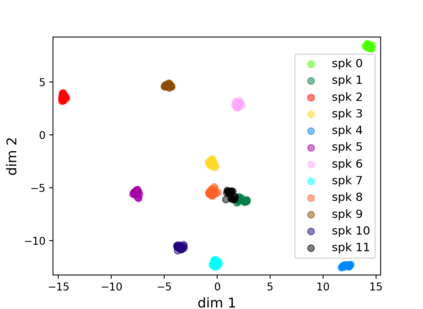
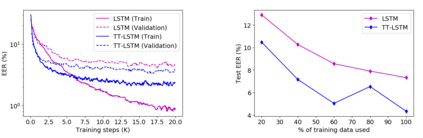
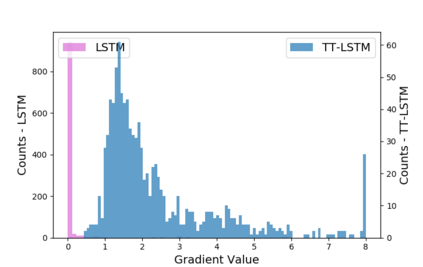
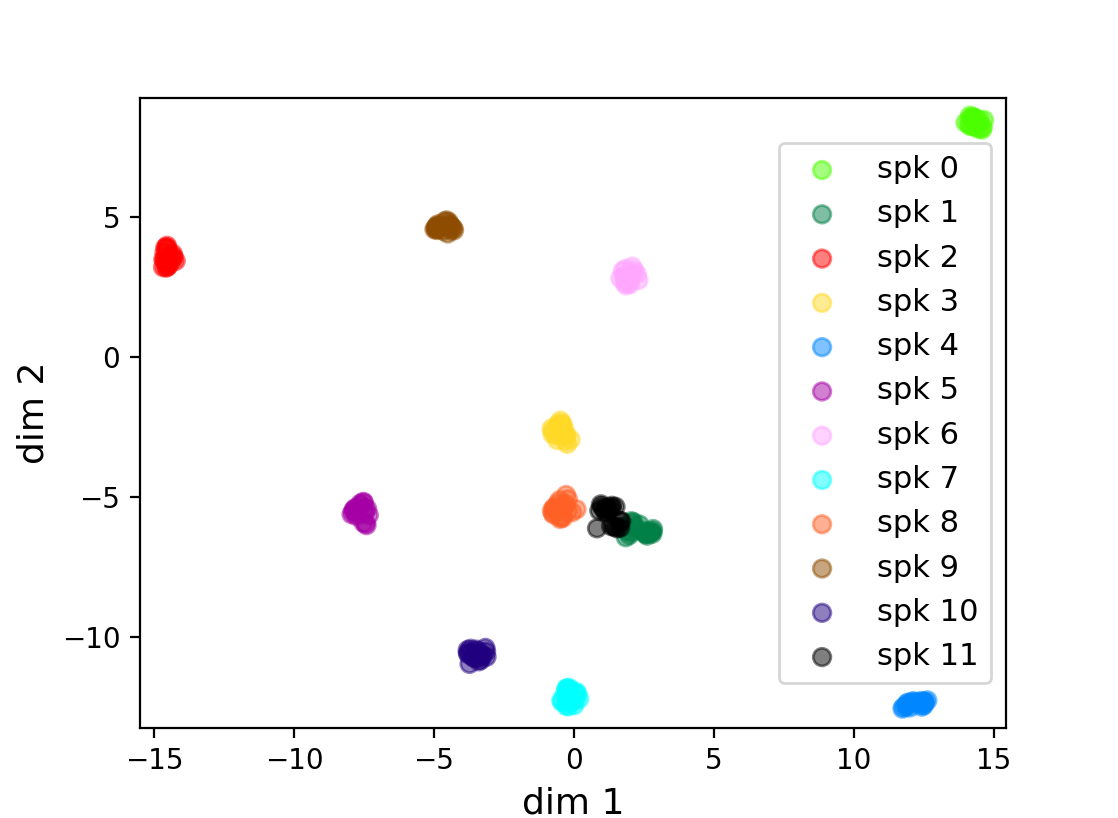
Recurrent neural networks (RNNs) are powerful tools for sequential modeling, but typically require significant overparameterization and regularization to achieve optimal performance. This leads to difficulties in the deployment of large RNNs in resource-limited settings, while also introducing complications in hyperparameter selection and training. To address these issues, we introduce a "fully tensorized" RNN architecture which jointly encodes the separate weight matrices within each recurrent cell using a lightweight tensor-train (TT) factorization. This approach represents a novel form of weight sharing which reduces model size by several orders of magnitude, while still maintaining similar or better performance compared to standard RNNs. Experiments on image classification and speaker verification tasks demonstrate further benefits for reducing inference times and stabilizing model training and hyperparameter selection.
翻译:经常性神经网络(RNN)是按顺序建模的有力工具,但通常需要大量的超参数化和正规化才能达到最佳性能,这导致在资源有限的环境中部署大型RNN难以做到,同时也在超参数的选择和培训方面造成复杂问题。为了解决这些问题,我们引入了“完全限制”的RNN结构,即利用轻量级压强(TT)因子化(TT)将每个经常电池中的单独重量矩阵联合编码起来。这一方法是一种新型的权重共享形式,它使模型大小减少几个数量级,同时保持与标准的RNNN的类似或更好的性能。关于图像分类和发言者核实任务的实验展示了减少推论时间、稳定模型培训和超参数选择的进一步好处。