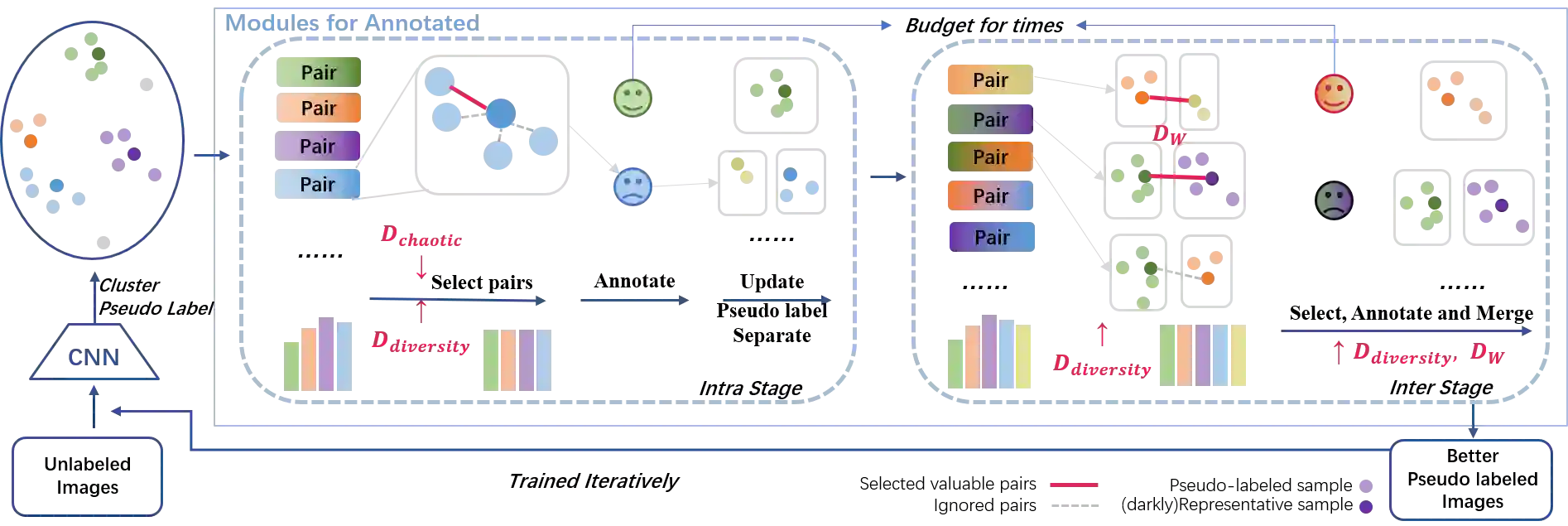
Person Re-identification (Re-ID) has attracted great attention due to its promising real-world applications. However, in practice, it is always costly to annotate the training data to train a Re-ID model, and it still remains challenging to reduce the annotation cost while maintaining the performance for the Re-ID task. To solve this problem, we propose the Annotation Efficient Person Re-Identification method to select image pairs from an alternative pair set according to the fallibility and diversity of pairs, and train the Re-ID model based on the annotation. Specifically, we design an annotation and training framework to firstly reduce the size of the alternative pair set by clustering all images considering the locality of features, secondly select images pairs from intra-/inter-cluster samples for human to annotate, thirdly re-assign clusters according to the annotation, and finally train the model with the re-assigned clusters. During the pair selection, we seek for valuable pairs according to pairs' fallibility and diversity, which includes an intra-cluster criterion to construct image pairs with the most chaotic samples and the representative samples within clusters, an inter-cluster criterion to construct image pairs between clusters based on the second-order Wasserstein distance, and a diversity criterion for clusterbased pair selection. Combining all criteria above, a greedy strategy is developed to solve the pair selection problem. Finally, the above clustering-selecting-annotating-reassigning-training procedure will be repeated until the annotation budget is reached. Extensive experiments on three widely adopted Re-ID datasets show that we can greatly reduce the annotation cost while achieving better performance compared with state-of-the-art works.
翻译:个人重新定位(Re-ID)因其具有希望的真实世界应用而引起极大关注。然而,在实践中,为培训重新ID模型而说明培训数据总是花费高昂的。然而,在实践上,我们设计一个批注和培训框架,首先通过将所有图像集中在一起,以降低批注成本,同时保持重新ID任务的业绩。为了解决这个问题,我们建议采用批注高效个人重新识别方法,根据对子的可失性和多样性从一组替代配对中选择成对图像配对,并基于批注来培训重新定位模型。具体地说,我们设计一个批注和培训框架,以便首先降低替代组合的规模,将所有图像集中在一起,考虑到地貌位置;从内部/跨组样本中选择成批注成本成本;根据批注重新定位,最后对模型进行培训。在选择配对中,我们寻求根据对子的可失和多样性进行有价值的配对,其中包括一个内部组内标准,以最混乱的样本和具有代表性的组群列组合,然后在最终的群集中构建一个标准,然后是一组数据,一个可以实现整个群集的群集选择。