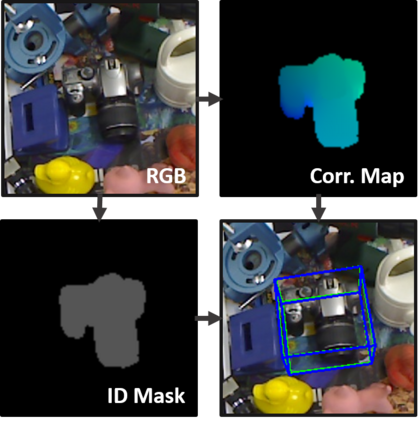
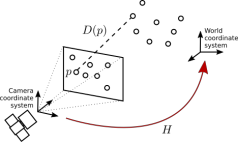
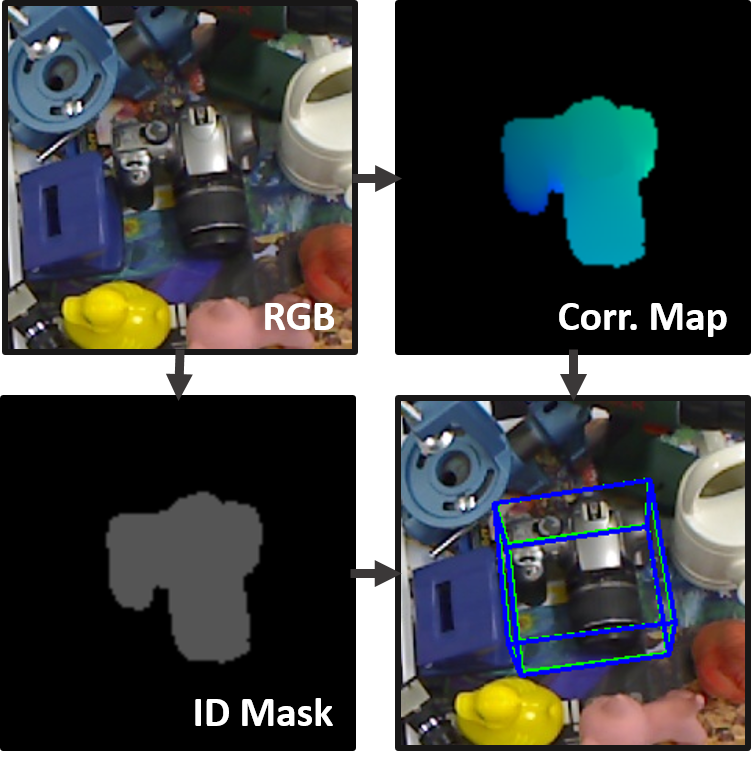
In this work we propose a new method for simultaneous object detection and 6DoF pose estimation. Unlike most recent techniques for CNN-based object detection and pose estimation, we do not base our approach on the common 2D counterparts, i.e. SSD and YOLO, but propose a new scheme. Instead of regressing 2D or 3D bounding boxes, we output full-sized 2D images containing multiclass object masks and dense 2D-3D correspondences. Having them at hand, a 6D pose is computed for each detected object using the PnP algorithm supplemented with RANSAC. This strategy allows for substantially better pose estimates due to a much higher number of relevant pose correspondences. Furthermore, the method is real-time capable, conceptually simple and not bound to any particular detection paradigms, such as R-CNN, SSD or YOLO. We test our method for single- and multiple-object pose estimation and compare the performance with the former state-of-the-art approaches. Moreover, we demonstrate how to use our pipeline when only synthetic renderings are available. In both cases, we outperform the former state-of-the-art by a large margin.
翻译:在这项工作中,我们提出了一个同步物体探测和6DF 构成估计的新方法。与最近以CNN为基础的近些技术不同,我们并不是以普通的2D对应方,即SSD和YOLO为基础,而是提出一个新的方案。我们不倒影 2D 或 3D 捆绑框,而是输出含有多级物体面具和密度2D-3D 对应体的全尺寸2D 图像。有了这些图像,就使用由RANSAC补充的P PnP 算法为每个被探测到的物体计算出一个6D 6D 构成的图像。由于相关对应方的对应方数量要多得多,因此这一战略可以大大地更好地作出估计。此外,该方法具有实时能力,概念简单,不受任何特定的检测范式的约束,例如R-CNN、SSD或YOLO。我们测试了单项和多项对象的估测算方法,并将其性能与前项最新方法进行比较。此外,我们演示了如何在只有合成的情形下使用管道。在两种情况下,我们用一个大的比值比值比值比值比值。