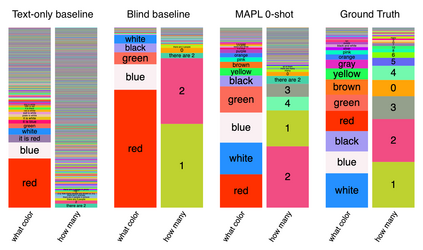
Large pre-trained models have proved to be remarkable zero- and (prompt-based) few-shot learners in unimodal vision and language tasks. We propose MAPL, a simple and parameter-efficient method that reuses frozen pre-trained unimodal models and leverages their strong generalization capabilities in multimodal vision-language (VL) settings. MAPL learns a lightweight mapping between the representation spaces of unimodal models using aligned image-text data, and can generalize to unseen VL tasks from just a few in-context examples. The small number of trainable parameters makes MAPL effective at low-data and in-domain learning. Moreover, MAPL's modularity enables easy extension to other pre-trained models. Extensive experiments on several visual question answering and image captioning benchmarks show that MAPL achieves superior or competitive performance compared to similar methods while training orders of magnitude fewer parameters. MAPL can be trained in just a few hours using modest computational resources and public datasets. We plan to release the code and pre-trained models.
翻译:在单一方式的视觉和语言任务方面,我们建议采用大型的预先培训模型,这种简单和有参数效率的方法,重新利用冻结的事先培训的单一方式模型,并在多式视觉语言(VL)环境中利用其强大的概括性能力。MAPL学会了在单一方式模型代表空间之间使用统一图像文本数据进行轻量的绘图,并能够从仅有的几个文本内例子中概括到隐蔽的VL任务。少量的可培训参数使得MAPL在低数据和日常学习方面有效。此外,MAPL的模块化使其他预先培训的模式易于扩展。关于几个视觉问题回答和图像说明基准的广泛实验表明,MAPL在类似方法上取得了优劣或竞争性的成绩,而培训的参数则较少。MAPL可以仅仅用几个小时的微量的计算资源和公共数据集来培训。我们计划发布代码和预培训模式。