Simple Recurrent Unit For Sentence Classification
声明:本文转载自公众号 黑龙江大学自然语言处理实验室,作者为黑龙江大学nlp实验室研究生刘宗林。
导读
本文讨论了最新爆款论文(Training RNNs as Fast as CNNs)提出的LSTM变种SRU(Simple Recurrent Unit),以及基于pytorch实现了SRU,并且在四个句子分类的数据集上测试了准确性以及与LSTM、CNN的速度对比。
一 、为什么要提出SRU?
深度学习的许多进展目前很多均是来源于增加的模型能力以及相关的计算,这经常涉及到更大、更深的深层神经网络,然而,虽然深层神经网络带来了明显的提升,但是也耗费了巨大的训练时间,特别是在语音识别以及机器翻译的模型训练上,要想获得一个最优的模型,往往要耗费几天的时间。
为了解决训练模型的计算能力,像利用GPU进行加速训练的并行化方法在深度学习领域已经广泛使用,使用GPU进行加速的卷积神经网络在训练速度上有提升的很明显,但是,像RNN、LSTM却无法实现并行化方法,熟悉RNN、LSTM的人都知道,在其典型的实现中,要想计算 ht 必须等到前一时刻ht-1计算完成,这明显的限制了其实现并行化处理,然而论文提出的简单循环单元(SRU)解除了这种限制,ht 的计算不在依赖于前一时刻的计算,这样就可以实现并行化处理,训练速度要比LSTM快,能够达到与CNN的一样的训练速度。
二 、SRU实现及其优化
1、SRU实现
熟悉LSTM和GRU的人都知道,它们是根据神经门来控制信息流来缓解梯度消失与梯度爆炸问题,所以,接下来我们看一下典型的SRU实现。
我们首先对输入的x进行简单的线性变换:

接下来计算遗忘门(forget gate)和 输入门,他们两个都是Sigmoid门:
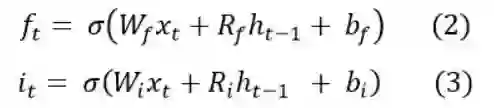
接下来我们计算c,在计算c的过程中,我们使用了共轭表达式 it = 1 - ft 来简化运算:

