RL解决'BipedalWalkerHardcore-v2' (SOTA)
1. gym环境 'BipedalWalkerHardcore-v2' 介绍:
Hardcore version of 'BipedalWalker-v2' with ladders, stumps, pitfalls. Time limit is increased due to obstacles. Reward is given for moving forward, total 300+ points up to the far end. If the robot falls, it gets -100. Applying motor torque costs a small amount of points, more optimal agent will get better score. State consists of hull angle speed, angular velocity, horizontal speed, vertical speed, position of joints and joints angular speed, legs contact with ground, and 10 lidar rangefinder measurements.
BipedalWalkerHardcore-v2 defines "solving" as getting average reward of 300 over 100 consecutive trials.
Leaderboard:
https://github.com/openai/gym/wiki/Leaderboard#bipedalwalkerhardcore-v2
'BipedalWalkerHardcore-v2' 的特点是地形的生成是完全随机的,这也是这个环境难的地方,训练的模型必须非常稳健才能拿到高平均分。
2. Leaderboard:
在Leaderboard上有两个解决了'BipedalWalkerHardcore-v2' 的项目。
一个是A3C+LSTM算法:https://github.com/dgriff777/a3c_continuous
另一个是CMA-ES算法:https://github.com/hardmaru/estool
这两个项目的共同点是都需要大量的环境交互次数,演化算法更是如此。
下图是A3C+LSTM项目首页的展示:
https://github.com/dgriff777/a3c_continuous/blob/master/demo/BPHC3.gif

