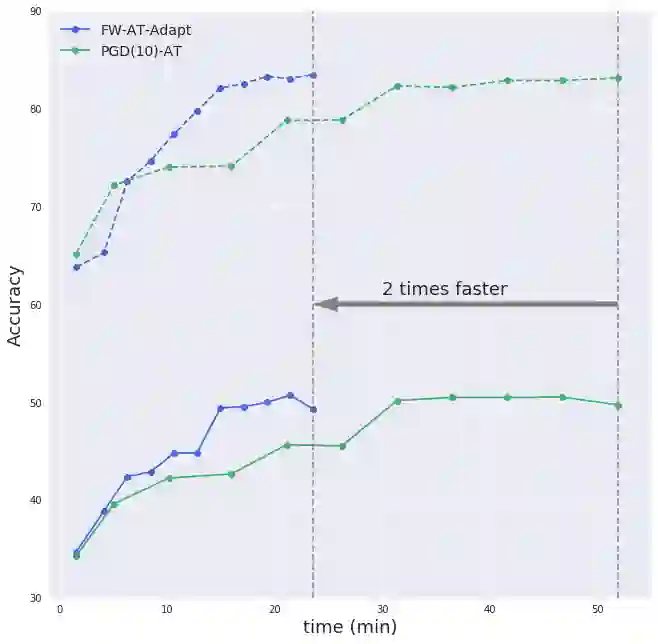
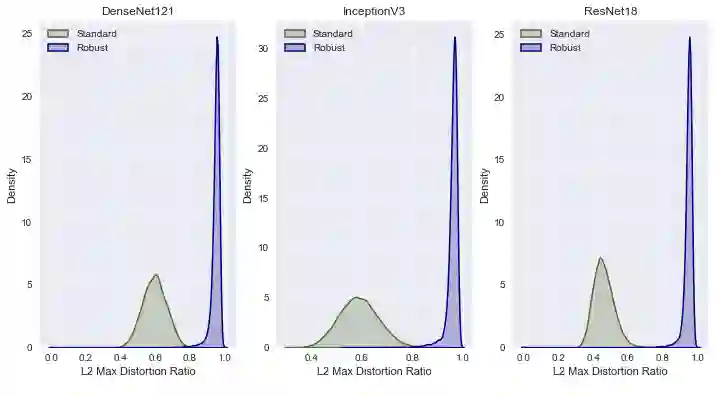
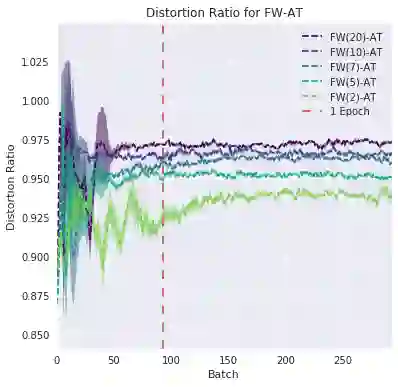
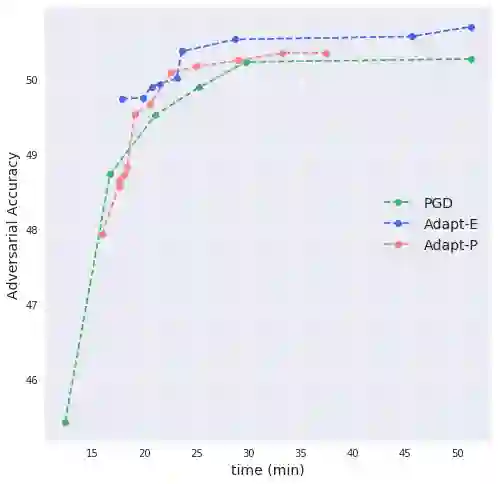
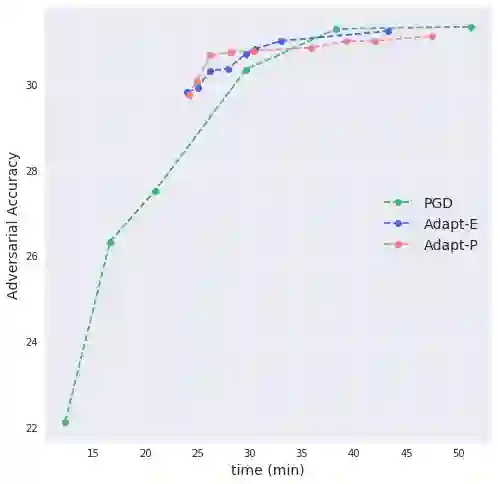
Deep neural networks are easily fooled by small perturbations known as adversarial attacks. Adversarial Training (AT) is a technique that approximately solves a robust optimization problem to minimize the worst-case loss and is widely regarded as the most effective defense against such attacks. We develop a theoretical framework for adversarial training with FW optimization (FW-AT) that reveals a geometric connection between the loss landscape and the distortion of $\ell_\infty$ FW attacks (the attack's $\ell_2$ norm). Specifically, we show that high distortion of FW attacks is equivalent to low variation along the attack path. It is then experimentally demonstrated on various deep neural network architectures that $\ell_\infty$ attacks against robust models achieve near maximal $\ell_2$ distortion. This mathematical transparency differentiates FW from the more popular Projected Gradient Descent (PGD) optimization. To demonstrate the utility of our theoretical framework we develop FW-Adapt, a novel adversarial training algorithm which uses simple distortion measure to adaptively change number of attack steps during training. FW-Adapt provides strong robustness at lower training times in comparison to PGD-AT for a variety of white-box and black-box attacks.
翻译:深心神经网络很容易被称为对抗性攻击的小扰动所蒙骗。 反向训练(AT)是一种技术,它大约能解决强力优化问题,以尽量减少最坏的损失,并被广泛视为对付这种攻击的最有效防御手段。 我们开发了一个理论性框架,用FW优化(FW-AT)进行对抗性训练,它揭示了损失地貌与FW攻击的扭曲之间的几何联系(攻击通常值$_ell_2美元)。具体地说,我们显示,对FW攻击的高度扭曲相当于攻击道路上的低变异。然后实验性地展示在各种深线性神经网络结构中,对强力模型的攻击几乎能达到最大值$\ell_2美元扭曲。这种数学透明度将FW与更受欢迎的预测的梯根(PGD)优化区别开来区分开来。 为了展示我们的理论性框架的效用,我们开发了FW-Adapt, 一种新型的对抗性训练算法,它使用简单的扭曲措施来适应性改变攻击步骤的次数。 FW-ADP-BAR在训练中提供了强力的对比。 在低时间里,在BARBAR(BARBAR)式攻击中提供强的精确攻击的比较。