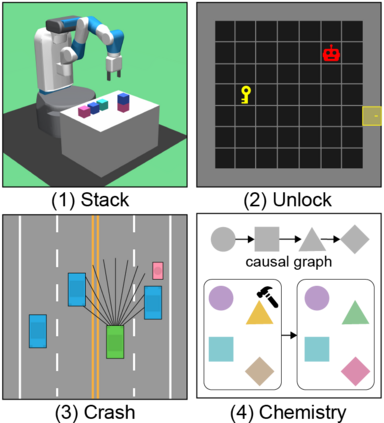
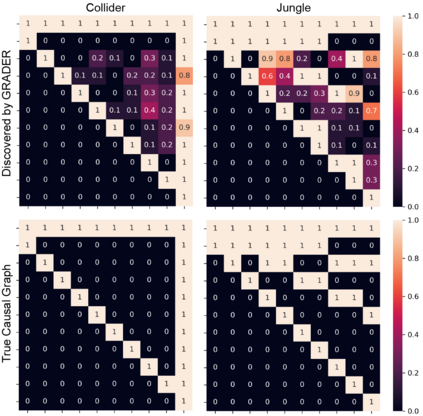
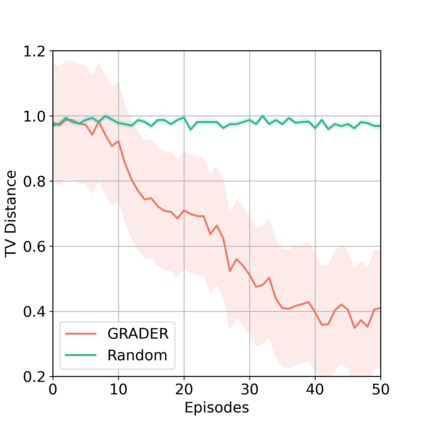
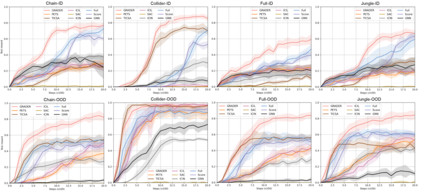
As a pivotal component to attaining generalizable solutions in human intelligence, reasoning provides great potential for reinforcement learning (RL) agents' generalization towards varied goals by summarizing part-to-whole arguments and discovering cause-and-effect relations. However, how to discover and represent causalities remains a huge gap that hinders the development of causal RL. In this paper, we augment Goal-Conditioned RL (GCRL) with Causal Graph (CG), a structure built upon the relation between objects and events. We novelly formulate the GCRL problem into variational likelihood maximization with CG as latent variables. To optimize the derived objective, we propose a framework with theoretical performance guarantees that alternates between two steps: using interventional data to estimate the posterior of CG; using CG to learn generalizable models and interpretable policies. Due to the lack of public benchmarks that verify generalization capability under reasoning, we design nine tasks and then empirically show the effectiveness of the proposed method against five baselines on these tasks. Further theoretical analysis shows that our performance improvement is attributed to the virtuous cycle of causal discovery, transition modeling, and policy training, which aligns with the experimental evidence in extensive ablation studies.
翻译:作为在人类情报中实现普遍适用的解决办法的关键组成部分,推理为强化学习(RL)代理人对不同目标的概括化提供了巨大的潜力,其方法是总结部分到整体的论据,并发现因果关系;然而,如何发现和代表因果关系仍是一个巨大的差距,阻碍因果RL的发展。在本文中,我们用Causal Graph(CG)来补充基于天体与事件之间关系的结构,即目标-受精RL(GCRL),这是基于天体与事件之间关系的结构。我们新将GCRL问题发展成以CG为潜在变量的变异可能性最大化。为了优化衍生目标,我们提出了一个具有理论性能保障的框架,在两个步骤之间交替:使用干预性数据来估计CG的后身;利用CG学习可实现的模型和可解释的政策。由于缺乏公共基准来核查推理中的概括化能力,我们设计了九项任务,然后从经验上展示了拟议方法相对于这些任务的五个基线的有效性。进一步的理论分析表明,我们的绩效改进归因于因果关系发现、过渡模型和政策培训的广泛实验证据。