【论文推荐】最新6篇目标检测(Object Detection)相关论文—物体链接、手机端、三维地图、航空图像、检测与姿态估计
【导读】专知内容组整理了最近六篇目标检测(Object Detection)相关文章,为大家进行介绍,欢迎查看!
1. Object Detection in Videos by Short and Long Range Object Linking(基于长短范围物体链接的视频物体检测方法)
作者:Peng Tang,Chunyu Wang,Xinggang Wang,Wenyu Liu,Wenjun Zeng,Jingdong Wang
摘要:We address the problem of detecting objects in videos with the interest in exploring temporal contexts. Our core idea is to link objects in the short and long ranges for improving the classification quality. Our approach first proposes a set of candidate spatio-temporal cuboids, each of which serves as a container associating the object across short range frames, for a short video segment. It then regresses the precise box locations in each frame over each cuboid proposal, yielding a tubelet with a single classification score which is aggregated from the scores of the boxes in the tubelet. Third, we extend the non-maximum suppression algorithm to remove spatially-overlapping tubelets in the short segment, avoiding tubelets broken by the frame-wise NMS. Finally, we link the tubelets across temporally-overlapping short segments over the whole video, in order to boost the classification scores for positive detections by aggregating the scores in the linked tubelets. Experiments on the ImageNet VID dataset shows that our approach achieves the state-of-the-art performance.
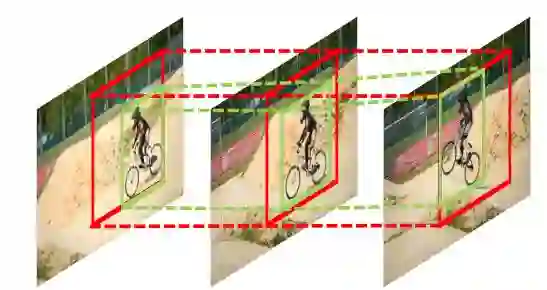
期刊:arXiv, 2018年1月30日
网址:
http://www.zhuanzhi.ai/document/e2b99767433c5b0e32fd09534482b168
2. Road Damage Detection Using Deep Neural Networks with Images Captured Through a Smartphone(用深度神经网络对手机端获取的图像进行道路损伤检测)
作者:Hiroya Maeda,Yoshihide Sekimoto,Toshikazu Seto,Takehiro Kashiyama,Hiroshi Omata
摘要:Research on damage detection of road surfaces using image processing techniques has been actively conducted, achieving considerably high detection accuracies. Many studies only focus on the detection of the presence or absence of damage. However, in a real-world scenario, when the road managers from a governing body need to repair such damage, they need to clearly understand the type of damage in order to take effective action. In addition, in many of these previous studies, the researchers acquire their own data using different methods. Hence, there is no uniform road damage dataset available openly, leading to the absence of a benchmark for road damage detection. This study makes three contributions to address these issues. First, to the best of our knowledge, for the first time, a large-scale road damage dataset is prepared. This dataset is composed of 9,053 road damage images captured with a smartphone installed on a car, with 15,435 instances of road surface damage included in these road images. In order to generate this dataset, we cooperated with 7 municipalities in Japan and acquired road images for more than 40 hours. These images were captured in a wide variety of weather and illuminance conditions. In each image, we annotated the bounding box representing the location and type of damage. Next, we used a state-of-the-art object detection method using convolutional neural networks to train the damage detection model with our dataset, and compared the accuracy and runtime speed on both, using a GPU server and a smartphone. Finally, we demonstrate that the type of damage can be classified into eight types with high accuracy by applying the proposed object detection method. The road damage dataset, our experimental results, and the developed smartphone application used in this study are publicly available (https://github.com/sekilab/RoadDamageDetector/).
