
从多视角图像中估计出人体关键点的 3D 坐标,是计算机视觉中一个重要的任务。许多工作的流程为:首先从每个相机视角估计出 2D 坐标,然后使用三角化(Triangulation)等方法,计算出对应的 3D 坐标。这类方法的最终结果质量,通常取决于 2D 坐标的精确度。但是,如果存在遮挡等问题,预测的 2D 坐标会存在较大的误差。
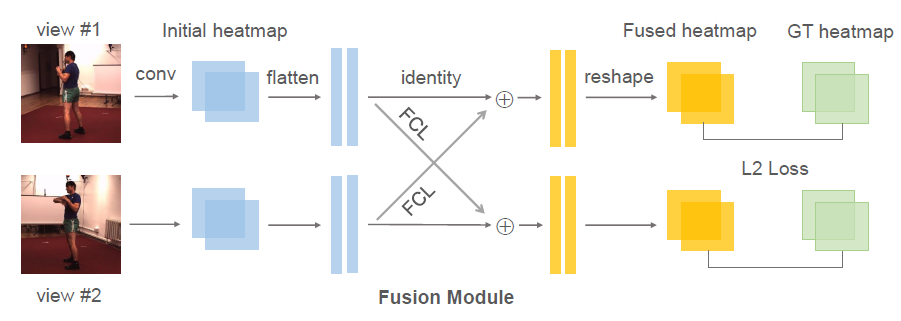
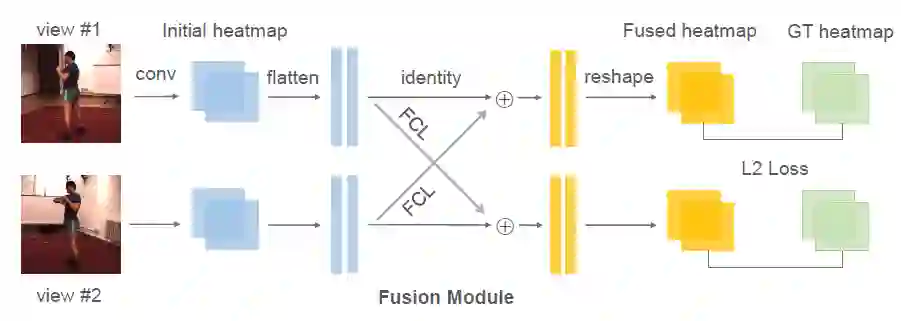
在预测 2D 坐标过程中,融合多个视角的信息可有效解决遮挡等问题。但是目前方法中,融合模型的参数依赖于特定相机对,难以泛化到新的环境。针对这一问题,本文提出将原有的融合模型分解为(1)所有相机共享的通用模型(2)针对特定相机的轻量变换矩阵。并且使用元学习算法,在大规模多相机数据中进行预训练,从而最大化模型的泛化能力。在多个公开数据集上的实验,证明了该模型(MetaFuse)在新环境中只需少量样本即可有效迁移。
成为VIP会员查看完整内容
相关内容

相关VIP内容
相关资讯
相关论文