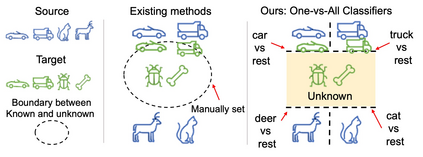
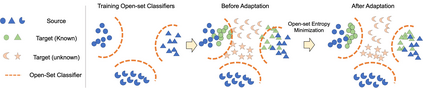
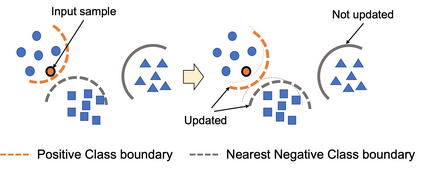
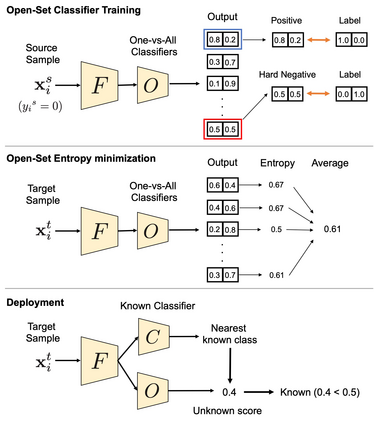
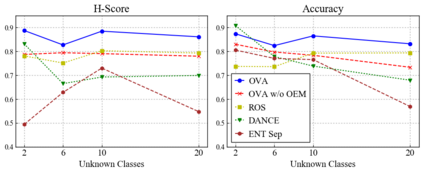
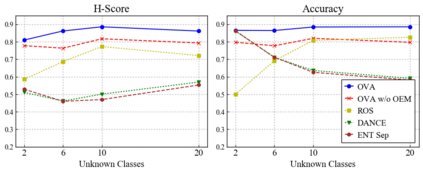
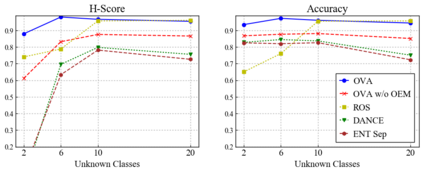
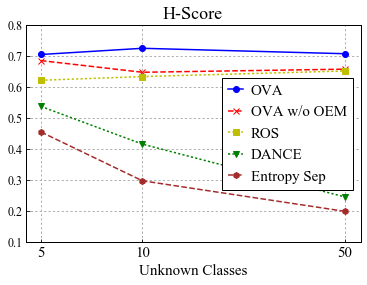
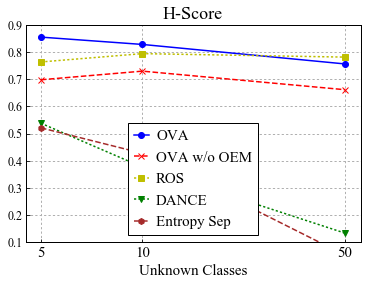
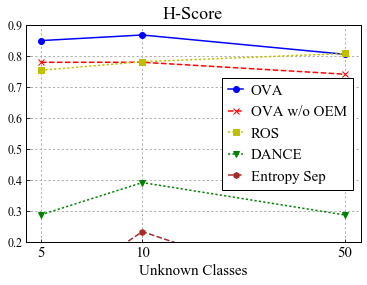
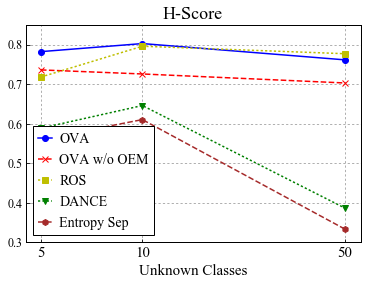
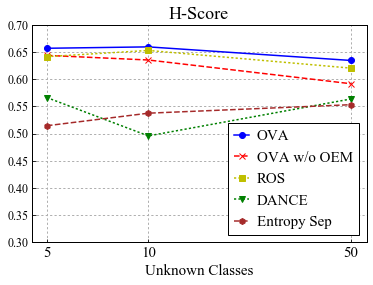
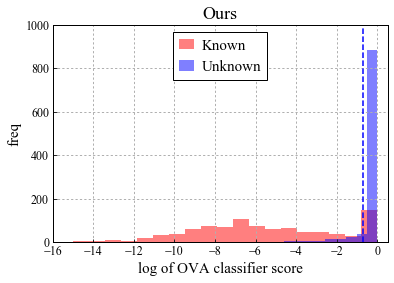
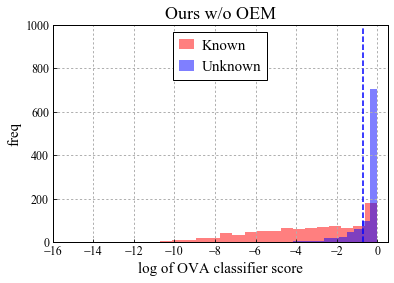
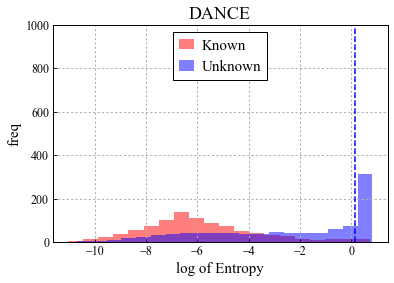
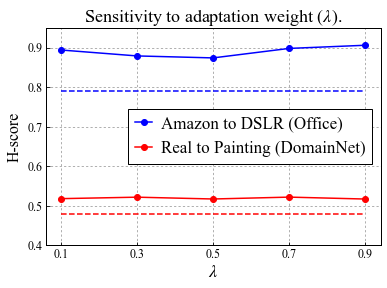
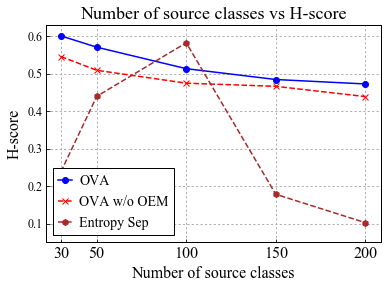
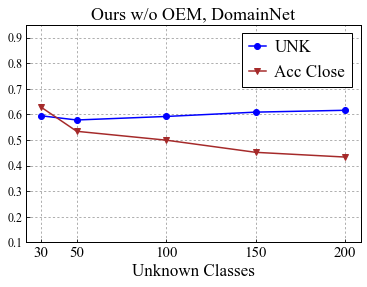