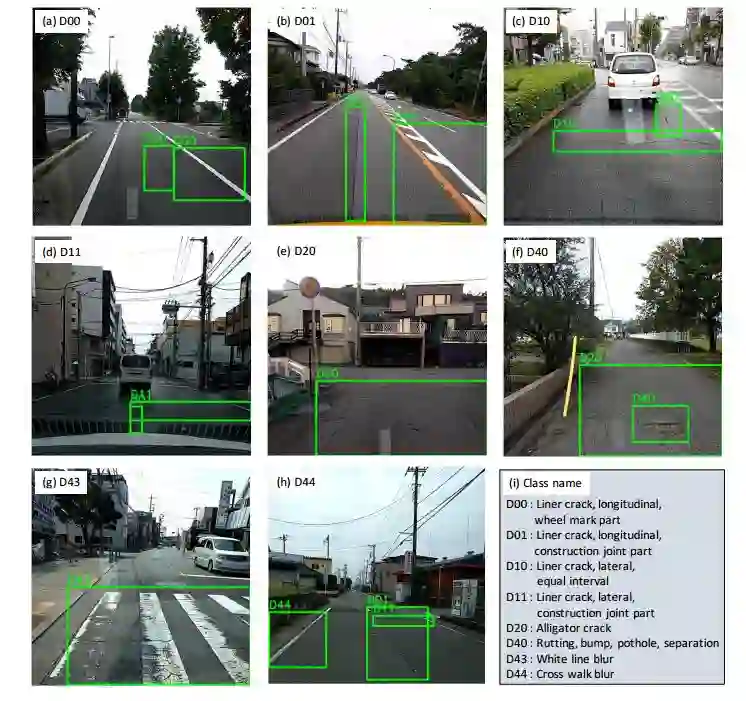
期刊:arXiv, 2018年1月29日
网址:
http://www.zhuanzhi.ai/document/d230021cc5b5b8ca2add21c97995b26a
3. Multiple Object Detection, Tracking and Long-Term Dynamics Learning in Large 3D Maps(大型三维地图中的多目标检测、跟踪和长时期动态学习)
作者:Nils Bore,Patric Jensfelt,John Folkesson
摘要:In this work, we present a method for tracking and learning the dynamics of all objects in a large scale robot environment. A mobile robot patrols the environment and visits the different locations one by one. Movable objects are discovered by change detection, and tracked throughout the robot deployment. For tracking, we extend the Rao-Blackwellized particle filter of previous work with birth and death processes, enabling the method to handle an arbitrary number of objects. Target births and associations are sampled using Gibbs sampling. The parameters of the system are then learnt using the Expectation Maximization algorithm in an unsupervised fashion. The system therefore enables learning of the dynamics of one particular environment, and of its objects. The algorithm is evaluated on data collected autonomously by a mobile robot in an office environment during a real-world deployment. We show that the algorithm automatically identifies and tracks the moving objects within 3D maps and infers plausible dynamics models, significantly decreasing the modeling bias of our previous work. The proposed method represents an improvement over previous methods for environment dynamics learning as it allows for learning of fine grained processes.
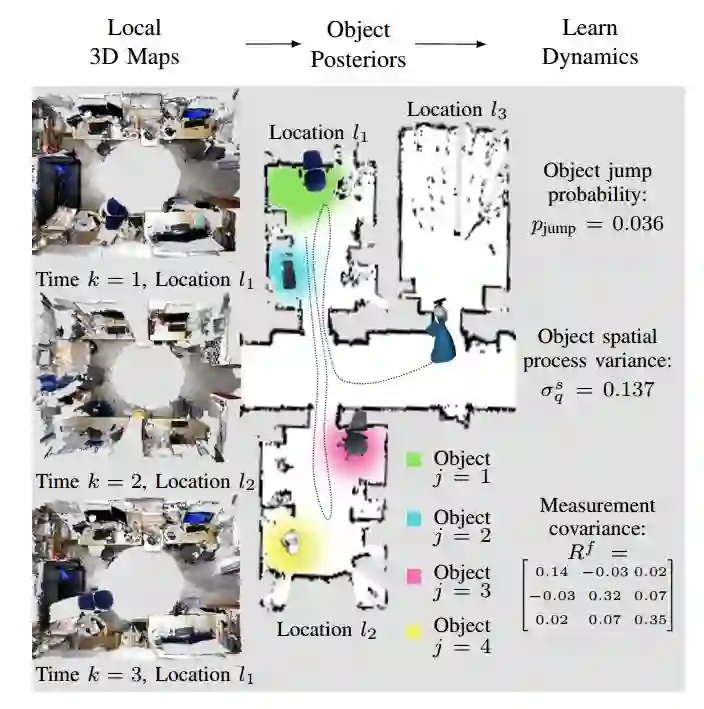
期刊:arXiv, 2018年1月29日
网址:
http://www.zhuanzhi.ai/document/2963a7e34502db70d56016814435e53d
4. DOTA: A Large-scale Dataset for Object Detection in Aerial Images(DOTA: 一种用于航空图像中物体检测的大规模数据集)
作者:Gui-Song Xia,Xiang Bai,Jian Ding,Zhen Zhu,Serge Belongie,Jiebo Luo,Mihai Datcu,Marcello Pelillo,Liangpei Zhang
摘要:Object detection is an important and challenging problem in computer vision. Although the past decade has witnessed major advances in object detection in natural scenes, such successes have been slow to aerial imagery, not only because of the huge variation in the scale, orientation and shape of the object instances on the earth's surface, but also due to the scarcity of well-annotated datasets of objects in aerial scenes. To advance object detection research in Earth Vision, also known as Earth Observation