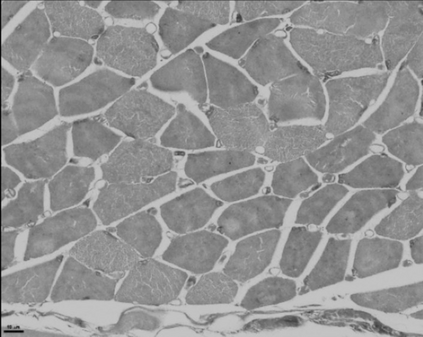
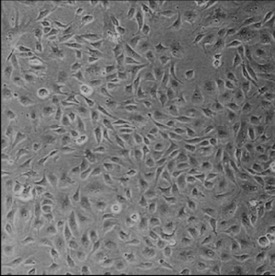
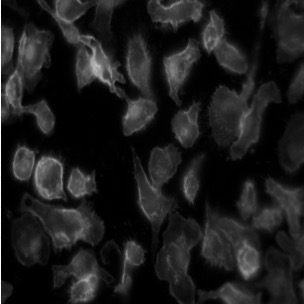
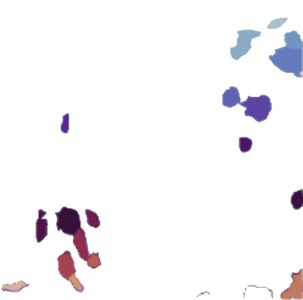
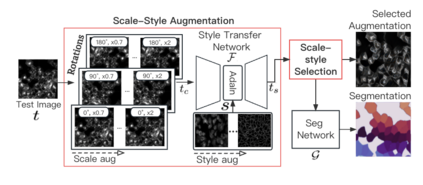
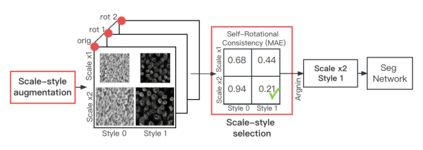
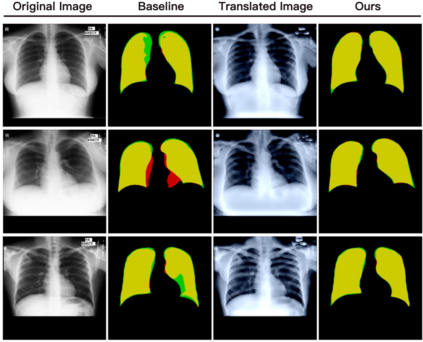
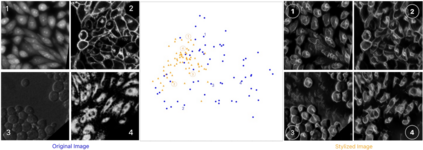
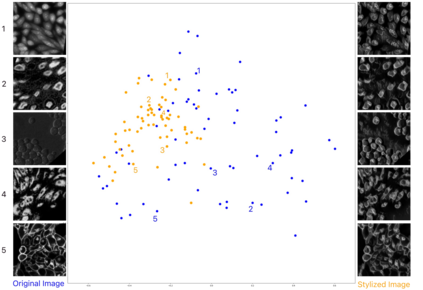
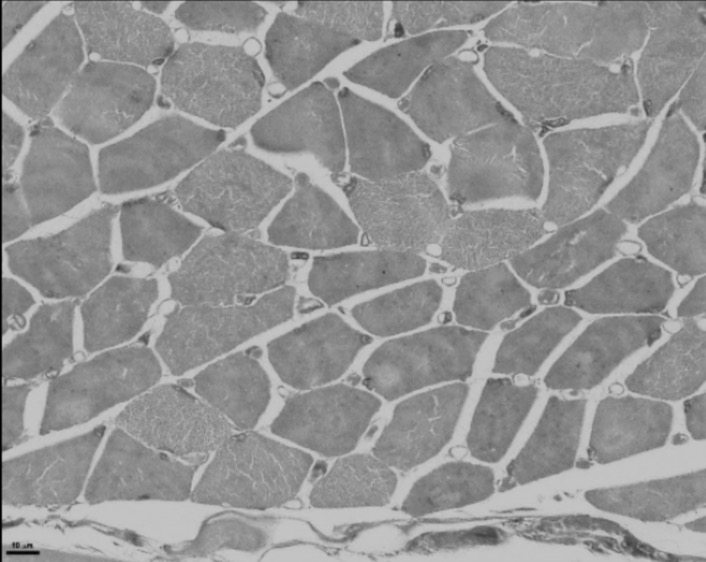
Deep-learning models have been successful in biomedical image segmentation. To generalize for real-world deployment, test-time augmentation (TTA) methods are often used to transform the test image into different versions that are hopefully closer to the training domain. Unfortunately, due to the vast diversity of instance scale and image styles, many augmented test images produce undesirable results, thus lowering the overall performance. This work proposes a new TTA framework, S$^3$-TTA, which selects the suitable image scale and style for each test image based on a transformation consistency metric. In addition, S$^3$-TTA constructs an end-to-end augmentation-segmentation joint-training pipeline to ensure a task-oriented augmentation. On public benchmarks for cell and lung segmentation, S$^3$-TTA demonstrates improvements over the prior art by 3.4% and 1.3%, respectively, by simply augmenting the input data in testing phase.
翻译:暂无翻译