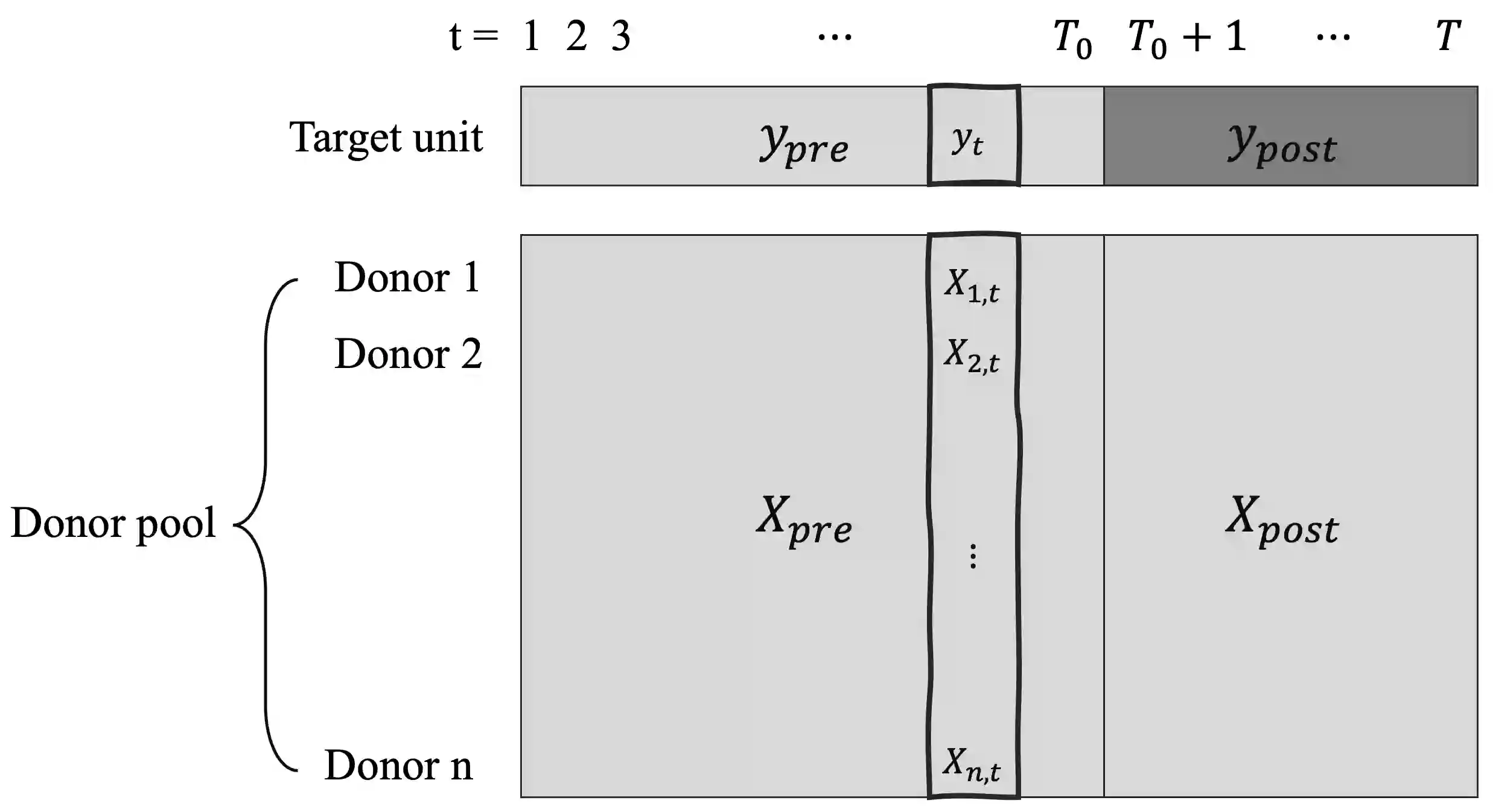
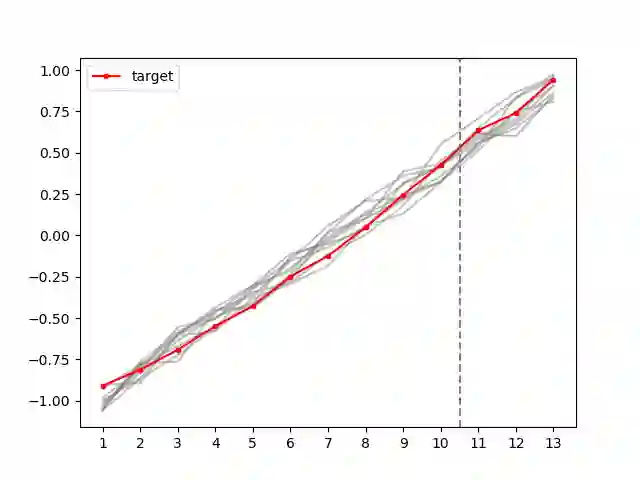
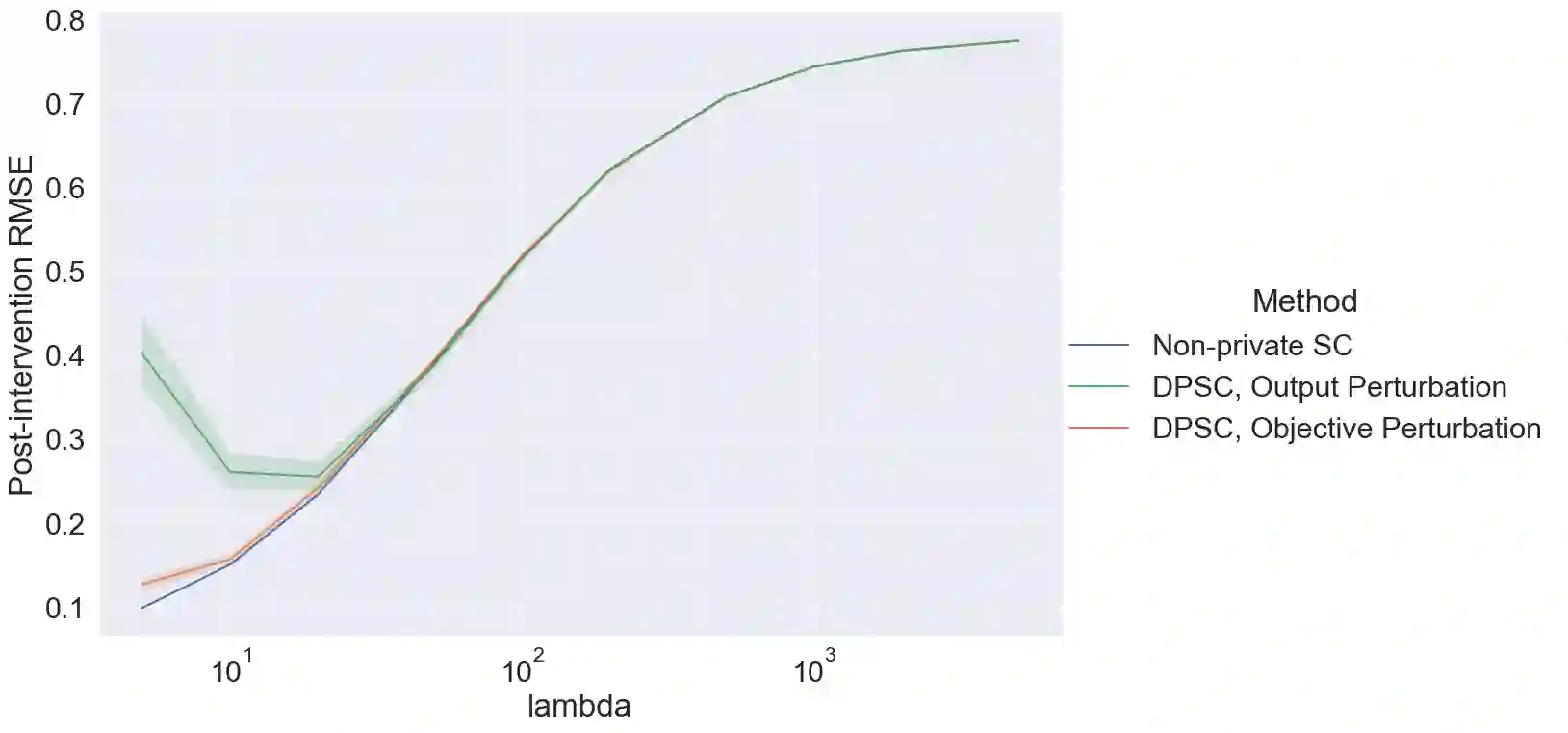
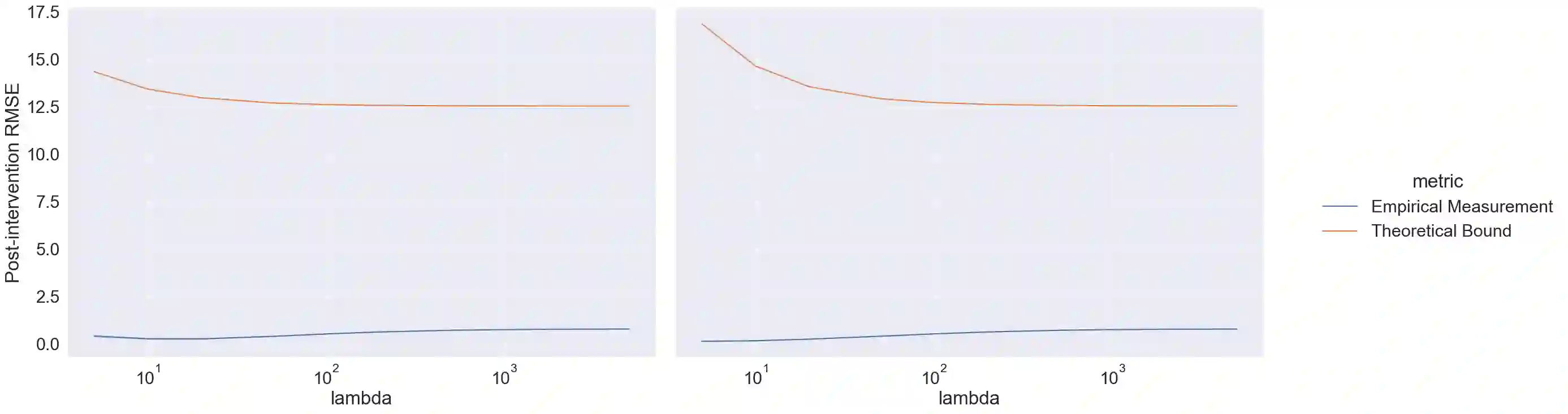
Synthetic control is a causal inference tool used to estimate the treatment effects of an intervention by creating synthetic counterfactual data. This approach combines measurements from other similar observations (i.e., donor pool ) to predict a counterfactual time series of interest (i.e., target unit) by analyzing the relationship between the target and the donor pool before the intervention. As synthetic control tools are