and Remote Sensing, we introduce a large-scale Dataset for Object deTection in Aerial images (DOTA). To this end, we collect $2806$ aerial images from different sensors and platforms. Each image is of the size about 4000-by-4000 pixels and contains objects exhibiting a wide variety of scales, orientations, and shapes. These DOTA images are then annotated by experts in aerial image interpretation using $15$ common object categories. The fully annotated DOTA images contains $188,282$ instances, each of which is labeled by an arbitrary (8 d.o.f.) quadrilateral To build a baseline for object detection in Earth Vision, we evaluate state-of-the-art object detection algorithms on DOTA. Experiments demonstrate that DOTA well represents real Earth Vision applications and are quite challenging.
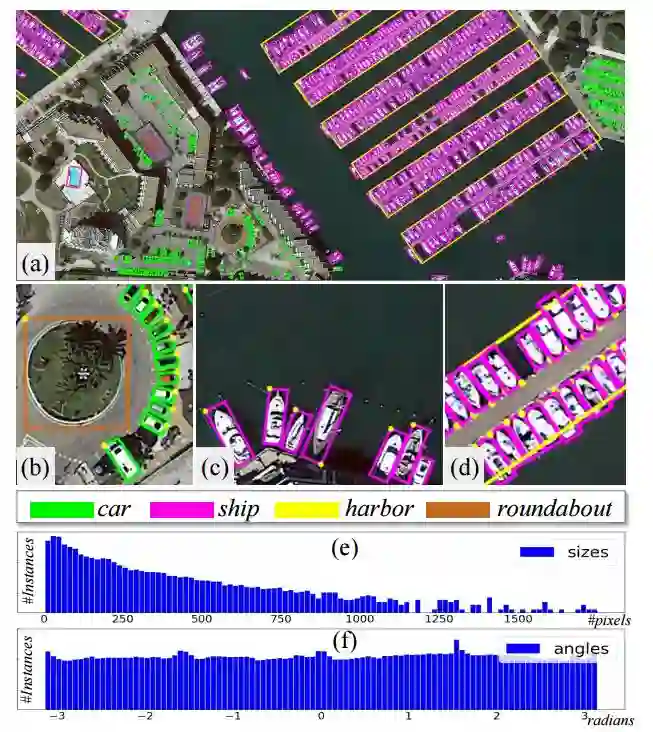
期刊:arXiv, 2018年1月27日
网址:
http://www.zhuanzhi.ai/document/f6115e44648c537ca420873e115e87fa
5. Weakly Supervised Object Detection with Pointwise Mutual Information(基于点互信息的弱监督对象检测)
作者:Rene Grzeszick,Sebastian Sudholt,Gernot A. Fink
摘要:In this work a novel approach for weakly supervised object detection that incorporates pointwise mutual information is presented. A fully convolutional neural network architecture is applied in which the network learns one filter per object class. The resulting feature map indicates the location of objects in an image, yielding an intuitive representation of a class activation map. While traditionally such networks are learned by a softmax or binary logistic regression (sigmoid cross-entropy loss), a learning approach based on a cosine loss is introduced. A pointwise mutual information layer is incorporated in the network in order to project predictions and ground truth presence labels in a non-categorical embedding space. Thus, the cosine loss can be employed in this non-categorical representation. Besides integrating image level annotations, it is shown how to integrate point-wise annotations using a Spatial Pyramid Pooling layer. The approach is evaluated on the VOC2012 dataset for classification, point localization and weakly supervised bounding box localization. It is shown that the combination of pointwise mutual information and a cosine loss eases the learning process and thus improves the accuracy. The integration of coarse point-wise localizations further improves the results at minimal annotation costs.
