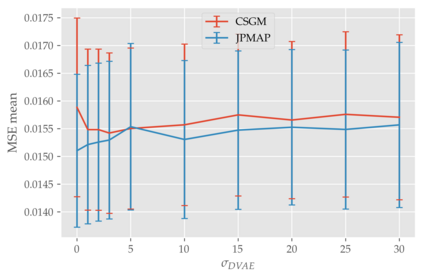
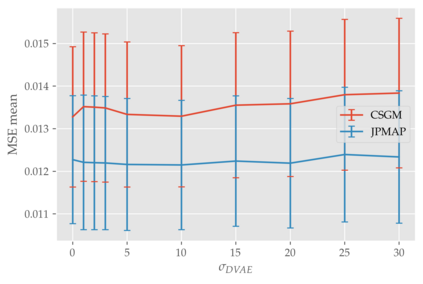
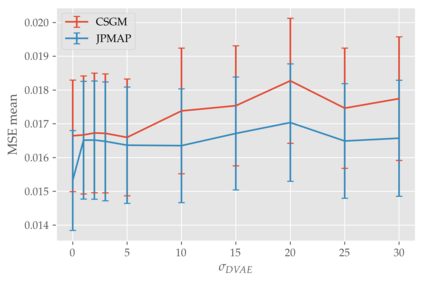
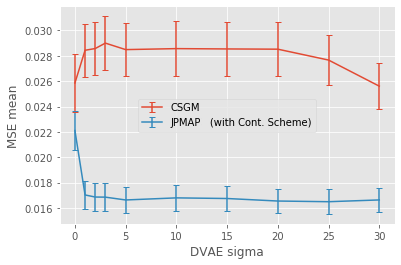
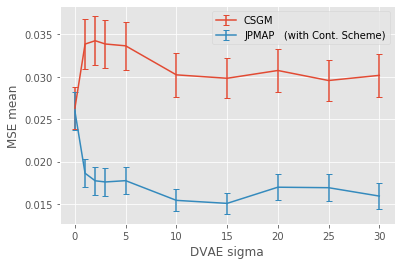
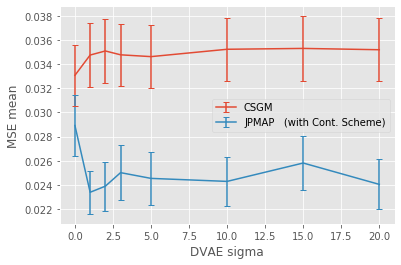
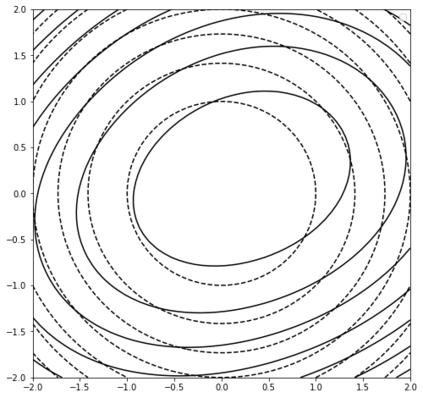
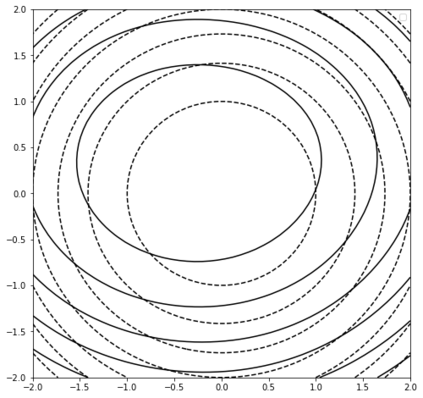
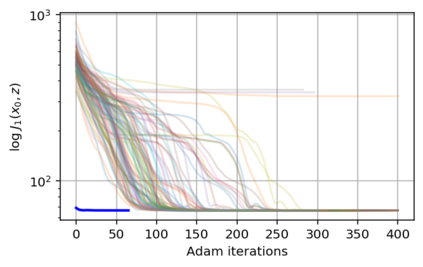
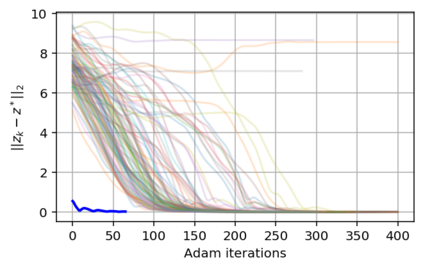
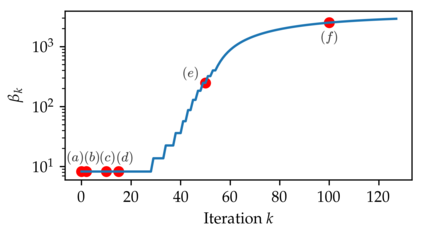
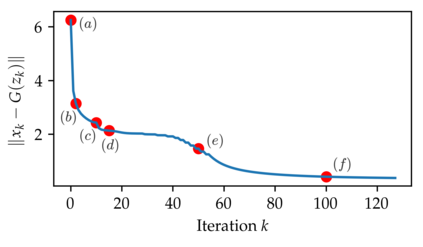
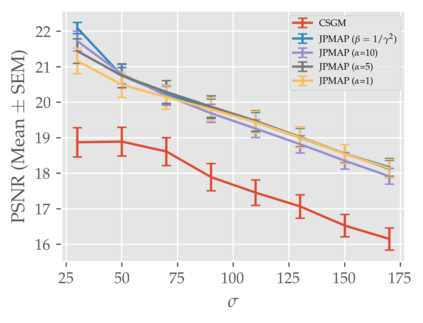
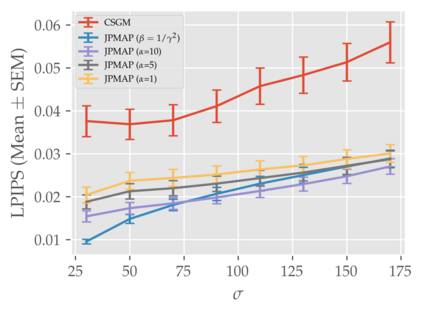
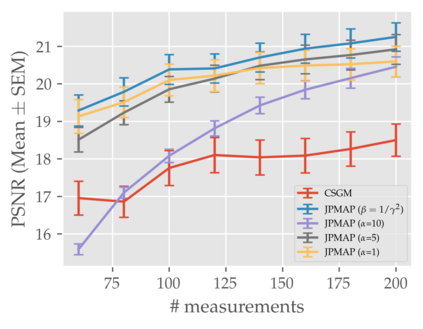
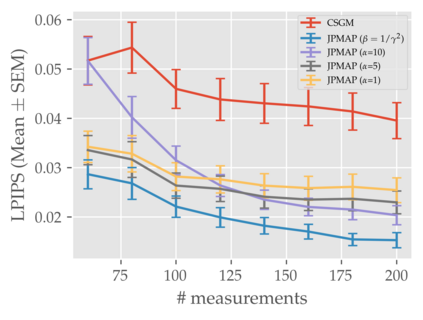
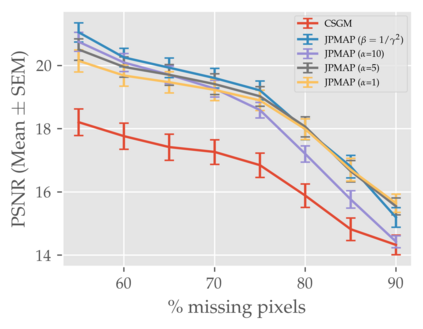
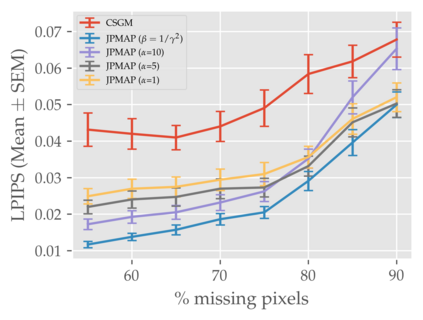
In this work we address the problem of solving ill-posed inverse problems in imaging where the prior is a variational autoencoder (VAE). Specifically we consider the decoupled case where the prior is trained once and can be reused for many different log-concave degradation models without retraining. Whereas previous MAP-based approaches to this problem lead to highly non-convex optimization algorithms, our approach computes the joint (space-latent) MAP that naturally leads to alternate optimization algorithms and to the use of a stochastic encoder to accelerate computations. The resulting technique (JPMAP) performs Joint Posterior