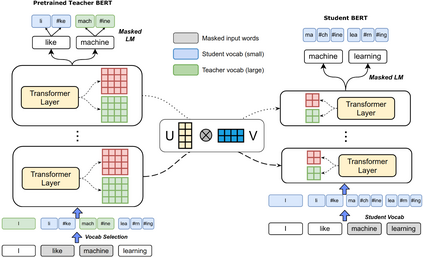
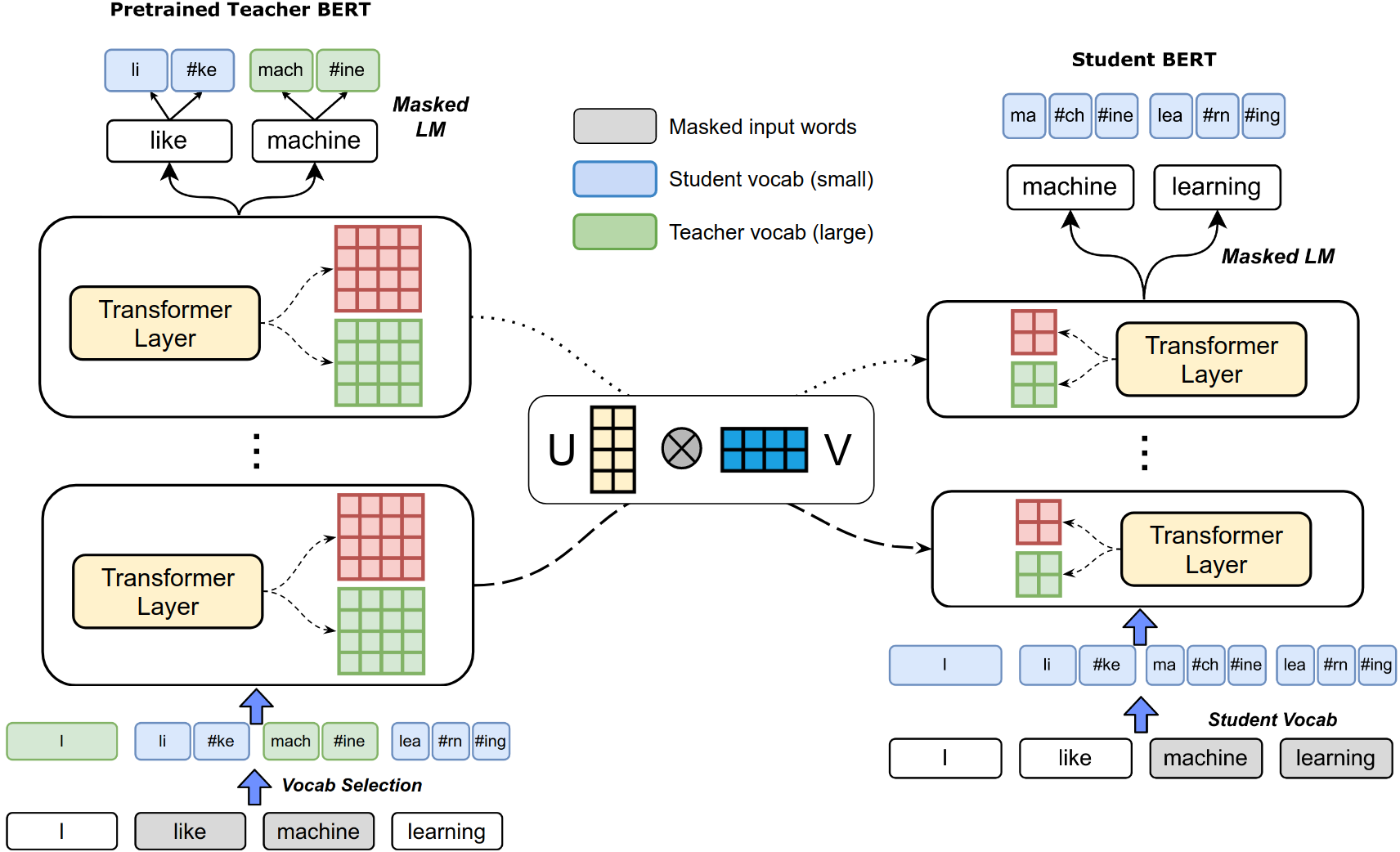
Pre-trained deep neural network language models such as ELMo, GPT, BERT and XLNet have recently achieved state-of-the-art performance on a variety of language understanding tasks. However, their size makes them impractical for a number of scenarios, especially on mobile and edge devices. In particular, the input word embedding matrix accounts for a significant proportion of the model's memory footprint, due to the large input vocabulary and embedding dimensions. Knowledge distillation techniques have had success at compressing large neural network models, but they are ineffective at yielding student models with vocabularies different from the original teacher models. We introduce a novel knowledge distillation technique for training a student model with a significantly smaller vocabulary as well as lower embedding and hidden state dimensions. Specifically, we employ a dual-training mechanism that trains the teacher and student models simultaneously to obtain optimal word embeddings for the student vocabulary. We combine this approach with learning shared projection matrices that transfer layer-wise knowledge from the teacher model to the student model. Our method is able to compress the BERT_BASE model by more than 60x, with only a minor drop in downstream task metrics, resulting in a language model with a footprint of under 7MB. Experimental results also demonstrate higher compression efficiency and accuracy when compared with other state-of-the-art compression techniques.
翻译:诸如ELMO、GPT、BERT和XLNet等经过预先培训的深神经网络语言模型最近取得了各种语言理解任务的最新表现。然而,它们的大小使得它们对于一些情景,特别是移动和边缘设备,不切实际。特别是,输入字嵌入矩阵占模型记忆足迹的很大比例,因为输入词汇和嵌入的尺寸很大。知识蒸馏技术成功地压缩了大型神经网络模型,但在产生与原始教师模型不同的词汇的学生模型方面却效率不高。我们引进了一种新的知识蒸馏技术,用于培训使用大大小于词汇的学生模型,以及更低嵌入和隐藏的状态层面。具体地说,我们采用双重培训机制,培训教师和学生模型同时获得学生词汇的最佳字嵌入。我们把这一方法与学习共同的预测矩阵结合起来,从教师模型向学生模型转移分层知识。我们的方法能够将BERT_BASEB模型改成超过60x的新知识。我们采用的新的知识蒸馏技术,用于以小小小的实验性水平,同时将低级的实验性定位技术在下进行。