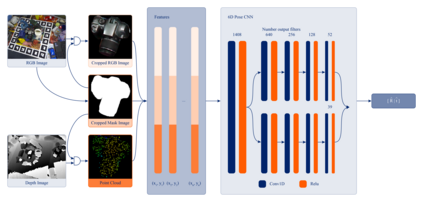
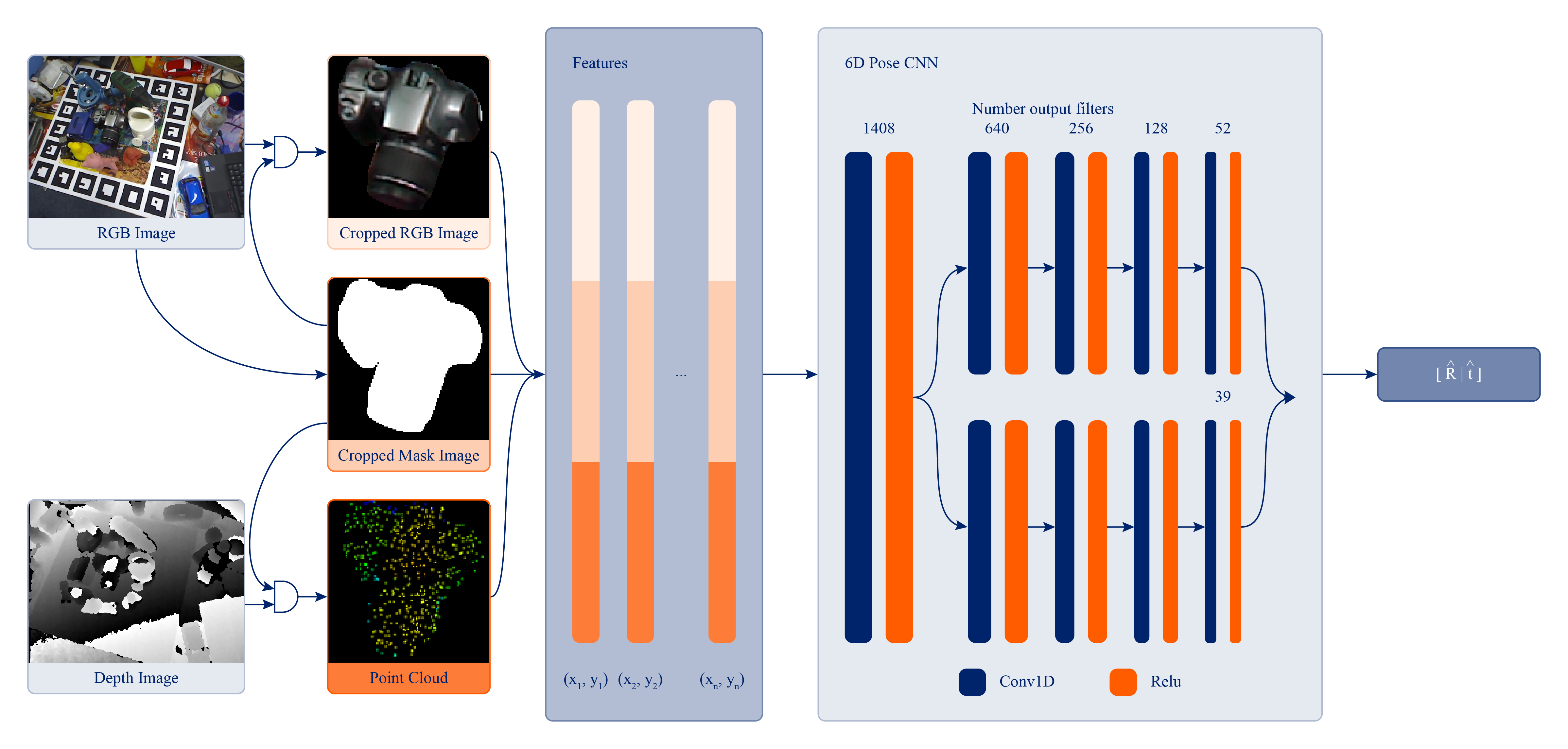
MaskedFusion is a framework to estimate 6D pose of objects using RGB-D data, with an architecture that leverages multiple stages in a pipeline to achieve accurate 6D poses. 6D pose estimation is an open challenge due to complex world objects and many possible problems when capturing data from the real world, e.g., occlusions, truncations, and noise in the data. Achieving accurate 6D poses will improve results in other open problems like robot grasping or positioning objects in augmented reality. MaskedFusion improves upon DenseFusion where the key differences are in pre-processing data before it enters the Neural Network (NN), eliminating non-relevant data, and adding additional features extracted from the mask of the objects to the NN to improve its estimation. It achieved $5.9mm$ average error on the widely used LineMOD dataset, which is an improvement, of more than 20\%, compared to the state-of-the-art method, DenseFusion.
翻译:遮盖面图是一个框架,用来估计使用 RGB-D 数据的物体6D 形状的6D 形状,其结构利用管道的多个阶段来达到准确的 6D 形状。 6D 显示面图是一个公开的挑战,因为复杂的世界天体和从真实世界获取数据时可能存在许多问题,例如隐蔽、截断和数据中的噪音。 实现准确的 6D 表示将改善其他未解决问题的结果,例如机器人在扩大的现实中捕捉或定位物体。 遮面图有助于DenseFusion在进入神经网络(NN)之前的预处理数据存在关键差异的情况下改进DenseFusion,消除了非相关数据,并增加了从物体面具中提取到NN的更多特征,以改进其估计。 在广泛使用的线MOD 数据集上,实现了5.9毫米的平均误差,比DenseFusion改进了20多英寸。