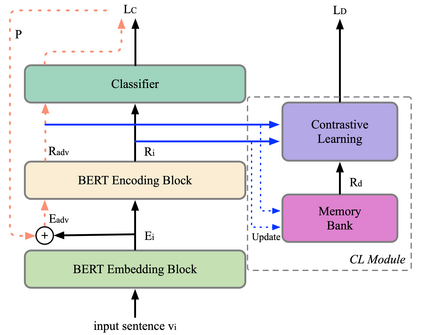
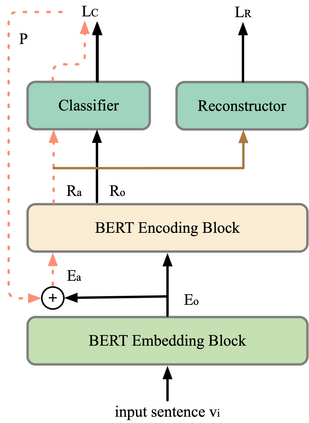
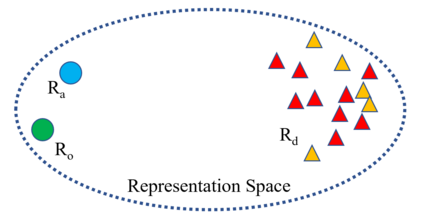
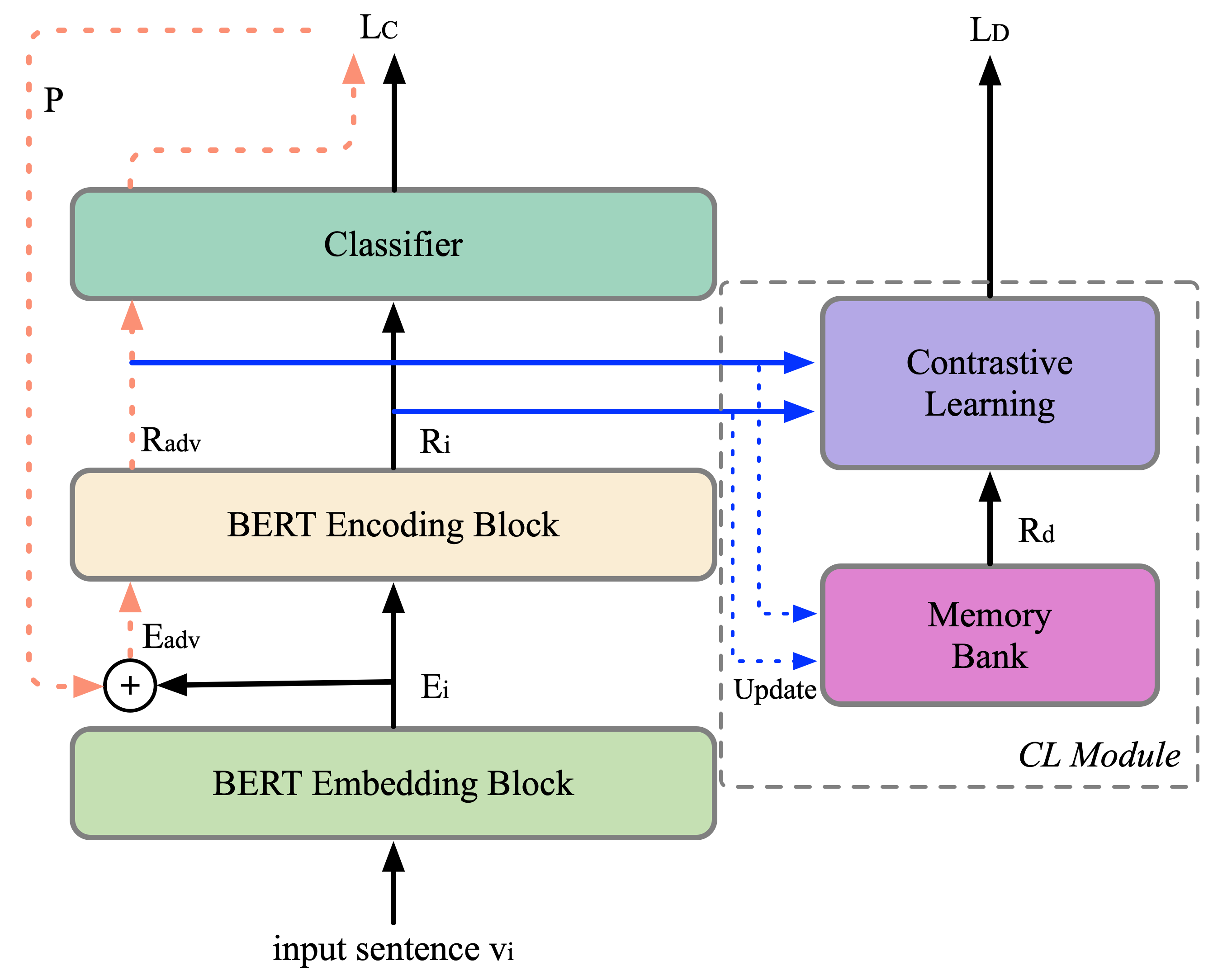
Recent work has proposed several efficient approaches for generating gradient-based adversarial perturbations on embeddings and proved that the model's performance and robustness can be improved when they are trained with these contaminated embeddings. While they paid little attention to how to help the model to learn these adversarial samples more efficiently. In this work, we focus on enhancing the model's ability to defend gradient-based adversarial attack during the model's training process and propose two novel adversarial training approaches: (1) CARL narrows the original sample and its adversarial sample in the representation space while enlarging their distance from different labeled samples. (2) RAR forces the model to reconstruct the original sample from its adversarial representation. Experiments show that the proposed two approaches outperform strong baselines on various text classification datasets. Analysis experiments find that when using our approaches, the semantic representation of the input sentence won't be significantly affected by adversarial perturbations, and the model's performance drops less under adversarial attack. That is to say, our approaches can effectively improve the robustness of the model. Besides, RAR can also be used to generate text-form adversarial samples.
翻译:最近的工作提出了几种有效的办法,以产生基于梯度的对立干扰嵌入器,并证明模型的性能和稳健性在经过这些受污染的嵌入器培训后可以提高。虽然它们很少注意如何帮助模型更有效地学习这些对立样本。在这项工作中,我们侧重于加强模型在模型培训过程中捍卫基于梯度的对立攻击的能力,并提出了两种新的对立培训办法:(1) CARL缩小了代表空间的原始样本及其对立样本,同时扩大了它们与不同标签样本的距离。(2) RAR将模型从对立样本中重建原始样本。实验表明,拟议的两种方法在各种文本分类数据集上都超过了强有力的基线。分析实验发现,在使用我们的方法时,输入句的语义表达不会受到对抗性攻击的严重影响,而模型的性能在对抗性攻击下下降较少。也就是说,我们的方法可以有效地改进模型的稳健性。此外,RAR还可以用来生成文本格式的对立样品。