最后,我们把c传递给激活函数g来计算最终的输出h:
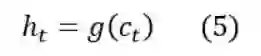
以上就是SRU的经典实现,熟悉LSTM的人一定能够看出来,这样的SRU与LSTM一样都是依赖于前一时刻的计算,这样的做法没有什么意义,接下来我们我们在对其进一步的改进。
SRU的实现中添加了两个附加的特征:
Skip Connection
具体来说,skip connection就是Highway Connection,对训练深层神经网络很有效果,我们来具体看一下公式:先设置一个重置门( reset gate),和遗忘门、输入门一样都是Sigmoid门:
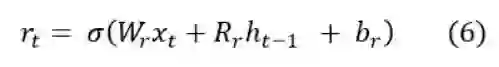
然后利用Skip Connection,ht‘ 就是最后的输出:
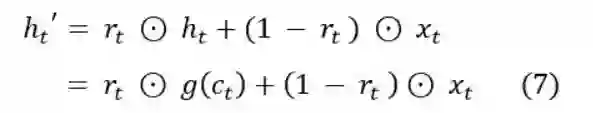
在后文的测试中,为什单层的SRU很难达到与LSTM相同的效果,而堆叠起来的多层SRU能够达到与LSTM相差无几甚至更好的效果,这里起到了很大的作用。
Variational dropout
为了RNN的正则化除了使用标准的dropout外,还使用了Variational dropout,Variational dropout 在不同的时间步骤 t 上共享 dropout mask。在 RNN 每一个矩阵乘法计算中(即 W * drop(x)),mask 需要应用到输入 x。标准的 dropout 是在 h上执行的,即没有馈送到高速连接的输出状态。
2、SRU加速优化
根据上文中的公式看出 ft 、 rt 都与 ht-1 有关,也就是要想计算 ht 必须等到前一时刻ht-1计算完成,这样就破换了并行性和独立性,无法实现并行化处理,针对此问题,提出了完全drop连接,就是去除了 ht-1 的依赖,以下是SRU的公式:
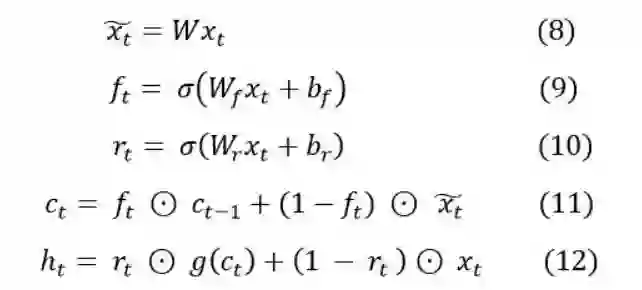
从上述(8)、(9)、(10)三个公式中可以看出,已经解除了ht-1 的依赖,这样依赖就可以实现程序的并行化处理,而公式(11),(12)能够非常迅速和简洁的执行计算,因为它们的运算都是对应元素之间的操作。
3、CUDA优化
在上述公式8 —- 10中,虽然解除了前一时刻的依赖,但是仍然存在一定的瓶颈,就是三个矩阵乘法的运算,在这里提供了更深的优化策略。
矩阵乘法在所有的时间步骤中可以进行批处理,可以显著的提高计算的强度和提高GPU的利用率,在8 —- 10 的公式中,可以把矩阵乘法可以合成一个,以后的处理就可以根据索引查找,具体如下:
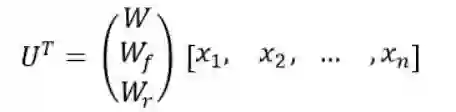
对于序列中的元素间的操作可以编译合并到一个内核函数中并在隐藏维度上并行化。
三 、基于pytorch实现SRU Networks
1、SRU Networks Structure Diagram
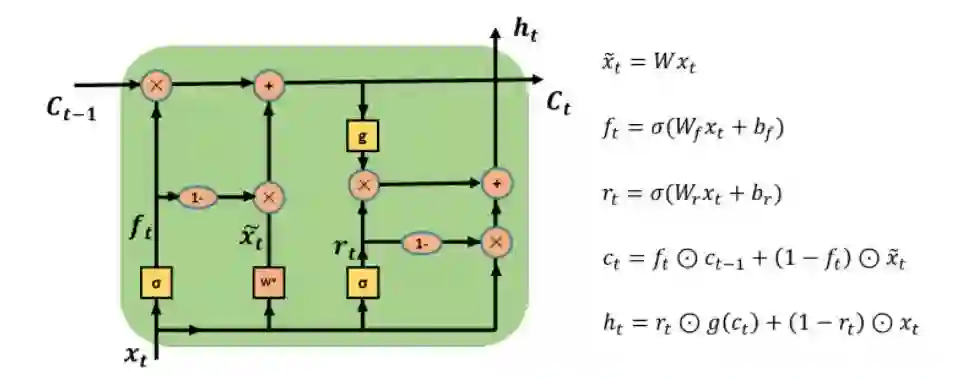
熟悉LSTM的人很容易理解SRU的网络结构图,下图是SRU的网络结构图:
xt 代表 t 时刻的输入;
W、b 代表权重和偏置;
ft 代表 t 时刻的遗忘门(forget gate);
rt 代表 t 时刻的重置门(reset gate);
ct 和 ht 分别代表 t 时刻的状态和最终的输出;
σ 和 g 分别代表Sigmoid函数和激活函数(tanh、relu);
公式中的 ⊙ 代表矩阵对应元素间的操作;
2、基于pytorch实现SRU Formula
pytorch搭建神经网络一般需要继承nn.Module这个类,然后实现里面的forward()函数,现在搭建SRU Networks需要另外写一个SRU Cell 类,Cell 里面实现SRU的全部运算,具体代码如下:
SRU_Formula类:class SRU_Formula(nn.Module): super(SRU_Formula, self).__init__() # 初始化参数 ...... # 调用Cell self.sru = SRU_Formula_Cell(self.args, n_in=D, n_out=self.hidden_dim, layer_numbers=self.num_layers, dropout=args.dropout, bias=True)
def forward(self, x): # 实现forward函数SRu Cell类:class SRU_Formula_Cell(nn.Module): def __init__(self, args, n_in, n_out, layer_numbers=1, dropout=0.0, bias=True): super(SRU_Formula_Cell, self).__init__() # 初始化参数 ......
def forward(self, xt, ct_forward): # 实现forward函数,在这里实现SRU的公式在这里我实现了多层的SRU搭建,对于维度不等的经过线性转换(
Linear),以下是这部分的代码:layer = self.layer_numbers # 多层SRU计算 for layers in range(layer):
if xt.size(2) == self.n_out: # 通过线性转换保证维度一致 xt = self.convert_x_layer(xt) xt, ct = SRU_Formula_Cell.calculate_one_layer(self, xt, ct_forward[layers])calculate one layer函数实现了SRU的计算:def calculate_one_layer(self, xt, ct_forward): # ct 是前一时刻的状态 ct = ct_forward # ht_list 保存的是最终的输入 ht_list = [] # xt.size(0)是句子的长度,SRU和LSTM一样,是一个词一个词的进行计算 for i in range(xt.size(0)): # x_t^ = W * x_t x_t = self.x_t(xt[i]) # f_t = σ( W_f * x_t + b_f ) ft = F.sigmoid(self.ft(xt[i])) # r_t = σ( W_r * x_t + b_r ) rt = F.sigmoid(self.rt(xt[i])) # c_t = f_t ⊙ c_(t-1) + (1 - f_t) ⊙ x_t^ ct = torch.add(torch.mul(ft, ct), torch.mul((1 - ft), x_t)) # 线性转换 con_xt = self.convert_x(xt[i]) # h_t= r_t ⊙ g(c_t) + (1 - r_t) ⊙ x_t ht = torch.add(torch.mul(rt, F.tanh(ct)), torch.mul((1 - rt), con_xt)) ht_list.append(ht.unsqueeze(0)) # concat the list ht = torch.cat(ht_list, 0)
return ht, ct
以上是SRU的公式实现,由于代码没有进行
CUDA优化也没有进行并行化处理,所以速度上并没有明显的改变。Github链接:https://github.com/bamtercelboo/pytorch_SRU
3、调用论文代码实现SRU
由于论文封装的代码比较不错,可以像LSTM一样简单调用:
self.sru = cuda_functional.SRU(input_size=D, hidden_size=self.hidden_dim, num_layers=self.num_layers, dropout=self.args.dropout, bidirectional=False)其中
cuda_functional是论文中已经封装好的SRU,在这里SRU实现了CUDA的优化,并对程序进行了并行化处理,所以速度上有了明显的提升,下文的测试也是基于此SRU与pytorch优化过的LSTM、CNN进行对比,测试结果参考下文。具体的使用可以参考论文的Github,以下是链接:Github链接:https://github.com/bamtercelboo/pytorch_SRUPaper Github链接:https://github.com/taolei87/sru/tree/master/classification
四 、实验结果
1、数据集
本次实验任务是情感分类任务(二分类),数据来源于MR(电影评论数据集)、CR(客户对各种产品评价的数据集)、Subj(主观性数据集)以及Twitter情感分类数据集,以下是各个数据集的详细信息:
下图是MR、CR、Subj数据集的详细信息,测试采用十折交叉验证,下载数据从
Github:https://github.com/harvardnlp/sent-conv-torch/tree/master/data