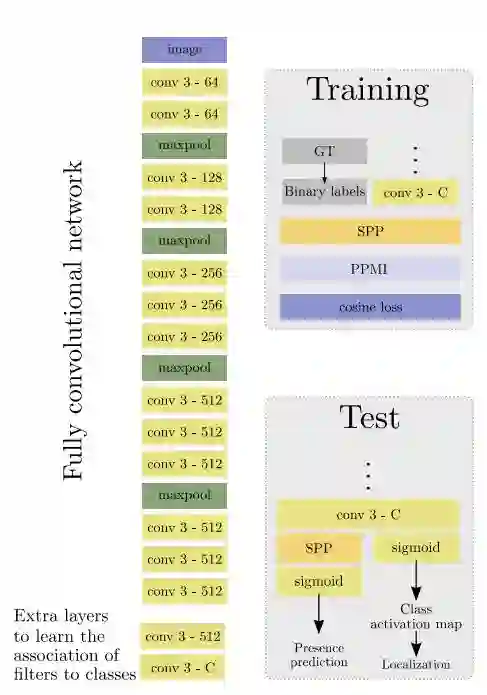
期刊:arXiv, 2018年1月26日
网址:
http://www.zhuanzhi.ai/document/8bf028a010ae26a53b35facb23b76491
6. The challenge of simultaneous object detection and pose estimation: a comparative study(同时目标检测与姿态估计的挑战:比较研究)
作者:Daniel Oñoro-Rubio,Roberto J. López-Sastre,Carolina Redondo-Cabrera,Pedro Gil-Jiménez
摘要:Detecting objects and estimating their pose remains as one of the major challenges of the computer vision research community. There exists a compromise between localizing the objects and estimating their viewpoints. The detector ideally needs to be view-invariant, while the pose estimation process should be able to generalize towards the category-level. This work is an exploration of using deep learning models for solving both problems simultaneously. For doing so, we propose three novel deep learning architectures, which are able to perform a joint detection and pose estimation, where we gradually decouple the two tasks. We also investigate whether the pose estimation problem should be solved as a classification or regression problem, being this still an open question in the computer vision community. We detail a comparative analysis of all our solutions and the methods that currently define the state of the art for this problem. We use PASCAL3D+ and ObjectNet3D datasets to present the thorough experimental evaluation and main results. With the proposed models we achieve the state-of-the-art performance in both datasets.
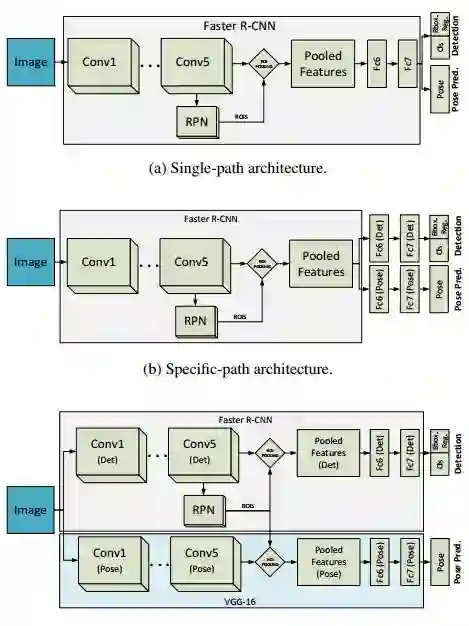
期刊:arXiv, 2018年1月25日
网址:
http://www.zhuanzhi.ai/document/6d8a16854c4df21e9fca775ae85c80c6
-END-
专 · 知
人工智能领域主题知识资料查看获取:【专知荟萃】人工智能领域26个主题知识资料全集(入门/进阶/论文/综述/视频/专家等)
同时欢迎各位用户进行专知投稿,详情请点击:
【诚邀】专知诚挚邀请各位专业者加入AI创作者计划!了解使用专知!
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

请加专知小助手微信(Rancho_Fang),加入专知主题人工智能群交流!
点击“阅读原文”,使用专知!



