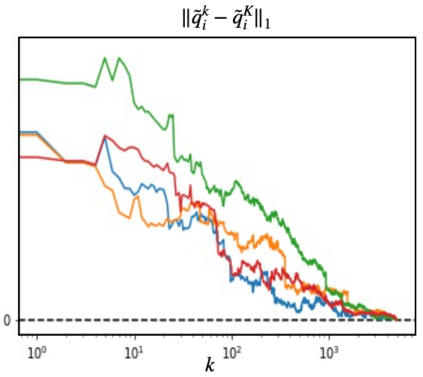
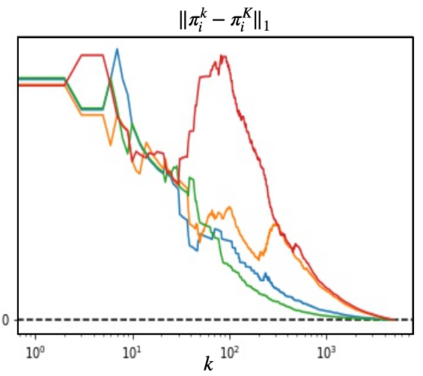
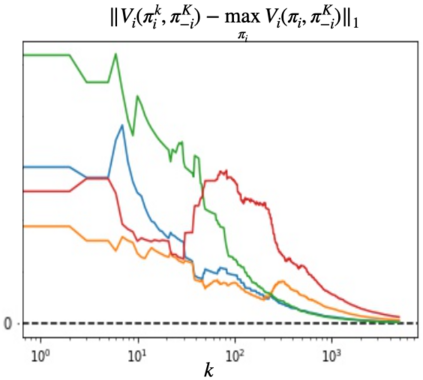
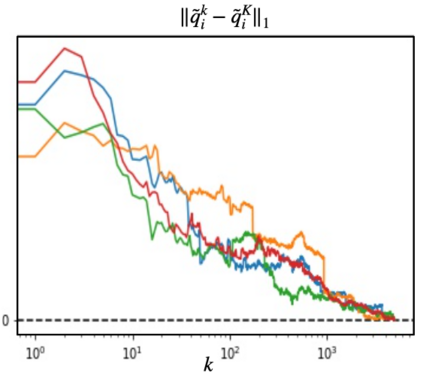
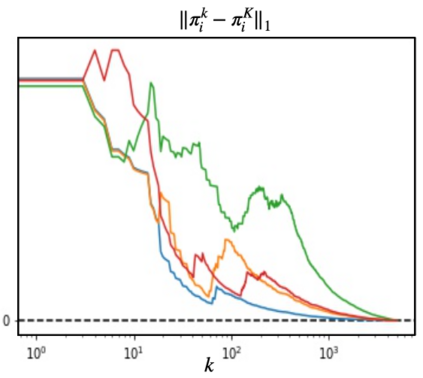
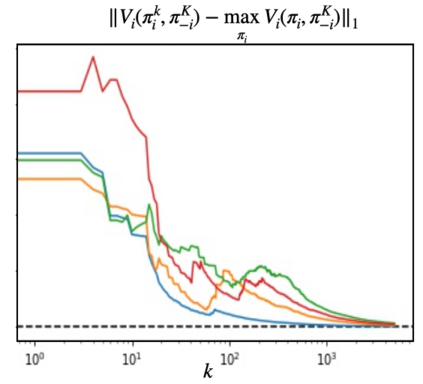
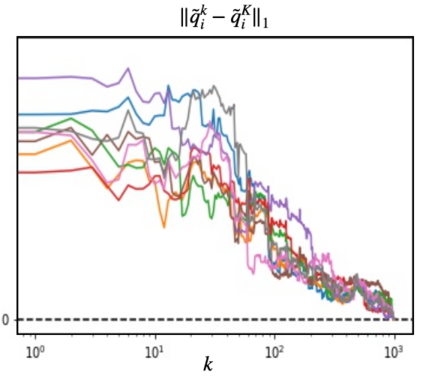
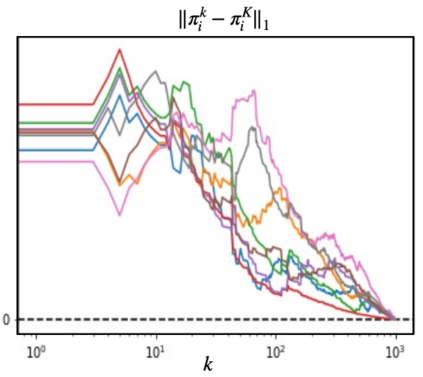
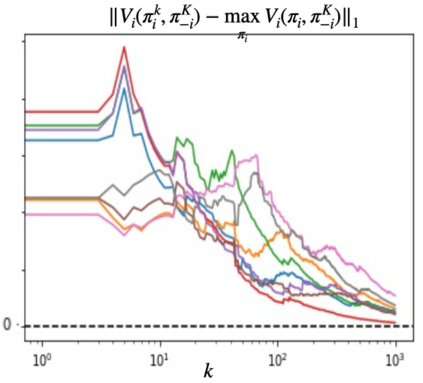
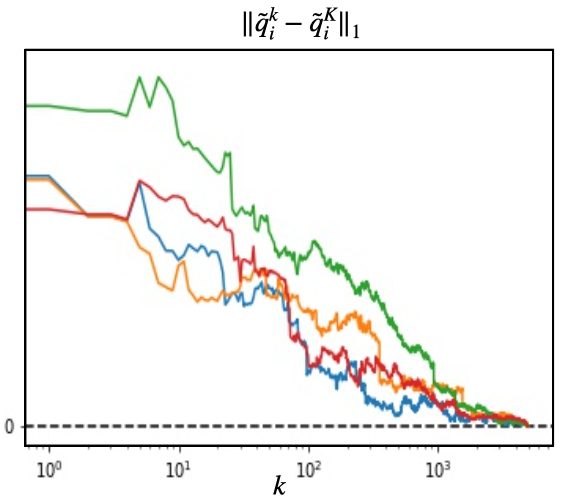
We propose a multi-agent reinforcement learning dynamics, and analyze its convergence properties in infinite-horizon discounted Markov potential games. We focus on the independent and decentralized setting, where players can only observe the realized state and their own reward in every stage. Players do not have knowledge of the game model, and cannot coordinate with each other. In each stage of our learning dynamics, players update their estimate of a perturbed Q-function that evaluates their total contingent payoff based on the realized one-stage reward in an asynchronous manner. Then, players