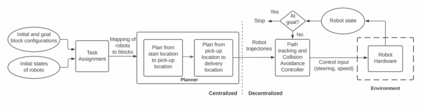
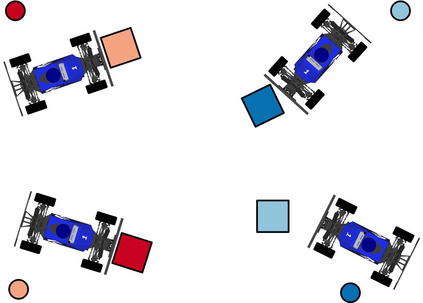
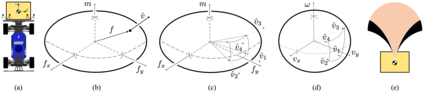
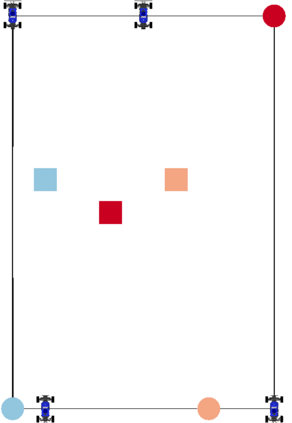
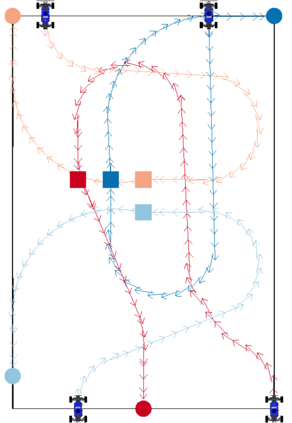
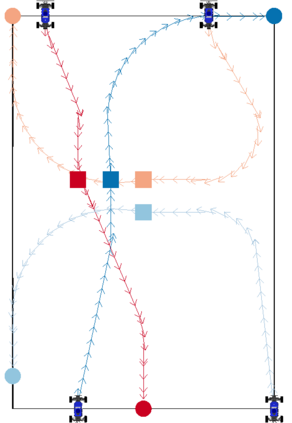
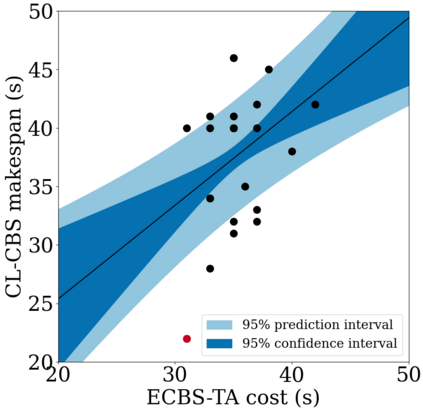
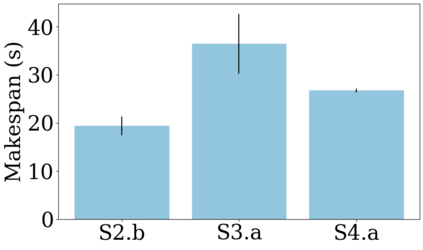
We focus on the problem of rearranging a set of objects with a team of car-like robot pushers built using off-the-shelf components. Maintaining control of pushed objects while avoiding collisions in a tight space demands highly coordinated motion that is challenging to execute on constrained hardware. Centralized replanning approaches become intractable even for small-sized problems whereas decentralized approaches often get stuck in deadlocks. Our key insight is that by carefully assigning pushing tasks to robots, we could reduce the complexity of the rearrangement task, enabling robust performance via scalable decentralized control. Based on this insight, we built PuSHR, a system that optimally assigns pushing tasks and trajectories to robots offline, and performs trajectory tracking via decentralized control online. Through an ablation study in simulation, we demonstrate that PuSHR dominates baselines ranging from purely decentralized to fully decentralized in terms of success rate and time efficiency across challenging tasks with up to 4 robots. Hardware experiments demonstrate the transfer of our system to the real world and highlight its robustness to model inaccuracies. Our code can be found at https://github.com/prl-mushr/pushr, and videos from our experiments at https://youtu.be/DIWmZerF_O8.
翻译:我们的重点是重新排列一组用现成部件建造的汽车类机器人推推器组成的一组物体的问题。 维持对被推的物体的控制,同时避免在紧凑的空间中发生碰撞,需要高度协调的动作,这对于执行受限制的硬件是具有挑战性的。 中央化的再规划方法甚至对于小型问题也变得棘手,而分散化的方法往往陷入僵局。 我们的关键洞察力是,通过向机器人仔细分配推力任务,我们可以通过可缩放的分散控制来降低重新安排任务的复杂性,从而通过可扩缩的分散控制实现稳健的性能。 基于这一洞察力,我们建立了PusHR,这是一个将推力任务和轨迹最理想地分配给离线机器人的系统,并且通过在线分散控制进行轨迹跟踪。 通过模拟的减缩研究,我们证明PusHR在从纯粹分散到完全分散的成功率和时间效率的基线上,从4个具有挑战性的任务到4个机器人。 硬体实验显示我们系统向真实世界的转移,并突出其稳健性到模型的不精确性。 我们的代码可以在 https://githhubub.com/prbarhrmus/Wrbuboursum/sumarmaus/surmus8。</s>