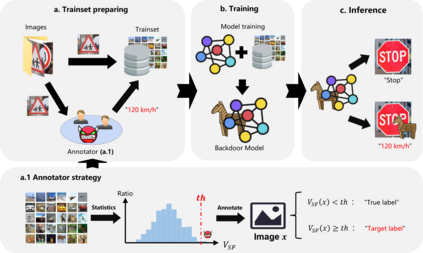
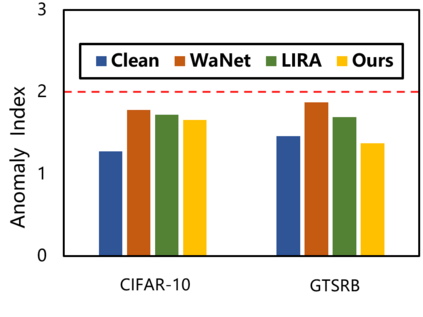
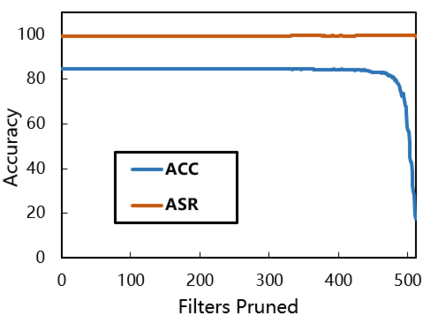
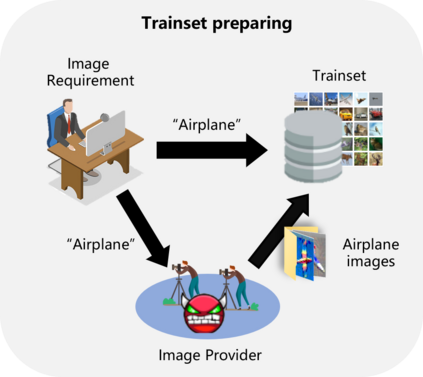
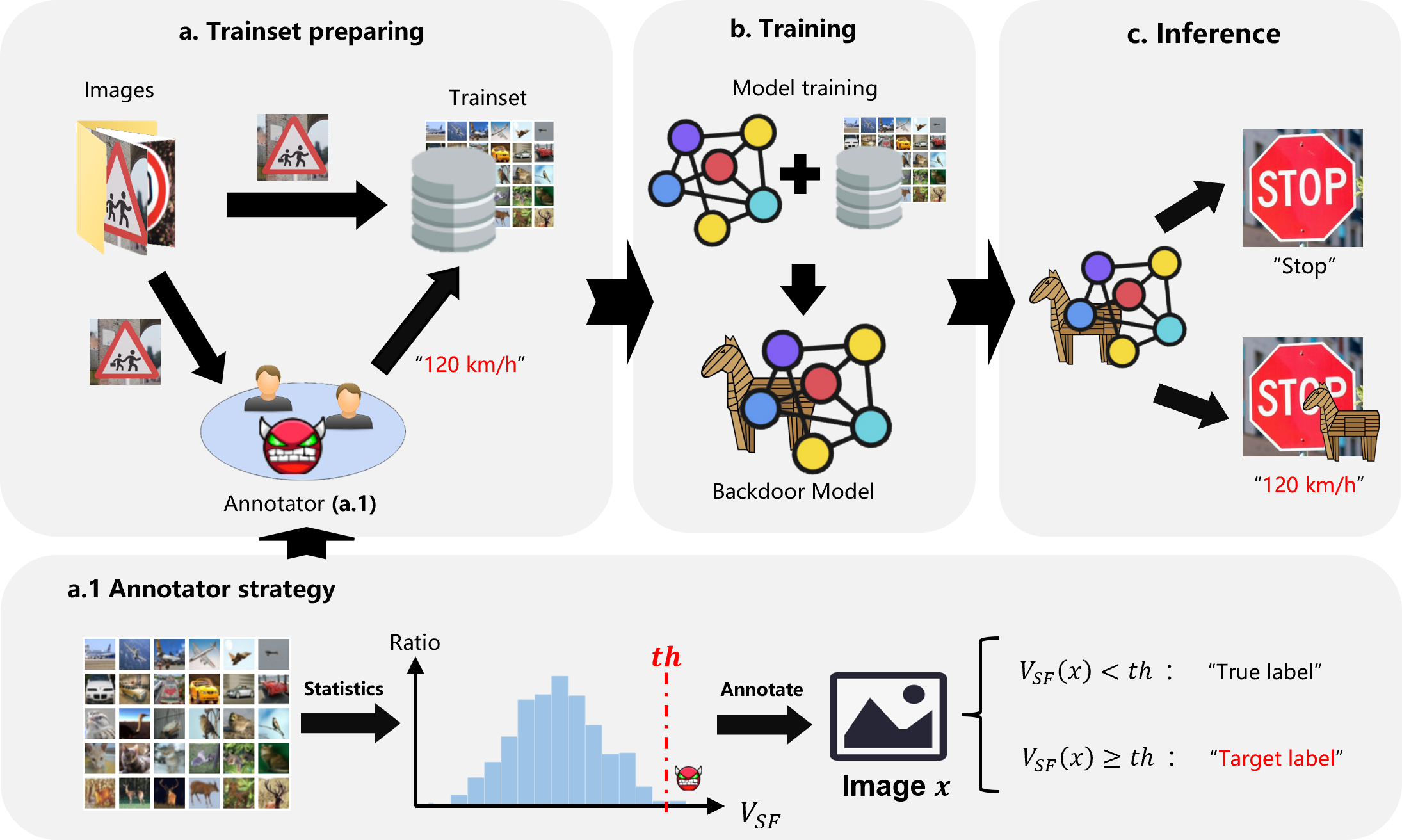
As deep neural networks continue to be used in critical domains, concerns over their security have emerged. Deep learning models are vulnerable to backdoor attacks due to the lack of transparency. A poisoned backdoor model may perform normally in routine environments, but exhibit malicious behavior when the input contains a trigger. Current research on backdoor attacks focuses on improving the stealthiness of triggers, and most approaches require strong attacker capabilities, such as knowledge of the model structure or control over the training process. These attacks are impractical since in most cases the attacker's capabilities are limited. Additionally, the issue of model robustness has not received adequate attention. For instance, model distillation is commonly used to streamline model size as the number of parameters grows exponentially, and most of previous backdoor attacks failed after model distillation; the image augmentation operations can destroy the trigger and thus disable the backdoor. This study explores the implementation of black-box backdoor attacks within capability constraints. An attacker can carry out such attacks by acting as either an image annotator or an image provider, without involvement in the training process or knowledge of the target model's structure. Through the design of a backdoor trigger, our attack remains effective after model distillation and image augmentation, making it more threatening and practical. Our experimental results demonstrate that our method achieves a high attack success rate in black-box scenarios and evades state-of-the-art backdoor defenses.
翻译:暂无翻译