下图是Twitter情感分类数据集的详细信息:

2、SRU、LSTM、CNN准确率对比
以下实验结果是在CR、Subj、MR、Twitter四个句子分类数据集上测试的结果:
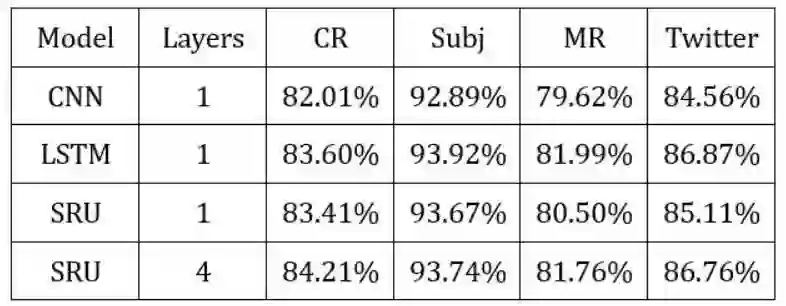
实验结果:在四个数据集上SRU与LSTM的准确率相差不大,有的数据集(像CR、Subj)一层的SRU效果就能达到一层LSTM的效果,但是在MR、Twitter数据集上一层的效果反而不是很好,需要叠加多层SRU才能达到LSTM一层的效果,这与上文提及的Highway Connection有很大的关系。
3、SRU、LSTM、CNN速度对比
以下实验结果是在Twitter数据集上对forward和backward测试的平均运行时间,其中SRU、LSTM、CNN都是经过CUDA优化的,CNN的kernel-size=3,SRU和LSTM的隐层维度是300,三个模型的batch size是16,以毫秒为单位计算,图中SRU-1代表一层的SRU模型:


实验结果:从上述实验结果能够说明在句子分类任务上,单层的SRU能够达到与CNN相同的速度,比LSTM快2 — 3倍;上文测试需要4层SRU才能达到一层LSTM效果的情况下,4层SRU能与一层LSTM的达到相同的速度。
References
[1] Tao Lei and Yu Zhang. Training RNNs as Fast as CNNs. arXiv:1709.02755, 2017.
[2] James Bradbury, Stephen Merity, Caiming Xiong, and Richard Socher. Quasi-recurrent neural
networks. In ICLR, 2017.
[3] Yarin Gal and Zoubin Ghahramani. A theoretically grounded application of dropout in recurrent
neural networks. In Advances in Neural Information Processing Systems 29 (NIPS), 2016.
[4] Jeremy Appleyard, Tomas Kocisky, and Phil Blunsom. Optimizing performance of recurrent neural networks on gpus. arXiv preprint arXiv:1604.01946, 2016.
本期责任编辑: 张伟男
本期编辑: 蔡碧波
“哈工大SCIR”公众号
主编:车万翔
副主编: 张伟男,丁效
责任编辑: 张伟男,丁效,赵森栋,刘一佳
编辑: 李家琦,赵得志,赵怀鹏,吴洋,刘元兴,蔡碧波
长按下图并点击 “识别图中二维码”,即可关注哈尔滨工业大学社会计算与信息检索研究中心微信公共号:”哈工大SCIR” 。