我们尝试过A3C+LSTM算法,32核3GPU训练73小时后得到的最好解可以偶尔100平均超过300,由于这个环境的随机性很大,导致得分涨落很大,我们觉得solving的定义应该是大量trial的平均分(统计平均值)300+,比如1000次,10000次。结果计算了3次1000平均都只有292,并不能超过300。(项目作者给出的model的1000平均分为281,大家如有跑出统计平均分300+请告知。) 我们发现如果stump不是跨过去的,那么很有可能训练陷入了局部最优。
对于CMA-ES算法,因为算法效率比较低,我们没有尝试。下图是查阅到的训练情况数据:
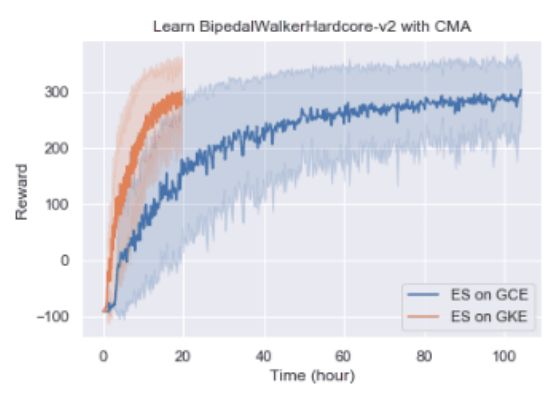
需要64核跑100个小时 Google Compute Engine (GCE)
或者1000核跑20个小时 Google Kubernetes Engine (GKE).
上面两种算法需要大量的环境交互,数据利用效率低。如果想把算法用在现实环境,提高数据利用效率是一个重要的研究方向。我们希望能高效地解决 'BipedalWalkerHardcore-v2'。
3. 算法和训练细节:
为此,我们采用state-of-the-art的model-free RL算法sac1来解决'BipedalWalkerHardcore-v2', sac1是基于sac(Soft Actor-Critic)算法的改进,精简了网络,引入了自适应训练熵权重。
sac1 论文:
https://arxiv.org/abs/1812.05905
sac1 伪代码:
https://github.com/createamind/DRL/blob/master/video_pic/sac1.png
sac1 tensorflow实现:
https://github.com/createamind/DRL/tree/master/spinup/algos/sac1
sac1和上面两种算法不同,sac1只需要一个actor就可以训练,使用sac1算法只需CPU单核训练(GPU不是必须的),达到同样效果训练时间却更少。
然而我们发现直接把sac1算法接入'BipedalWalkerHardcore-v2'训练没有任何效果,调参也无济于事。经过不断的调研和试错,这个环境最终才得以解决。代码详见createamind/DRL代码库sac1算法下的sac1_BipedalWalkerHardcore-v2.py。下面分享一下我们尝试的有效的trick和参数调节:
i. action repeat: 3
action repeat 有助于探索,加速训练,使策略更稳健
ii. done reward clip: 0.0
环境会在done之后返回一个-100的reward,但是在RL中done是一个非常强的学习信号,reward -100有些多余,而且reward -100的突变对值函数学习不利,这里把它clip为0
iii. alpha: 0.1
alpha是sac1算法的重要参数,会直接影响最终表现。
iv. reward scale: 5.0
reward scale可增大reward区分度,实验表明对reward进行放大可以提升最后的表现
v. learning rate: 1e-4
学习率可以先大后小地递减,提升训练速度
vi. action noise: 0.3
训练时在策略输出的动作里加入一些噪声可以让学习到的策略更稳健
vii. data balance
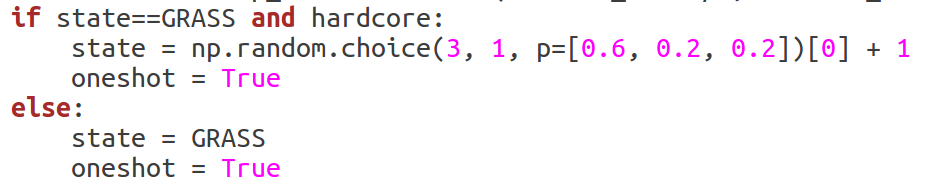
'BipedalWalkerHardcore-v2'有stumps, ladders, pitfalls 这3类障碍,我们发现学习到的策略对这3类障碍的表现是不一样的,其中stump最难学到稳健的策略。数据不平衡问题是深度学习中经常遇到的问题,可以使用PER或者调高生成环境时stump的概率解决, 我们发现配比1:1:1换成3:1:1确实可以提升最后的表现:
gym库中:lib/python3.6/site-packages/gym/envs/box2d/bipedal_walker.py
Line252:
PER(Prioritized Experience Replay)https://arxiv.org/abs/1511.05952
PER是在强化学习中解决数据不平衡问题的重要方法,通过Prioritize可以改变Replay Buffer中的数据分布,达到平衡数据的作用,以后有空加入。
这些trick在RL的文献里都有提及,RL的trick很多,列出的是我们实验发现有效的因素,训练时只需要里面的几个就可以解决'BipedalWalkerHardcore-v2'。我们相信只要注意到这些因素,用其他的RL算法一样也可以解决这个环境。
4. 实验结果
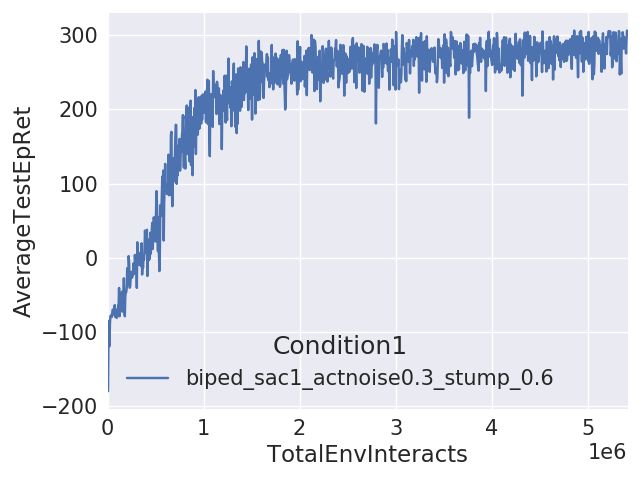
训练时保存AverageTestEpRet得分最高的模型即可。我们训练好的模型保存在createamind/DRL/saved_models中,跑sac1_test.py脚本即可看Test的效果。
值得注意的是我们得到的策略和A3C+LSTM算法不同,和CMA-ES算法相同(跨过stump)。随机3次100trials如下:



平均100的得分涨落比较大,我们计算模型的统计平均值为307:

307并不是最高分,因为训练曲线还在往上涨,没有到天花板,但是提升速度变慢,此外我们没有搜索参数空间,调参也可以进一步提升效果。更高的得分有机会再贴,也欢迎大家自己去尝试。
5. 总结
使用sac1算法解决'BipedalWalkerHardcore-v2',并在效果和效率两方面到达SOTA.
Engineering is magic..: )