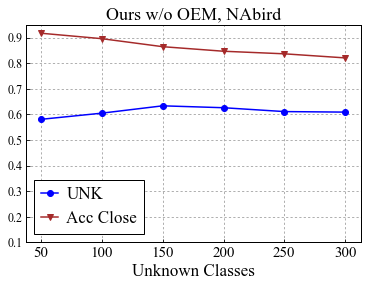
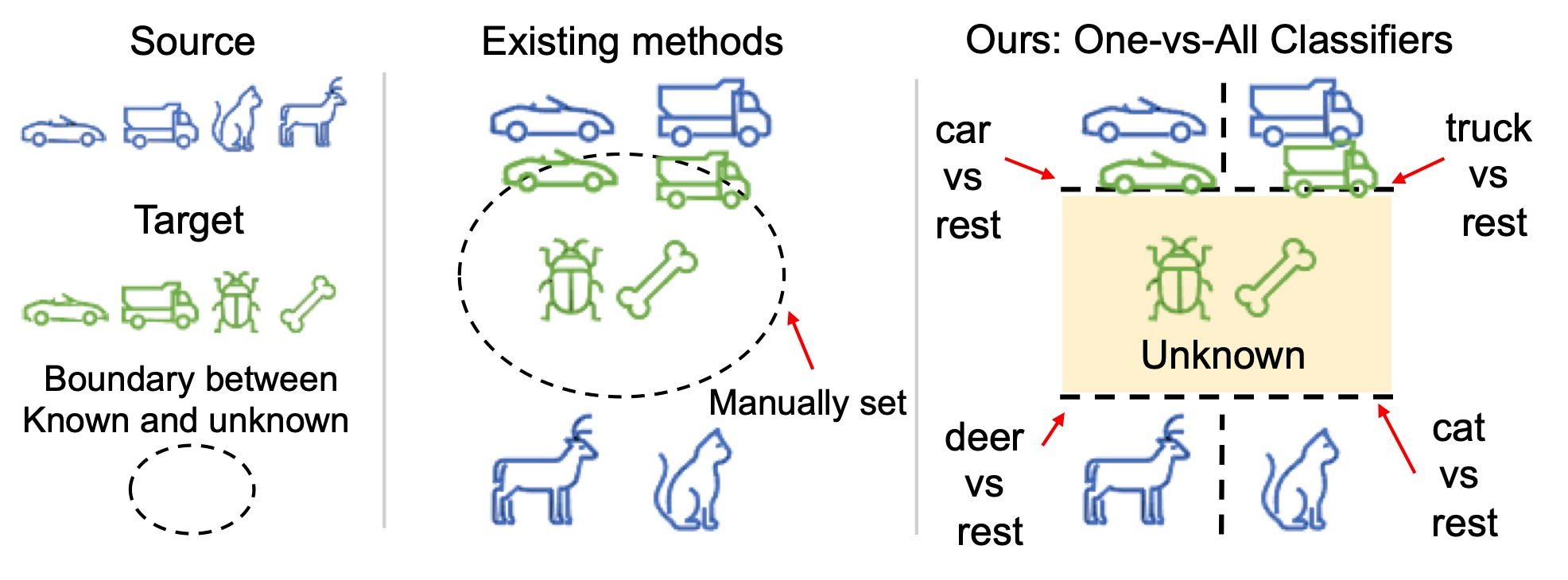
Universal Domain Adaptation (UNDA) aims to handle both domain-shift and category-shift between two datasets, where the main challenge is to transfer knowledge while rejecting unknown classes which are absent in the labeled source data but present in the unlabeled target data. Existing methods manually set a threshold to reject unknown samples based on validation or a pre-defined ratio of unknown samples, but this strategy is not practical. In this paper, we propose a method to learn the threshold using source samples and to adapt it to the target domain. Our idea is that a minimum inter-class distance in the source domain should be a good threshold to decide between known or unknown in the target. To learn the inter-and intra-class distance, we propose to train a one-vs-all classifier for each class using labeled source data. Then, we adapt the open-set classifier to the target domain by minimizing class entropy. The resulting framework is the simplest of all baselines of UNDA and is insensitive to the value of a hyper-parameter yet outperforms baselines with a large margin.
翻译:通用域适应 (UNDA) 旨在处理两个数据集之间的域档和类别档,其中主要的挑战在于转移知识,同时拒绝在标签源数据中不存在、但在未标签目标数据中存在的未知类别。 现有方法根据验证或未知样本的预定义比例,手工设定了拒绝未知样本的阈值, 但这一策略不切实际。 在本文中, 我们提出一种方法, 使用源样本来学习阈值, 并将其调整到目标域。 我们的想法是, 源域中最小的分类间距离应该是决定目标中已知或未知的值的良好阈值。 为了学习分类间和分类内距离, 我们提议使用标签源数据为每个类别培训一个一至五的分类器。 然后, 我们通过最小化分类酶, 将开放式定分级器调整到目标域。 由此产生的框架是UNDA的所有基线中最简单的, 并且对超分度但差值的基线值不敏感。