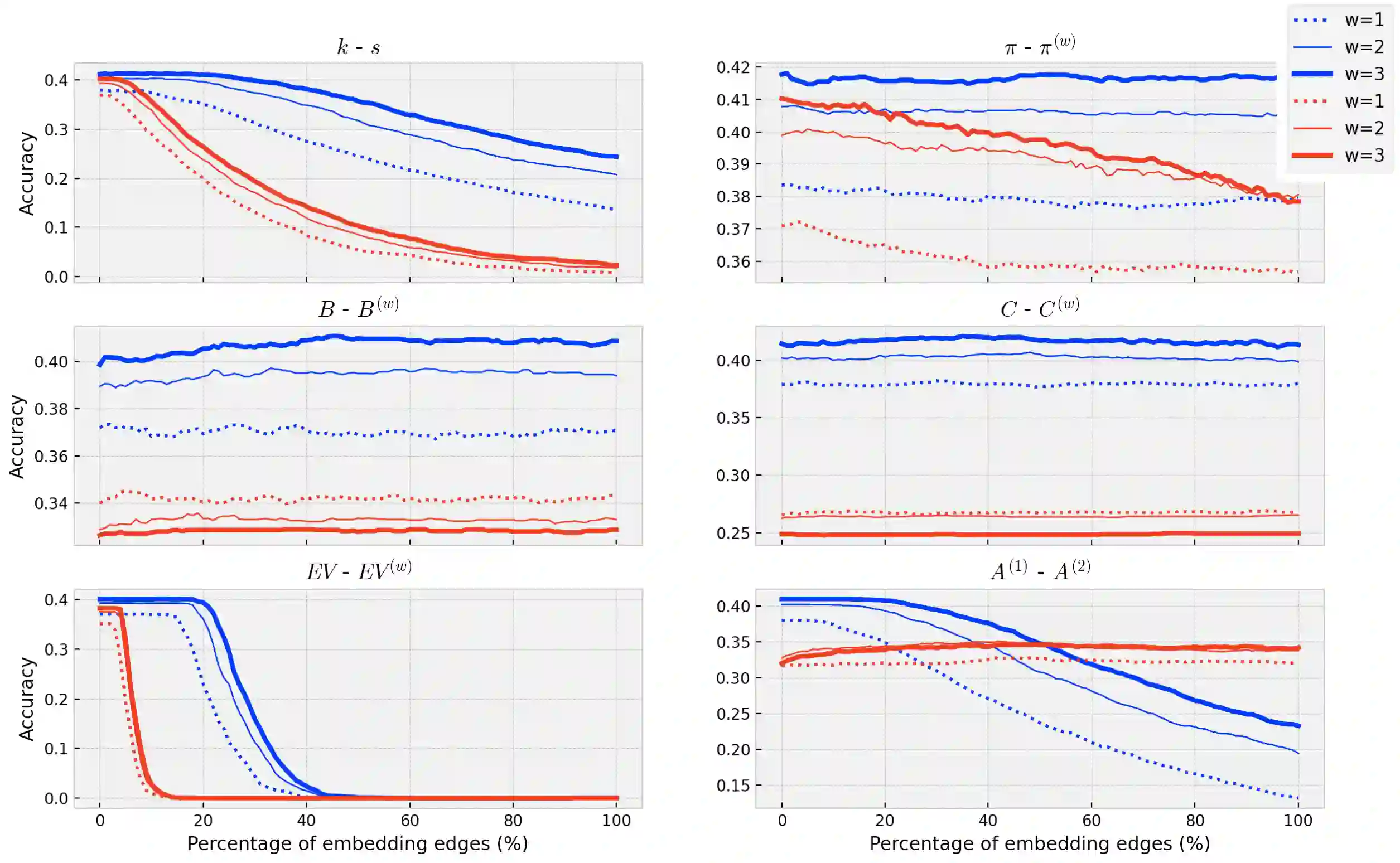
Detecting keywords in texts is important for many text mining applications. Graph-based methods have been commonly used to automatically find the key concepts in texts, however, relevant information provided by embeddings has not been widely used to enrich the graph structure. Here we modeled texts co-occurrence networks, where nodes are words and edges are established either by contextual or semantical similarity. We compared two embedding approaches -- Word2vec and BERT -- to check whether edges created via word embeddings can improve the quality of the keyword extraction method. We found that, in fact, the use of virtual edges can improve the discriminability of co-occurrence networks. The best performance was obtained when we considered low percentages of addition of virtual (embedding) edges. A comparative analysis of structural and dynamical network metrics revealed the degree, PageRank, and accessibility are the metrics displaying the best performance in the model enriched with virtual edges.
翻译:在文本中检测关键字对许多文本挖掘应用很重要。基于图表的方法通常被用来自动查找文本中的关键概念,然而,嵌入层提供的相关信息并没有被广泛用于丰富图形结构。在这里,我们模拟了文本共同出现网络,其中节点是文字和边缘,通过上下文或语义相似性来建立。我们比较了两种嵌入方法 -- -- Word2vec 和 BERT -- -- 以检查通过文字嵌入生成的边缘是否能提高关键字提取方法的质量。我们发现,事实上,虚拟边缘的使用可以改善共同生成网络的可调和性。当我们考虑虚拟(叠装)边缘添加率低时,取得了最佳的成绩。对结构和动态网络衡量尺度的比较分析揭示了等级,PageRank和可获取性是显示以虚拟边缘丰富模型的最佳性能的尺度。