independently update their policies by incorporating a smoothed optimal one-stage deviation strategy based on the estimated Q-function. A key feature of the learning dynamics is that the Q-function estimates are updated at a faster timescale than the policies. We prove that the policies induced by our learning dynamics converge to a stationary Nash equilibrium in Markov potential games with probability 1. Our results build on the theory of two timescale asynchronous stochastic approximation, and new analysis on the monotonicity of potential function along the trajectory of policy updates in Markov potential games.
翻译:我们建议多试剂强化学习动态, 并分析其在无限象素折扣的Markov潜在游戏中的趋同特性。 我们关注独立和分散的场景, 玩家只能在每个阶段观察已经实现的状态和他们自己的奖赏。 玩家对游戏模式并不了解, 并且无法相互协调。 在学习动态的每个阶段, 玩家更新了他们对于受干扰的Q- 功能的估计, 根据已经实现的一阶段奖赏, 以不同步的方式评估他们的总或有报酬。 然后, 玩家独立更新他们的政策, 根据估计的Q- 功能, 引入一个平稳的最佳一阶段偏差战略 。 学习动态的一个关键特征是, Q- 功能估计的更新速度比政策要快。 我们证明, 我们学习动态所引发的政策与马尔科夫 潜在游戏的定点纳什平衡相交汇合, 概率 1. 我们的结果建立在两个时间尺度的不同步的随机近近理论基础上, 并且根据Markov 潜在游戏中政策更新的轨迹对潜在功能的单一性进行新的分析 。