Maximization using an Autoencoding Prior. We show theoretical and experimental evidence that the proposed objective function is quite close to bi-convex. Indeed it satisfies a weak bi-convexity property which is sufficient to guarantee that our optimization scheme converges to a stationary point. We also highlight the importance of correctly training the VAE using a denoising criterion, in order to ensure that the encoder generalizes well to out-of-distribution images, without affecting the quality of the generative model. This simple modification is key to providing robustness to the whole procedure. Finally we show how our joint MAP methodology relates to more common MAP approaches, and we propose a continuation scheme that makes use of our JPMAP algorithm to provide more robust MAP estimates. Experimental results also show the higher quality of the solutions obtained by our JPMAP approach with respect to other non-convex MAP approaches which more often get stuck in spurious local optima.
翻译:在这项工作中,我们处理的是解决图像中不正确反向问题的问题,因为前者是变式自动编码器(VAE),而前者是变式自动编码器(VAE),具体地说,我们考虑的是分解的个案,前者经过一次培训,可以重新用于许多不同的日志混凝土降解模型,而无需再培训。虽然以前基于MAP的处理方法导致高度非混凝土优化算法,但我们的方法对联合(空间拉动)MAP进行了计算,这自然导致替代优化算法,并导致使用常态编码编码编码器来加速计算。由此产生的技术(JPMAP)利用“自动编码前”进行联合波斯内端最大化。我们展示了理论和实验性证据表明,拟议的目标功能非常接近双相近,这足以保证我们的优化方案与一个固定点相匹配。我们还强调了正确培训VAE的通用方法的重要性,通过一种调控标准,确保模型能够很好地概括到升级后质量,同时展示了我们这个普通的IMU的升级方法。