increasingly applied to sensitive or proprietary data, formal privacy protections are often required. In this work, we provide the first algorithms for differentially private synthetic control with explicit error bounds. Our approach builds upon tools from non-private synthetic control and differentially private empirical risk minimization. We provide upper and lower bounds on the sensitivity of the synthetic control query and provide explicit error bounds on the accuracy of our private synthetic control algorithms. We show that our algorithms produce accurate predictions for the target unit, and that the cost of privacy is small. Finally, we empirically evaluate the performance of our algorithm, and show favorable performance in a variety of parameter regimes, as well as providing guidance to practitioners for hyperparameter tuning.
翻译:合成对照是一种用于通过创建合成对照数据来估计干预的治疗效果的因果推断工具。该方法结合了来自其他类似的观察值(即捐赠池)的测量,通过分析干预前目标和捐赠池之间的关系来预测感兴趣的反事实时间序列(即目标单元)。随着合成控制工具越来越多地应用于敏感或专有数据,通常需要正式的隐私保护。在这项工作中,我们提供了第一个具有显式误差界限的差分隐私合成控制算法。我们的方法建立在非隐私合成控制和差分隐私经验风险最小化工具之上。我们提供合成控制查询灵敏度的上下界,并提供我们私有合成控制算法准确性的显式误差界。我们展示了我们的算法能够为目标单元产生准确的预测,而隐私成本很小。最后,我们在实证方面评估了我们算法的性能,并展示了在多种参数情况下有利的性能,同时为从业者提供了超参数调整的指导。