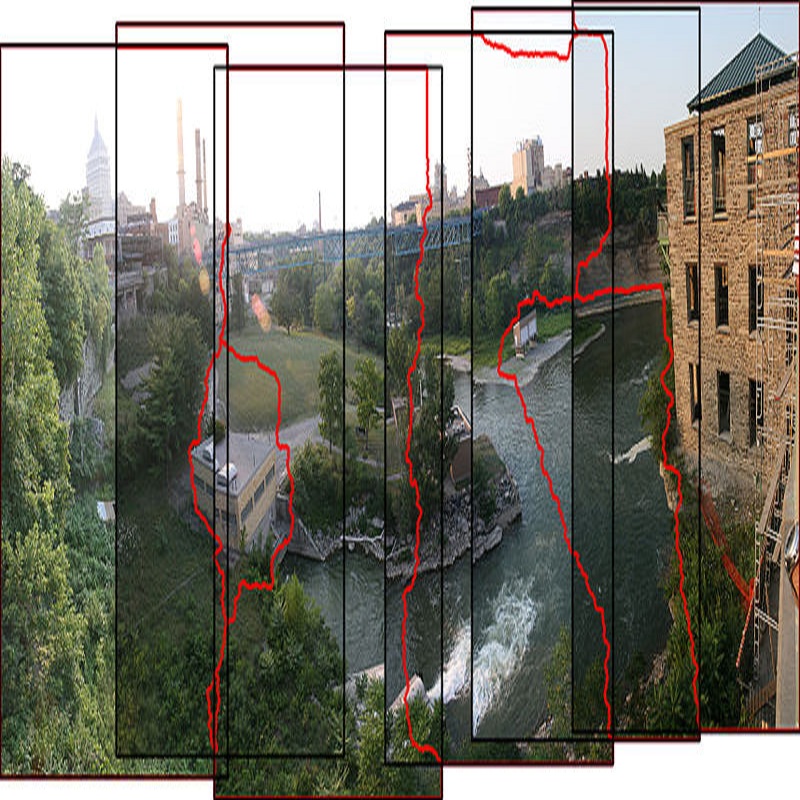
Current image stitching methods often produce noticeable seams in challenging scenarios such as uneven hue and large parallax. To tackle this problem, we propose the Reference-Driven Inpainting Stitcher (RDIStitcher), which reformulates the image fusion and rectangling as a reference-based inpainting model, incorporating a larger modification fusion area and stronger modification intensity than previous methods. Furthermore, we introduce a self-supervised model training method, which enables the implementation of RDIStitcher without requiring labeled data by fine-tuning a Text-to-Image (T2I) diffusion model. Recognizing difficulties in assessing the quality of stitched images, we present the Multimodal Large Language Models (MLLMs)-based metrics, offering a new perspective on evaluating stitched image quality. Compared to the state-of-the-art (SOTA) method, extensive experiments demonstrate that our method significantly enhances content coherence and seamless transitions in the stitched images. Especially in the zero-shot experiments, our method exhibits strong generalization capabilities. Code: https://github.com/yayoyo66/RDIStitcher
翻译:暂无翻译